FP-growth算法发现频繁项集——构建FP树
FP代表频繁模式(Frequent Pattern),算法主要分为两个步骤:FP-tree构建、挖掘频繁项集。
FP树表示法
FP树通过逐个读入事务,并把事务映射到FP树中的一条路径来构造。由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠。路径相互重叠越多,使用FP树结构获得的压缩效果越好;如果FP树足够小,能够存放在内存中,就可以直接从这个内存中的结构提取频繁项集,而不必重复地扫描存放在硬盘上的数据。
一颗FP树如下图所示:
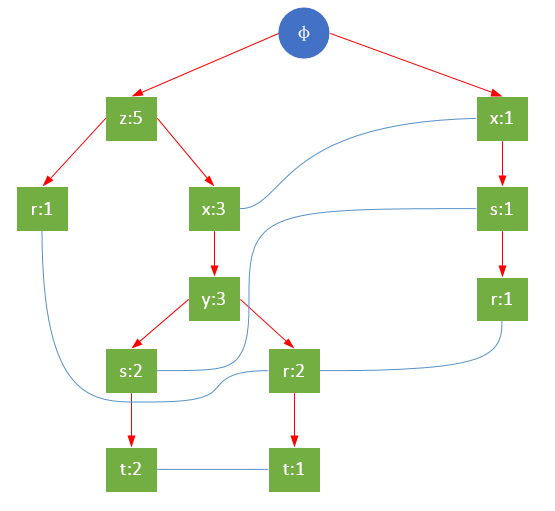
通常,FP树的大小比未压缩的数据小,因为数据的事务常常共享一些共同项,在最好的情况下,所有的事务都具有相同的项集,FP树只包含一条节点路径;当每个事务都具有唯一项集时,导致最坏情况发生,由于事务不包含任何共同项,FP树的大小实际上与原数据的大小一样。
FP树的根节点用φ表示,其余节点包括一个数据项和该数据项在本路径上的支持度;每条路径都是一条训练数据中满足最小支持度的数据项集;FP树还将所有相同项连接成链表,上图中用蓝色连线表示。
为了快速访问树中的相同项,还需要维护一个连接具有相同项的节点的指针列表(headTable),每个列表元素包括:数据项、该项的全局最小支持度、指向FP树中该项链表的表头的指针。
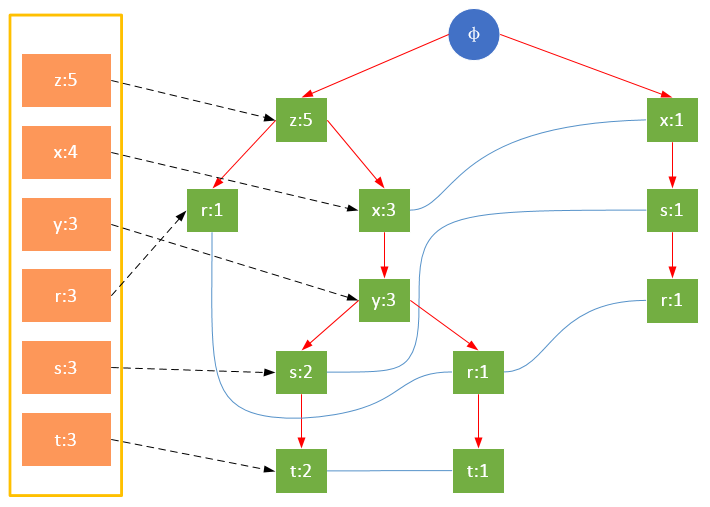
构建FP树
现在有如下数据:
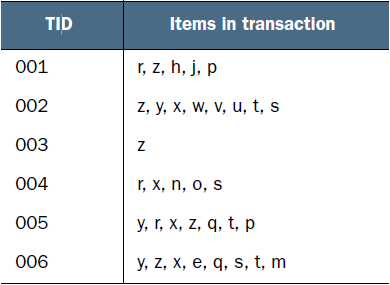
FP-growth算法需要对原始训练集扫描两遍以构建FP树。
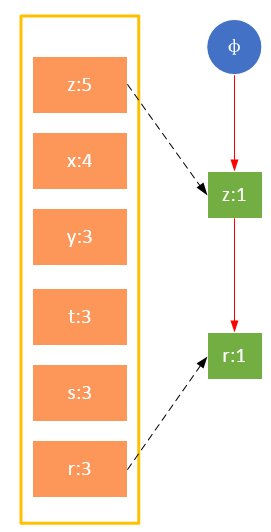
第一次扫描,过滤掉所有不满足最小支持度的项;对于满足最小支持度的项,按照全局最小支持度排序,在此基础上,为了处理方便,也可以按照项的关键字再次排序。

第一次扫描的后的结果
第二次扫描,构造FP树。
参与扫描的是过滤后的数据,如果某个数据项是第一次遇到,则创建该节点,并在headTable中添加一个指向该节点的指针;否则按路径找到该项对应的节点,修改节点信息。具体过程如下所示:
事务001,{z,x}
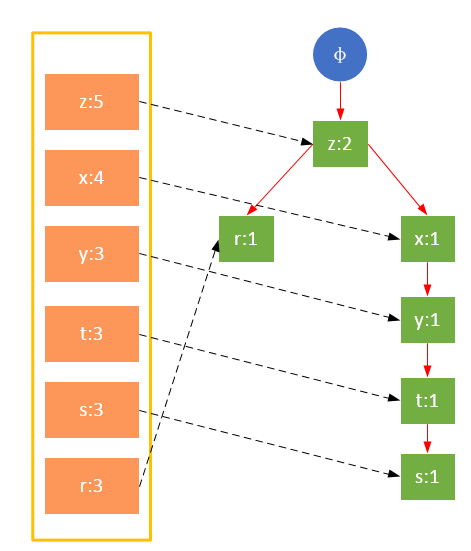
事务002,{z,x,y,t,s}
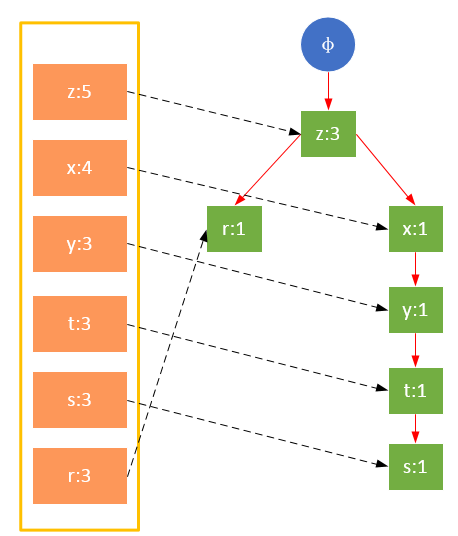
事务003,{z}
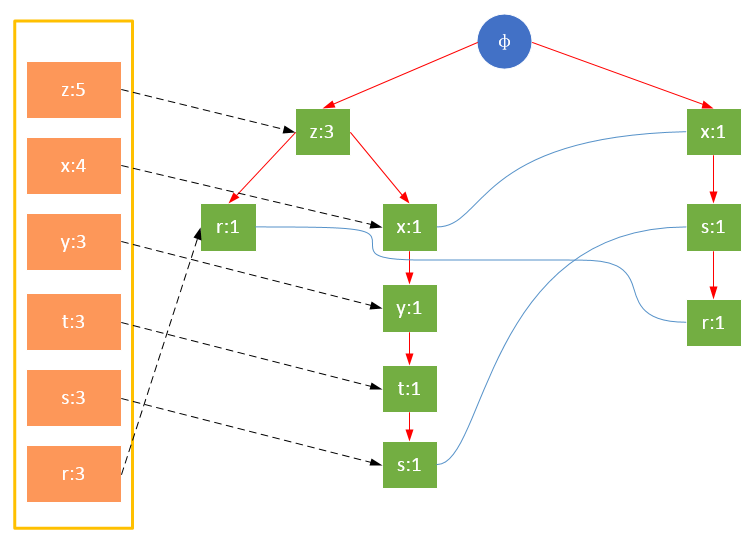
事务004,{x,s,r}
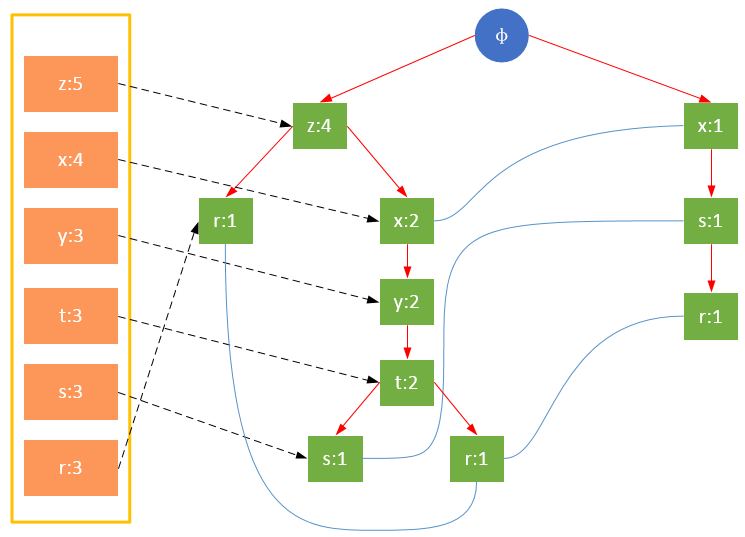
事务005,{z,x,y,t,r}
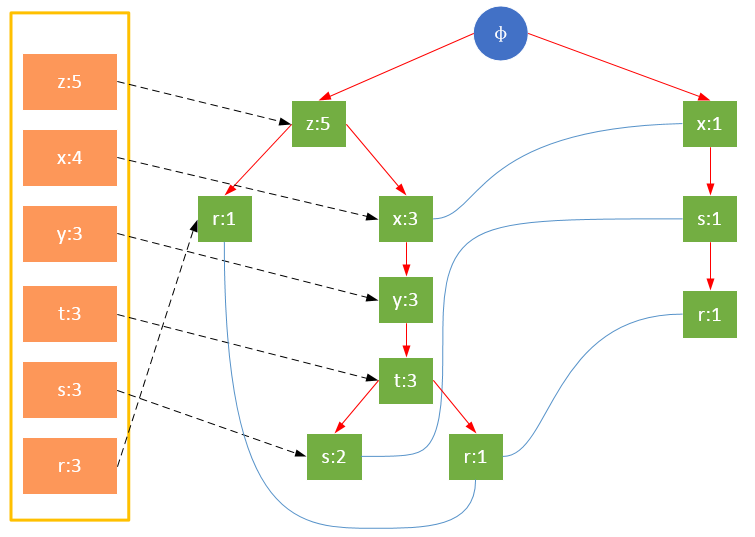
事务006,{z,x,y,t,s}
从上面可以看出,headTable并不是随着FPTree一起创建,而是在第一次扫描时就已经创建完毕,在创建FPTree时只需要将指针指向相应节点即可。从事务004开始,需要创建节点间的连接,使不同路径上的相同项连接成链表。
代码如下:
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
