Python过滤txt文件内重复内容的方法
Python过滤txt文件内重复内容,并将过滤后的内容保存到新的txt中
示例如下
原文件
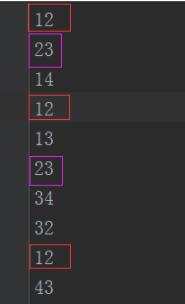
处理之后的文件
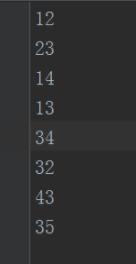
直接上代码
# -*-coding:utf-8 -*-
f = open("1.txt", "rb")
n = f.read()
f.close()
m = n.split("\r\n")
print "m=",m
print m[1]
m1 = []
for i in xrange(len(m)):
if not m[i] in m1:
m1.append(m[i])
print "m1=", m1
filename = open("1.0.txt", "wb")
for i in xrange(len(m1)):
filename.write(m1[i]+"\n")
可看到结果

以上这篇Python过滤txt文件内重复内容的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python3 实现随机生成一组不重复数并按行写入文件
笔主在做一个项目要生成一组随机有序的整型数字,并按行输出到文本文件使用,恰好开始学习Python3,遂决定直接使用Python3解决 思路:与随机数相关的函数都要使用到random这个系统库,查看相关的开发文档发现random库下面有个sample(seq,n)函数比较符合,能在在一个序列中随机选择n个不重复的数,并返回一个list,接下来就是将一个list按行输出到一个文本文件中 过程: 1.导入random库 import random 2.生成一个自己自己想要的范围的序列,笔者是需要在1-
-
python 高效去重复 支持GB级别大文件的示例代码
如下所示: #coding=utf-8 import sys, re, os def getDictList(dict): regx = '''[\w\~`\!\@\#\$\%\^\&\*\(\)\_\-\+\=\[\]\{\}\:\;\,\.\/\<\>\?]+''' with open(dict) as f: data = f.read() return re.findall(regx, data) def rmdp(dictList): return list(set(dictL
-
对python读写文件去重、RE、set的使用详解
如下所示: # -*- coding:utf-8 -*- from datetime import datetime import re def Main(): sourcr_dir = '/data/u_lx_data/fudan/muying/muying_11yue_all.txt' target_dir = '/data/u_lx_data/fudan/muying/python/uid_regular_get.txt' uset = set() #去重 print("开始.....&q
-
Python实现对文件进行单词划分并去重排序操作示例
本文实例讲述了Python实现对文件进行单词划分并去重排序操作.分享给大家供大家参考,具体如下: 文件名:test1.txt 文件内容: But soft what light through yonder window breaks It is the east and Juliet is the sun Arise fair sun and kill the envious moon Who is already sick and pale with grief 样例输出: Enter fi
-
Python统计文件中去重后uuid个数的方法
本文实例讲述了Python统计文件中去重后uuid个数的方法.分享给大家供大家参考.具体如下: 利用正则表达式按行获取日志文件中的的uuid,并且统计这些uuid的去重个数(去重利用set) import re pattern=re.compile(r'&uuid=.*&') uuidset=set() with open('request.log.2015-05-26','rt') as f: for line in f: all=pattern.findall(line) if len
-
python批量查询、汉字去重处理CSV文件
CSV文件用记事本打开后一般为由逗号隔开的字符串,其处理方法用Python的代码如下.为方便各种程度的人阅读在代码中有非常详细的注释. 1.查询指定列,并保存到新的csv文件. # -*- coding: utf-8 -*- ''''' Author: Good_Night Time: 2018/1/30 03:50 Edition: 1.0 ''' # 导入必须的csv库 import csv # 创建临时文件temp.csv找出所需要的列 temp_file = open("temp.csv
-
python删除本地夹里重复文件的方法
上次的博文主要说了从网上下载图片,于是我把整个笑话网站的图片都拔下来了,但是在拔取的图片中有很多重复的,比如说页面的其他图片.重复发布的图片等等.所以我又找了python的一些方法,写了一个脚本可以删除指定文件夹里重复的图片. 一.方法和思路 1.比对文件是否相同的方法:hashlib库里提供了获取文件md5值的方法,所以我们可以通过md5值来判定是否图片相同 2.对文件的操作:os库里有对文件的操作方法,比如:os.remove()可以删除指定的文件, os.listdir()可以通过指定文件
-

Python实现的删除重复文件或图片功能示例【去重】
本文实例讲述了Python实现的删除重复文件或图片功能.分享给大家供大家参考,具体如下: 通过python爬虫或其他方式保存的图片文件通常包含一些重复的图片或文件, 通过下面的python代码可以将重复的文件删除以达到去重的目的.其中,文件目录结构如下图: # /usr/bin/env python # -*- coding:utf-8 -*- # 运行的代码文件要放到删除重复的文件或图片所包含的目录中 import os import hashlib def filecount(): file
-
Python实现的txt文件去重功能示例
本文实例讲述了Python实现的txt文件去重功能.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #! python2 import shutil a=0 readDir = "/Users/Administrator/Desktop/old.txt" #old writeDir = "/Users/Administrator/Desktop/new.txt" #new # txtDir = "/home/Administ
-
python去除文件中重复的行实例
python去除文件中重复的行,我们可以设置一个一个空list,res_list,用来加入没有出现过的字符行! 如果出现在res_list,我们就认为该行句子已经重复了,可以再加入到记录重复句子的list中. 如下代码: # -*- coding: UTF-8 -*- #程序功能是为了完成判断文件中是否有重复句子 #并将重复句子打印出来 res_list = [] #f = open('F:/master/master-work/code_of_graduate/LTP_data/raw_pla