Queue队列中join()与task_done()的关系及说明
目录
- join()与task_done()的关系
- 理解
- 快速生产-快速消费
- 慢速生产-快速消费
- 注意点
- 总结
join()与task_done()的关系
在网上大多关于join()与task_done()的结束原话是这样的:
Queue.task_done()在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号Queue.join()实际上意味着等到队列为空,再执行别的操作
但是可能很多人还是不太理解,这里以我自己的理解来阐述这两者的关联。
理解
如果线程里每从队列里取一次,但没有执行task_done(),则join无法判断队列到底有没有结束,在最后执行个join()是等不到结果的,会一直挂起。
可以理解为,每task_done一次 就从队列里删掉一个元素,这样在最后join的时候根据队列长度是否为零来判断队列是否结束,从而执行主线程。
下面看个自己写的例子:
下面这个例子,会在join()的地方无限挂起,因为join在等队列清空,但是由于没有task_done,它认为队列还没有清空,还在一直等。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''threading test'''
import threading
import queue
from time import sleep
#之所以为什么要用线程,因为线程可以start后继续执行后面的主线程,可以put数据,如果不是线程直接在get阻塞。
class Mythread(threading.Thread):
def __init__(self,que):
threading.Thread.__init__(self)
self.queue = que
def run(self):
while True:
sleep(1)
if self.queue.empty(): #判断放到get前面,这样可以,否则队列最后一个取完后就空了,直接break,走不到print
break
item = self.queue.get()
print(item,'!')
#self.queue.task_done()
return
que = queue.Queue()
tasks = [Mythread(que) for x in range(1)]
for x in range(10):
que.put(x) #快速生产
for x in tasks:
t = Mythread(que) #把同一个队列传入2个线程
t.start()
que.join()
print('---success---')
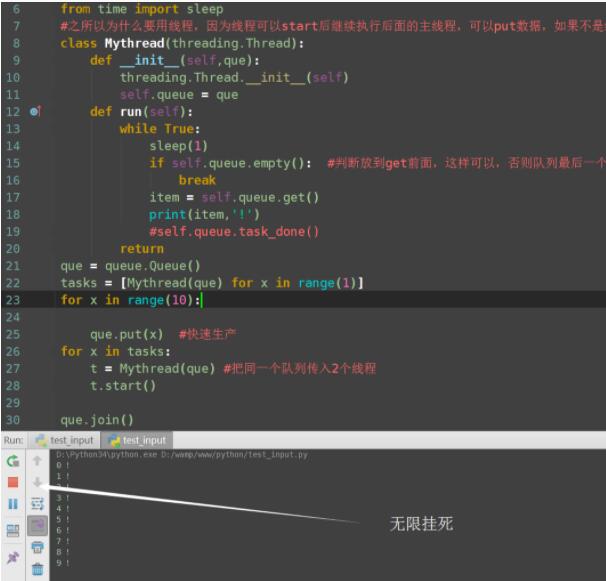
如果把self.queue.task_done() 注释去掉,就会顺利执行完主程序。
这就是“ Queue.task_done()函数向任务已经完成的队列发送一个信号”这句话的意义,能够让join()函数能判断出队列还剩多少,是否清空了。
而事实上我们看下queue的源码可以看出确实是执行一次未完成队列减一:
def task_done(self):
'''Indicate that a formerly enqueued task is complete.
Used by Queue consumer threads. For each get() used to fetch a task,
a subsequent call to task_done() tells the queue that the processing
on the task is complete.
If a join() is currently blocking, it will resume when all items
have been processed (meaning that a task_done() call was received
for every item that had been put() into the queue).
Raises a ValueError if called more times than there were items
placed in the queue.
