Redis缓存空间优化实践详解
目录
- 导读
- 场景设定
- 常规做法
- 改进1-去掉属性名
- 改进2-使用更好的序列化工具
- 改进3-优化数据类型
- 改进4-考虑ZIP压缩
- 最终落地
- 场景延伸
导读
缓存Redis,是我们最常用的服务,其适用场景广泛,被大量应用到各业务场景中。也正因如此,缓存成为了重要的硬件成本来源,我们有必要从空间上做一些优化,降低成本的同时也会提高性能。
下面以我们的案例说明,将缓存空间减少70%的做法。
场景设定
1、我们需要将POJO存储到缓存中,该类定义如下
public class TestPOJO implements Serializable {
private String testStatus;
private String userPin;
private String investor;
private Date testQueryTime;
private Date createTime;
private String bizInfo;
private Date otherTime;
private BigDecimal userAmount;
private BigDecimal userRate;
private BigDecimal applyAmount;
private String type;
private String checkTime;
private String preTestStatus;
public Object[] toValueArray(){
Object[] array = {testStatus, userPin, investor, testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, checkTime, preTestStatus};
return array;
}
public CreditRecord fromValueArray(Object[] valueArray){
//具体的数据类型会丢失,需要做处理
}
}
2、用下面的实例作为测试数据
TestPOJO pojo = new TestPOJO();
pojo.setApplyAmount(new BigDecimal("200.11"));
pojo.setBizInfo("XX");
pojo.setUserAmount(new BigDecimal("1000.00"));
pojo.setTestStatus("SUCCESS");
pojo.setCheckTime("2023-02-02");
pojo.setInvestor("ABCD");
pojo.setUserRate(new BigDecimal("0.002"));
pojo.setTestQueryTime(new Date());
pojo.setOtherTime(new Date());
pojo.setPreTestStatus("PROCESSING");
pojo.setUserPin("ABCDEFGHIJ");
pojo.setType("Y");
常规做法
System.out.println(JSON.toJSONString(pojo).length());
使用JSON直接序列化、打印 length=284**,**这种方式是最简单的方式,也是最常用的方式,具体数据如下:
{"applyAmount":200.11,"bizInfo":"XX","checkTime":"2023-02-02","investor":"ABCD","otherTime":"2023-04-10 17:45:17.717","preCheckStatus":"PROCESSING","testQueryTime":"2023-04-10 17:45:17.717","testStatus":"SUCCESS","type":"Y","userAmount":1000.00,"userPin":"ABCDEFGHIJ","userRate":0.002}
我们发现,以上包含了大量无用的数据,其中属性名是没有必要存储的。
改进1-去掉属性名
System.out.println(JSON.toJSONString(pojo.toValueArray()).length());
通过选择数组结构代替对象结构,去掉了属性名,打印 length=144,将数据大小降低了50%,具体数据如下:
["SUCCESS","ABCDEFGHIJ","ABCD","2023-04-10 17:45:17.717",null,"XX","2023-04-10 17:45:17.717",1000.00,0.002,200.11,"Y","2023-02-02","PROCESSING"]
我们发现,null是没有必要存储的,时间的格式被序列化为字符串,不合理的序列化结果,导致了数据的膨胀,所以我们应该选用更好的序列化工具。
改进2-使用更好的序列化工具