fset = frozenset(trans)
retDict.setdefault(fset, 0)
retDict[fset] += 1
return retDict
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' ' * ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
def createTree(dataSet, minSup=1):
headerTable = {}
#此一次遍历数据集, 记录每个数据项的支持度
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + 1
#根据最小支持度过滤
lessThanMinsup = list(filter(lambda k:headerTable[k] < minSup, headerTable.keys()))
for k in lessThanMinsup: del(headerTable[k])
freqItemSet = set(headerTable.keys())
#如果所有数据都不满足最小支持度,返回None, None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None]
retTree = treeNode('φ', 1, None)
#第二次遍历数据集,构建fp-tree
for tranSet, count in dataSet.items():
#根据最小支持度处理一条训练样本,key:样本中的一个样例,value:该样例的的全局支持度
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
#根据全局频繁项对每个事务中的数据进行排序,等价于 order by p[1] desc, p[0] desc
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: (p[1],p[0]), reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children: # check if orderedItems[0] in retTree.children
inTree.children[items[0]].inc(count) # incrament count
else: # add items[0] to inTree.children
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: # update header table
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1: # call updateTree() with remaining ordered items
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode): # this version does not use recursion
while (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
上面的代码在第一次扫描后并没有将每条训练数据过滤后的项排序,而是将排序放在了第二次扫描时,这可以简化代码的复杂度。
控制台信息:

项的顺序对FP树的影响
值得注意的是,对项的关键字排序将会影响FP树的结构。下面两图是相同训练集生成的FP树,图1除了按照最小支持度排序外,未对项做任何处理;图2则将项按照关键字进行了降序排序。树的结构也将影响后续发现频繁项的结果。
图1 未对项的关键字排序
图2 对项的关键字降序排序
总结
本派文章就到这里了,下篇继续,介绍如何发现频繁项集。希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
详解Java如何实现FP-Growth算法
FP-Growth算法的Java实现 这篇文章重点讲一下实现.需要两次扫描来构建FP树 第一次扫描 第一次扫描,过滤掉所有不满足最小支持度的项:对于满足最小支持度的项,按照全局支持度降序排序. 按照这个需求,可能的难点为如何按照全局支持度对每个事务中的item排序. 我的实现思路 扫描原数据集将其保存在二维列表sourceData中 维护一个Table,使其保存每个item的全局支持度TotalSup 在Table中过滤掉低于阈值minSup的项 将Table转换为List,并使其按照Total
-
分享Java常用几种加密算法(四种)
对称加密算法是应用较早的加密算法,技术成熟.在对称加密算法中,数据发信方将明文(原始数据)和加密密钥(mi yue)一起经过特殊加密算法处理后,使其变成复杂的加密密文发送出去.收信方收到密文后,若想解读原文,则需要使用加密用过的密钥及相同算法的逆算法对密文进行解密,才能使其恢复成可读明文.在对称加密算法中,使用的密钥只有一个,发收信双方都使用这个密钥对数据进行加密和解密,这就要求解密方事先必须知道加密密钥. 简单的java加密算法有: BASE 严格地说,属于编码格式,而非加密算法 MD(Mes
-

Java编程实现A*算法完整代码
前言 A*搜寻算法俗称A星算法.这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法.常用于游戏中 通过二维数组构建的一个迷宫,"%"表示墙壁,A为起点,B为终点,"#"代表障碍物,"*"代表算法计算后的路径 本文实例代码结构: % % % % % % % % o o o o o % % o o # o o % % A o # o B % % o o # o o % % o o o o o % % % % % % % % =======
-
python+pyqt5实现24点小游戏
本文实例为大家分享了python实现24点游戏的具体代码,供大家参考,具体内容如下 描述:一副牌中A.J.Q.K可以当成是1.11.12.13.任意抽取4张牌,用加.减.乘.除(可加括号)把牌面上的数算成24.每张牌对应的数字必须用一次且只能用一次.在规定时间内输入算式,输入正确加十分,输入错误生命值减一,点击确定提交并进入下一题,点击清空可清空算式.点击开始游戏进入游戏,可重新开始游戏. from PyQt5 import QtCore, QtWidgets from PyQt5.QtWidg