'''
with self.all_tasks_done:
unfinished = self.unfinished_tasks - 1
if unfinished <= 0:
if unfinished < 0:
raise ValueError('task_done() called too many times')
self.all_tasks_done.notify_all()
self.unfinished_tasks = unfinished
快速生产-快速消费
上面的演示代码是快速生产-慢速消费的场景,我们可以直接用task_done()与join()配合,来让empty()判断出队列是否已经结束。
当然,queue我们可以正确判断是否已经清空,但是线程里的get队列是不知道,如果没有东西告诉它,队列空了,因此get还会继续阻塞,那么我们就需要在get程序中加一个判断,如果empty()成立,break退出循环,否则get()还是会一直阻塞。
慢速生产-快速消费
但是如果生产者速度与消费者速度相当,或者生产速度小于消费速度,则靠task_done()来实现队列减一则不靠谱,队列会时常处于供不应求的状态,常为empty,所以用empty来判断则不靠谱。
那么这种情况会导致 join可以判断出队列结束了,但是线程里不能依靠empty()来判断线程是否可以结束。
我们可以在消费队列的每个线程最后塞入一个特定的“标记”,在消费的时候判断,如果get到了这么一个“标记”,则可以判定队列结束了,因为生产队列都结束了,也不会再新增了。
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''threading test'''
import threading
import queue
from time import sleep
#之所以为什么要用线程,因为线程可以start后继续执行后面的主线程,可以put数据,如果不是线程直接在get阻塞。
class Mythread(threading.Thread):
def __init__(self,que):
threading.Thread.__init__(self)
self.queue = que
def run(self):
while True:
item = self.queue.get()
self.queue.task_done() #这里要放到判断前,否则取最后最后一个的时候已经为空,直接break,task_done执行不了,join()判断队列一直没结束
if item == None:
break
print(item,'!')
return
que = queue.Queue()
tasks = [Mythread(que) for x in range(1)]
#快速生产
for x in tasks:
t = Mythread(que) #把同一个队列传入2个线程
t.start()
for x in range(10):
sleep(1)
que.put(x)
for x in tasks:
que.put(None)
que.join()
print('---success---')
注意点
put队列完成的时候千万不能用task_done(),否则会报错:
task_done() called too many times
因为该方法仅仅表示get成功后,执行的一个标记。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中线程的MQ消息队列实现以及消息队列的优点解析
"消息队列"是在消息的传输过程中保存消息的容器.消息队列管理器在将消息从它的源中继到它的目标时充当中间人.队列的主要目的是提供路由并保证消息的传递:如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它.相信对任何架构或应用来说,消息队列都是一个至关重要的组件,下面是十个理由: Python的消息队列示例: 1.threading+Queue实现线程队列 #!/usr/bin/env python import Queue import threading import
-
Python进程间通信 multiProcessing Queue队列实现详解
一.进程间通信 IPC(Inter-Process Communication) IPC机制:实现进程之间通讯 管道:pipe 基于共享的内存空间 队列:pipe+锁的概念--->queue 二.队列(Queue) 2.1 概念-----multiProcess.Queue 创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递. Queue([maxsize])创建共享的进程队列. 参数 :maxsize是队列中允许的最大项数.如果省略此参数,则无大小限制
-
python中的queue队列类型及函数用法
目录 python queue队列类型及函数 1.队列的种类 2.队列函数 python 队列类及其方法 1.Python的队列类型 2.队列对象(适用Queue.LifoQueue和PriorityQueue) 3.SimpleQueue对象 python queue队列类型及函数 1.队列的种类 Python queue模块的FIFO队列先进先出. class queue.Queue(maxsize) LIFO类似于堆,即先进后出. class queue.LifoQueue(maxsize
-