//我们仍然选取JSON格式,但使用了第三方序列化工具 System.out.println(new ObjectMapper(new MessagePackFactory()).writeValueAsBytes(pojo.toValueArray()).length);
选取更好的序列化工具,实现字段的压缩和合理的数据格式,打印 **length=92,**空间比上一步又降低了40%。
这是一份二进制数据,需要以二进制操作Redis,将二进制转为字符串后,打印如下:
��SUCCESS�ABCDEFGHIJ�ABCD��j�6���XX��j�6����?`bM����@i��Q�Y�2023-02-02�PROCESSING
顺着这个思路再深挖,我们发现,可以通过手动选择数据类型,实现更极致的优化效果,选择使用更小的数据类型,会获得进一步的提升。
改进3-优化数据类型
在以上用例中,testStatus、preCheckStatus、investor这3个字段,实际上是枚举字符串类型,如果能够使用更简单数据类型(比如byte或者int等)替代string,还可以进一步节省空间。其中checkTime可以用Long类型替代字符串,会被序列化工具输出更少的字节。
public Object[] toValueArray(){
Object[] array = {toInt(testStatus), userPin, toInt(investor), testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, toLong(checkTime), toInt(preTestStatus)};
return array;
}
在手动调整后,使用了更小的数据类型替代了String类型,打印 length=69
改进4-考虑ZIP压缩
除了以上的几点之外,还可以考虑使用ZIP压缩方式获取更小的体积,在内容较大或重复性较多的情况下,ZIP压缩的效果明显,如果存储的内容是TestPOJO的数组,可能适合使用ZIP压缩。
但ZIP压缩并不一定会减少体积,在小于30个字节的情况下,也许还会增加体积。在重复性内容较少的情况下,无法获得明显提升。并且存在CPU开销。
在经过以上优化之后,ZIP压缩不再是必选项,需要根据实际数据做测试才能分辨到ZIP的压缩效果。
最终落地
上面的几个改进步骤体现了优化的思路,但是反序列化的过程会导致类型的丢失,处理起来比较繁琐,所以我们还需要考虑反序列化的问题。
在缓存对象被预定义的情况下,我们完全可以手动处理每个字段,所以在实战中,推荐使用手动序列化达到上述目的,实现精细化的控制,达到最好的压缩效果和最小的性能开销。
可以参考以下msgpack的实现代码,以下为测试代码,请自行封装更好的Packer和UnPacker等工具:
<dependency>
<groupId>org.msgpack</groupId>
<artifactId>msgpack-core</artifactId>
<version>0.9.3</version>
</dependency>
public byte[] toByteArray() throws Exception {
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker();
toByteArray(packer);
packer.close();
return packer.toByteArray();
}
public void toByteArray(MessageBufferPacker packer) throws Exception {
if (testStatus == null) {
packer.packNil();
}else{
packer.packString(testStatus);
}
if (userPin == null) {
packer.packNil();
}else{
packer.packString(userPin);
}
if (investor == null) {
packer.packNil();
}else{
packer.packString(investor);
}
if (testQueryTime == null) {
packer.packNil();
}else{
packer.packLong(testQueryTime.getTime());
}
if (createTime == null) {
packer.packNil();
}else{
packer.packLong(createTime.getTime());
}
if (bizInfo == null) {
packer.packNil();
}else{
packer.packString(bizInfo);
}
if (otherTime == null) {
packer.packNil();
}else{