-
FP-Growth算法的Java实现+具体实现思路+代码
FP-Growth算法原理 其他大佬的讲解 FP-Growth算法详解 FP-Growth算法的Java实现 这篇文章重点讲一下实现.如果看了上述给的讲解,可知,需要两次扫描来构建FP树 第一次扫描 第一次扫描,过滤掉所有不满足最小支持度的项:对于满足最小支持度的项,按照全局支持度降序排序. 按照这个需求,可能的难点为如何按照全局支持度对每个事务中的item排序.我的实现思路 扫描原数据集将其保存在二维列表sourceData中 维护一个Table,使其保存每个item的全局支持度TotalSu
-
FP-growth算法发现频繁项集——构建FP树
FP代表频繁模式(Frequent Pattern),算法主要分为两个步骤:FP-tree构建.挖掘频繁项集. FP树表示法 FP树通过逐个读入事务,并把事务映射到FP树中的一条路径来构造.由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠.路径相互重叠越多,使用FP树结构获得的压缩效果越好:如果FP树足够小,能够存放在内存中,就可以直接从这个内存中的结构提取频繁项集,而不必重复地扫描存放在硬盘上的数据. 一颗FP树如下图所示: 通常,FP树的大小比未压缩的数据小,因为数据的事务常
-
FP-growth算法发现频繁项集——发现频繁项集
上篇介绍了如何构建FP树,FP树的每条路径都满足最小支持度,我们需要做的是在一条路径上寻找到更多的关联关系. 抽取条件模式基 首先从FP树头指针表中的单个频繁元素项开始.对于每一个元素项,获得其对应的条件模式基(conditional pattern base),单个元素项的条件模式基也就是元素项的关键字.条件模式基是以所查找元素项为结尾的路径集合.每一条路径其实都是一条前辍路径(perfix path).简而言之,一条前缀路径是介于所査找元素项与树根节点之间的所有内容. 下图是以{s:2}或{
-
数据结构与算法之并查集(不相交集合)
认识并查集 对于并查集(不相交集合),很多人会感到很陌生,没听过或者不是特别了解.实际上并查集是一种挺高效的数据结构.实现简单,只是所有元素统一遵从一个规律所以让办事情的效率高效起来. 对于定意义,百科上这么定义的: 并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受:即使在
-
vue基于Element构建自定义树的示例代码
说明 做项目的时候要使用到一个自定义的树形控件来构建表格树,在github上搜了一下没有搜索到合适的(好看的)可以直接用的,查看Element的组件说明时发现它的Tree控件可以使用render来自定义节点样式,于是基于它封装了一个可以增.删.改的树形组件,现在分享一下它的使用与实现. 控件演示 github上挂的gif可能会比较卡,有没有大佬知道还有哪里可以挂静态资源的,谢谢..! 控件使用 概要 基于element-ui树形控件的二次封装 提供编辑.删除节点的接口 提供一个next钩子,在业
-
Linux五步构建内核树