Queue队列中join()与task_done()的关系及说明
目录 join()与task_done()的关系 理解 快速生产-快速消费 慢速生产-快速消费 注意点 总结 join()与task_done()的关系 在网上大多关于join()与task_done()的结束原话是这样的: Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号 Queue.join() 实际上意味着等到队列为空,再执行别的操作 但是可能很多人还是不太理解,这里以我自己的理解来阐述这两者的关联. 理解 如果
-
Python3 queue队列模块详细介绍
queue介绍 queue是python中的标准库,俗称队列. 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性. 注意: 在python2.x中,模块名为Queue queue模块有三种队列及构造函数 Python queue模块的FIFO队列先进先出. queue.Queue(maxsize) LIFO类似于堆,即先进后
-
Python queue队列原理与应用案例分析
本文实例讲述了Python queue队列原理与应用.分享给大家供大家参考,具体如下: 作用: 解耦:使程序直接实现松耦合,修改一个函数,不会有串联关系. 提高处理效率:FIFO = 现进先出,LIFO = 后入先出. 队列: 队列可以并发的派多个线程,对排列的线程处理,并切每个需要处理线程只需要将请求的数据放入队列容器的内存中,线程不需要等待,当排列完毕处理完数据后,线程在准时来取数据即可.请求数据的线程只与这个队列容器存在关系,处理数据的线程down掉不会影响到请求数据的线程,队列会派给其他
-
Python多线程通信queue队列用法实例分析
本文实例讲述了Python多线程通信queue队列用法.分享给大家供大家参考,具体如下: queue: 什么是队列:是一种特殊的结构,类似于列表.不过就像排队一样,队列中的元素一旦取出,那么就会从队列中删除. 线程之间的通信可以使用队列queue来进行 线程如何使用queue.Queue[还有其他类型的对象下面讲]来通信: 1.创建一个Queue对象:对象=queue.Queue(x),x是队列容量,x可以不填,默认没有容量限制, 2.get()可以使线程从队列中获取一个元素,如果队列为空,ge
-

MySQL中join语句的基本使用教程及其字段对性能的影响
join语句的基本使用 SQL(MySQL) JOIN 用于根据两个或多个表中的字段之间的关系,从这些表中得到数据. JOIN 通常与 ON 关键字搭配使用,基本语法如下: ... FROM table1 INNER|LEFT|RIGHT JOIN table2 ON conditiona table1 通常称为左表,table2 称为右表.ON 关键字用于设定匹配条件,用于限定在结果集合中想要哪些行.如果需要指定其他条件,后面可以加上 WHERE 条件 或者 LIMIT 以限制记录返回数目等.
-
Laravel使用Queue队列的技巧汇总
前言 Laravel 队列为不同的后台队列服务提供统一的 API,例如 Beanstalk,Amazon SQS,Redis,甚至其他基于关系型数据库的队列.队列的目的是将耗时的任务延时处理,比如发送邮件,从而大幅度缩短 Web 请求和相应的时间. 队列配置文件存放在 config/queue.php .每一种队列驱动的配置都可以在该文件中找到,包括数据库,Beanstalkd ,Amazon SQS,Redis,以及同步(本地使用)驱动.其中还包含了一个 null 队列驱动用于那些放弃队列的任
-
python 多线程中join()的作用
一 前言 温习python 多进程语法的时候,对 join的理解不是很透彻,本文通过代码实践来加深对 join()的认识. multiprocessing 是python提供的跨平台版本的多进程模块.multiprocessing可以充分利用多核,提升程序运行效率.multiprocessing支持子进程,通信和共享数据,执行不同形式的同步,提供了Process.Queue.Pipe.Lock等组件.不过今天重点了解 join.后续文章会逐步学习介绍其他组件或者功能. 二 动手实践 join()
-
php的lavarel框架中join和orWhere的用法
Laravel是一个开源PHP框架,功能强大且易于理解.它遵循模型 - 视图 - 控制器设计模式(MVC).Laravel重用了不同框架的现有组件,这有助于创建Web应用程序.这样设计的Web应用程序更加结构化和实用. Laravel框架的主要特点: 1.模块化包装 2.依赖管理器完全基于composer 3.精湛的自动加载器 4.优雅的ORM 5.查询构建器作为潜在的ORM替代 6.PostgreSQL,MySQL,SQL Server平台支持您的数据库 7.简化的叶片模板引擎 8.比以前更快
-
JAVA多线程中join()方法的使用方法
虽然关于讨论线程join()方法的博客已经非常极其特别多了,但是前几天我有一个困惑却没有能够得到详细解释,就是当系统中正在运行多个线程时,join()到底是暂停了哪些线程,大部分博客给的例子看起来都像是t.join()方法会使所有线程都暂停并等待t的执行完毕.当然,这也是因为我对多线程中的各种方法和同步的概念都理解的不是很透彻.通过看别人的分析和自己的实践之后终于想明白了,详细解释一下希望能帮助到和我有相同困惑的同学. 首先给出结论:t.join()方法只会使主线程(或者说调用t.join()的