packer.packLong(otherTime.getTime());
}
if (userAmount == null) {
packer.packNil();
}else{
packer.packString(userAmount.toString());
}
if (userRate == null) {
packer.packNil();
}else{
packer.packString(userRate.toString());
}
if (applyAmount == null) {
packer.packNil();
}else{
packer.packString(applyAmount.toString());
}
if (type == null) {
packer.packNil();
}else{
packer.packString(type);
}
if (checkTime == null) {
packer.packNil();
}else{
packer.packString(checkTime);
}
if (preTestStatus == null) {
packer.packNil();
}else{
packer.packString(preTestStatus);
}
}
public void fromByteArray(byte[] byteArray) throws Exception {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(byteArray);
fromByteArray(unpacker);
unpacker.close();
}
public void fromByteArray(MessageUnpacker unpacker) throws Exception {
if (!unpacker.tryUnpackNil()){
this.setTestStatus(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setUserPin(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setInvestor(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setTestQueryTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setCreateTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setBizInfo(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setOtherTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setUserAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setUserRate(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setApplyAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setType(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setCheckTime(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setPreTestStatus(unpacker.unpackString());
}
}
场景延伸
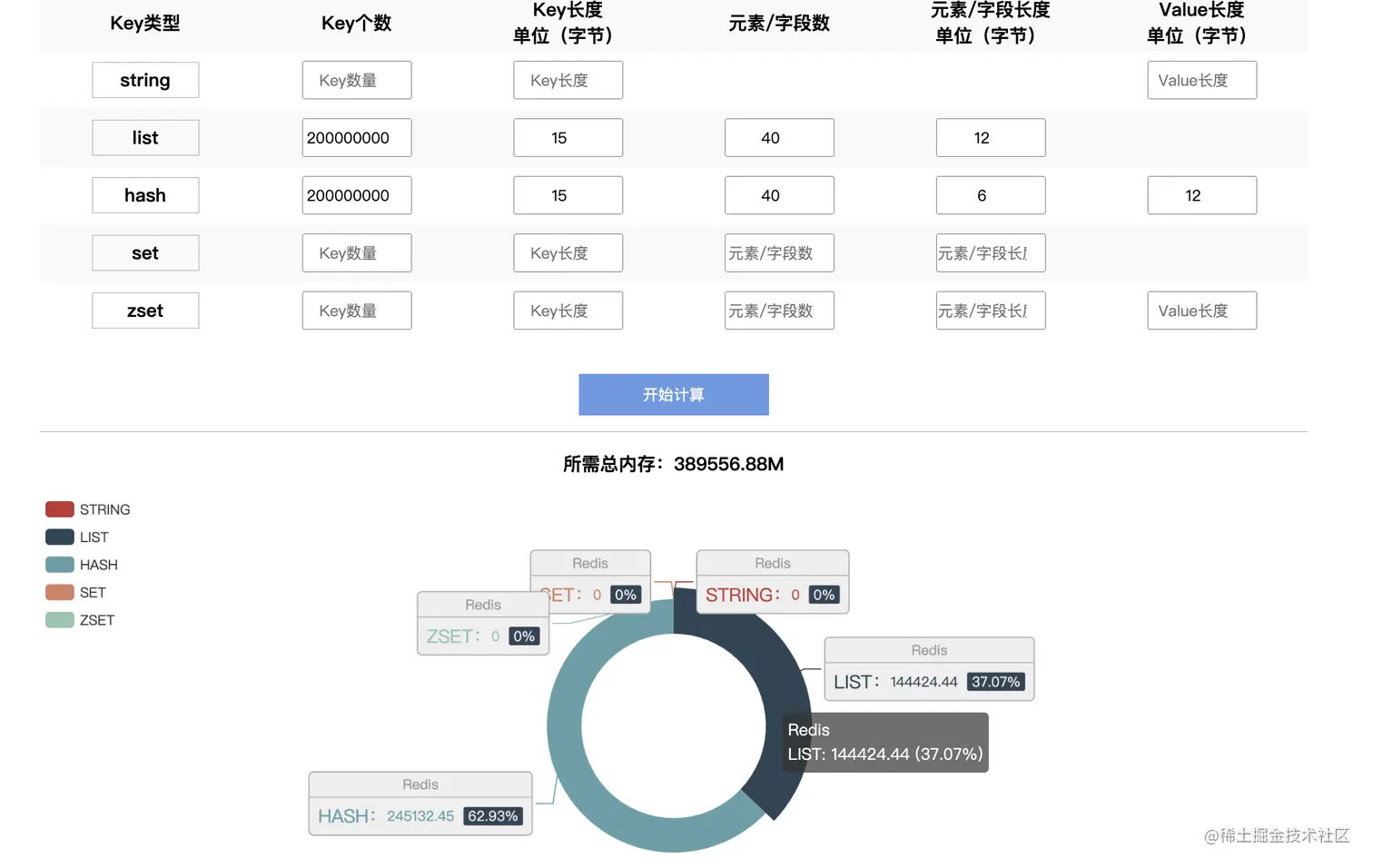
假设,我们为2亿用户存储数据,每个用户包含40个字段,字段key的长度是6个字节,字段是分别管理的。
正常情况下,我们会想到hash结构,而hash结构存储了key的信息,会占用额外资源,字段key属于不必要数据,按照上述思路,可以使用list替代hash结构。
通过Redis官方工具测试,使用list结构需要144G的空间,而使用hash结构需要245G的空间**(当50%以上的属性为空时,需要进行测试,是否仍然适用)**
在以上案例中,我们采取了几个非常简单的措施,仅仅有几行简单的代码,可降低空间70%以上,在数据量较大以及性能要求较高的场景中,是非常值得推荐的。:
• 使用数组替代对象(如果大量字段为空,需配合序列化工具对null进行压缩)
• 使用更好的序列化工具
• 使用更小的数据类型
• 考虑使用ZIP压缩
• 使用list替代hash结构(如果大量字段为空,需要进行测试对比)
以上就是Redis缓存空间优化实践的详细内容,更多关于Redis缓存空间优化的资料请关注我们其它相关文章!