目录 0. 系统自带的内核树 1. 环境配置 第一步 第二步 2. 下载源码 3. 构建准备 4. 构建内核 5. 安装模块 总结 0. 系统自带的内核树 有时,安装的系统已经自带了Linux内核树,足够用来编译驱动程序了. 自带的内核树通常位于 /lib/modules/<系统内核版本>/build 其中,系统内核版本可以用uname -r来查看 $ uname -r 5.11.0-41-generic 不过自带的内核树似乎不完整,所以建议按照下面的方法编译一个完整的内核树. 1. 环境配置
-
使用JS动态构建目录树
在使用frameset布局的时候,经常会用到目录树,我们可以把一棵树写死,但是更多的情况是,这棵树需要随时被改动,所以我们期望的是他能够被动态的构建. MVC,算是了解一点,那本文就把这棵树根据M-V-C给拆开分解吧. 下面就来看看这棵树是怎么构建的. Module [数据层] var tree = { "id": 0, "a1": { "id": 1, "name": "a1", "childr
-
算法系列15天速成 第十二天 树操作【中】
先前说了树的基本操作,我们采用的是二叉链表来保存树形结构,当然二叉有二叉的困扰之处,比如我想找到当前结点的"前驱"和"后继",那么我们就必须要遍历一下树,然后才能定位到该"节点"的"前驱"和"后继",每次定位都是O(n),这不是我们想看到的,那么有什么办法来解决呢? (1) 在节点域中增加二个指针域,分别保存"前驱"和"后继",那么就是四叉链表了,哈哈,还是有点浪费空
-
python使用Apriori算法进行关联性解析
从大规模数据集中寻找物品间的隐含关系被称作关联分析或关联规则学习.过程分为两步:1.提取频繁项集.2.从频繁项集中抽取出关联规则. 频繁项集是指经常出现在一块的物品的集合. 关联规则是暗示两种物品之间可能存在很强的关系. 一个项集的支持度被定义为数据集中包含该项集的记录所占的比例,用来表示项集的频繁程度.支持度定义在项集上. 可信度或置信度是针对一条诸如{尿布}->{葡萄酒}的关联规则来定义的.这条规则的可信度被定义为"支持度({尿布,葡萄酒})/支持度({尿布})". 寻找频繁
-
python数据挖掘Apriori算法实现关联分析
目录 摘要: 关联分析 Apriori原理 算法实现 挖掘关联规则 利用Apriori算法解决实际问题 发现毒蘑菇的相似特征 总结: 摘要: 主要是讲解一些数据挖掘中频繁模式挖掘的Apriori算法原理应用实践 当我们买东西的时候,我们会发现物品展示方式是不同,购物以后优惠券以及用户忠诚度也是不同的,但是这些来源都是大量数据的分析,为了从顾客身上获得尽可能多的利润,所以需要用各种技术来达到目的. 通过查看哪些商品一起购物可以帮助商店了解客户的购买行为.这种从大规模数据集中寻找物品间的隐含关系被称
-
python中Apriori算法实现讲解
本文主要给大家讲解了Apriori算法的基础知识以及Apriori算法python中的实现过程,以下是所有内容: 1. Apriori算法简介 Apriori算法是挖掘布尔关联规则频繁项集的算法.Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集.先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描.注意:频繁项集的所有非空