相关推荐
-

Redis进行相关优化详解
目录 前言 内存维度 控制key的长度 避免存储bigkey 如何查询bigkey 选择合适的数据类型 采用高效的序列化和压缩方法 设置Redis最大内存和淘汰策略 控制Redis实例的大小 定时清除内存碎片 性能维度 禁止使用KEYS.FLUSHALL.FLUSHDB命令 优化建议 慎用全量操作的命令 慎用复杂度过高命令 设置合适的过期时间 采用批量命令代替个命令 Pipeline具体使用: 高可用维度 按照业务部署不同的实例 避免单点问题 合理的设置相关参数 总结 前言 Redis在项目中进
-
Redis缓存的主要异常及解决方案实例
目录 1 导读 2 异常类型 2.1 缓存雪崩 2.1.1 现象 2.1.2 异常原因 2.1.3 解决方案 2.2 缓存穿透 2.2.1 现象 2.2.2 异常原因 2.2.3 解决方案 2.3 缓存击穿 2.3.1 现象 2.3.2 异常原因 2.3.3 解决方案 3 总结 1 导读 Redis 是当前最流行的 NoSQL数据库.Redis主要用来做缓存使用,在提高数据查询效率.保护数据库等方面起到了关键性的作用,很大程度上提高系统的性能.当然在使用过程中,也会出现一些异常情景,导致Redi
-
使用Redis缓存时高效的批量删除的几种方案
目录 前因后果 批量删除redis数据方法 利用的是Linux的xargs命令 xargs指令 命令格式 参数: 使用Lua脚本删除百万/千万级的key Lua脚本是什么? Lua脚本的指令格式 Lua脚本执行参数 Lua获取传参数据 示例 Lua脚本的案例(keys) scan介绍 Lua脚本的案例(scan) 前因后果 之前我们的服务,在上线的时候发现有一些大Key的使用不是很规范,特别是没有设置过期时间,因此导致redis中内存的数据越来越多,目前Redis节点的内存已经快撑不住了.所以根
-
SpringBoot整合Redis实现热点数据缓存的示例代码
我们以IDEA + SpringBoot作为 Java中整合Redis的使用 的测试环境 首先,我们需要导入Redis的maven依赖 <!-- Redis的maven依赖包 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependenc
-
Redis优化经验总结(必看篇)
内存管理优化 Redis Hash是value内部为一个HashMap,如果该Map的成员数比较少,则会采用类似一维线性的紧凑格式来存储该Map, 即省去了大量指针的内存开销,这个参数控制对应在redis.conf配置文件中下面2项: hash-max-zipmap-entries 64 hash-max-zipmap-value 512 当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,即value内部有64个以下的成员就是使用线性紧凑存储,超过该值
-
Laravel操作redis和缓存操作详解
目录 一:操作redis 1:redis拓展安装 2:配置redis 3:操作redis 二:缓存操作 1:缓存配置 2:缓存操作 一:操作redis 1:redis拓展安装 composer require predis/predis 或者你也可以通过 PECL 安装 PhpRedis PHP 扩展,安装方法比较复杂,个人不推荐 2:配置redis 在config/database.php文件中配置redis (1):单个redis配置 'redis' => [ 'client' => en
-
GitLab使用外部提供的Redis缓存数据库的方法详解
缺省的情况下GitLab的官方镜像中提供了一个Redis,如果希望把此缓存数据库放在GitLab的容器之外的话需要怎么做呢?这篇文章结合示例进行说明具体的做法. 环境准备 配置文件:GitLab version: '2' services: # Version Control service: Gitlab gitlab: image: gitlab/gitlab-ce:12.10.5-ce.0 ports: - "35001:80" - "30022:22" -
-
记一次vue-webpack项目优化实践详解
项目现状 项目是一个数据监测平台,引入了ehcart和three.js 负责项目的数据可视化:打包后,体积高达2.1M,这个体积相比于我的项目规模来说就显得稍有笨重了 使用webpack-bundle-analyzer分析了一下各个文件所占用的比例: 整个项目文件分布大体清晰了,现在开始优化走起! 优化思路 根据 wba的显示,第三方插件是大部头,包括three.js echart组件和elementUI组件. three.js优化空间不大,主要关注另外两个上面. echarts 根据我的项目需
-
Apache Pulsar 微信大流量实时推荐场景下实践详解
目录 导语 作者简介 实践 1:大流量场景下的 K8s 部署实践 实践 2:非持久化 Topic 的应用 实践 3:负载均衡与 Broker 缓存优化 实践 4:COS Offloader 开发与应用 未来展望与计划 导语 本文整理自 8 月 Apache Pulsar Meetup 上,刘燊题为<Apache Pulsar 在微信的大流量实时推荐场景实践>的分享.本文介绍了微信团队在大流量场景下将 Pulsar 部署在 K8s 上的实践与优化.非持久化 Topic 的应用.负载均衡与 Bro
-
React 首页加载慢问题性能优化案例详解
学习了一段时间React,想真实的实践一下.于是便把我的个人博客网站进行了重构.花了大概一周多时间,网站倒是重构的比较成功,但是一上线啊,那个访问速度啊,是真心慢,慢到自己都不能忍受,那么小一个网站,没几篇文章,慢成那样,不能接受.我不是一个追求完美的人,但这样可不行.后面大概花了一点时间进行性能的研究.才发现慢是有原因的. React这类框架? 目前主流的前端框架React.Vue.Angular都是采用客户端渲染(服务端渲染暂时不在本文的考虑范围内).这当然极大的减轻了服务器的压力.相对的浏
-
redis protocol通信协议及使用详解
目录 简介 redis的高级用法 Redis中的pipline Redis中的Pub/Sub RESP protocol Simple Strings Bulk Strings RESP Integers RESP Arrays RESP Errors Inline commands 总结 简介 redis是一个非常优秀的软件,它可以用作内存数据库或者缓存.因为他的优秀性能,redis被应用在很多场合中. redis是一个客户端和服务器端的模式,客户端和服务器端是通过TCP协议进行连接的,客户端
-
redis配置文件中常用配置详解
此次安装的版本为: 5.0.3 [root@localhost local]# redis-server --version Redis server v=5.0.3 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=afabdecde61000c3 打开redis.cof NETWORK # 指定 redis 只接收来自于该IP地址的请求,如果不进行设置,那么将处理所有请求 bind 127.0.0.1 #是否开启保护模式,默认开启.要是配置
-
Redis RDB技术底层原理详解
每日一句 低头是一种能力,它不是自卑,也不是怯弱,它是清醒中的嬗变.有时,稍微低一下头,或者我们的人生路会更精彩. 前提概要 Redis是一个的键-值(K-V)对的内存数据库服务,通常包含了任意个非空数据库.而每个非空的键值数据库中又可以存放任意个K-V,基本的结构如下图所示: Redis的强劲性能很大程度上是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中以某种形式同步到硬盘中,这一过程就是持久化. 我们知道redis中缓存的数据都存放在内存中
-
Tomcat用户管理的优化配置详解
目录 tomcat用户管理配置 tomcat优化 一.tomcat中的三种运行模式之运行模式的优化 二.tomcat执行器(线程池)的优化 三.tomcat优化之禁用AJP连接器实现动静分离 四.tomcat中JVM参数优化 tomcat用户管理配置 在tomcat-users.xml中添加用户: <role rolename="manager"/> <role rolename="manager-gui"/> <role rolena
-
Redis集群的相关详解
注意!要求使用的都是redis3.0以上的版本,因为3.0以上增加了redis集群的功能. 1.redis介绍 1.1什么是redis Redis是用C语言开发的一个开源的高性能键值对(key-value)的非关系型数据库.通过多种键值数据类型来适应不同场景下的存储需求,目前支持的键值数据类型有: 字符串,散列,列表,集合,有序集合 2.2应用场景 缓存(数据查询.短连接.新闻内容.商品内容等等).(最多使用) 分布式集群架构中的session分离. 聊天室的在线好友列表. 任务队列.(秒杀.抢
-
MySQL索引优化Explain详解
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看.所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用. -- 实际SQL,查找用户名为Jefabc的员工 select * from