torch.optim优化算法理解之optim.Adam()解读
目录
- optim.Adam()解读
- 优化步骤
- Adam算法
- 其公式如下
- 参数
- torch.optim.adam源码
- Adam的特点有
optim.Adam()解读
torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来。
为了使用torch.optim,需先构造一个优化器对象Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数。
要构建一个优化器optimizer,你必须给它一个可进行迭代优化的包含了所有参数(所有的参数必须是变量s)的列表。 然后,您可以指定程序优化特定的选项,例如学习速率,权重衰减等。
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr = 0.0001) self.optimizer_D_B = torch.optim.Adam(self.netD_B.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
Optimizer还支持指定每个参数选项。 只需传递一个可迭代的dict来替换先前可迭代的Variable。dict中的每一项都可以定义为一个单独的参数组,参数组用一个params键来包含属于它的参数列表。
其他键应该与优化器接受的关键字参数相匹配,才能用作此组的优化选项。
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
如上,model.base.parameters()将使用1e-2的学习率,model.classifier.parameters()将使用1e-3的学习率。0.9的momentum作用于所有的parameters。
优化步骤
所有的优化器Optimizer都实现了step()方法来对所有的参数进行更新,它有两种调用方法:
optimizer.step()
这是大多数优化器都支持的简化版本,使用如下的backward()方法来计算梯度的时候会调用它。
for input, target in dataset: optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() optimizer.step()
optimizer.step(closure)
一些优化算法,如共轭梯度和LBFGS需要重新评估目标函数多次,所以你必须传递一个closure以重新计算模型。 closure必须清除梯度,计算并返回损失。
for input, target in dataset: def closure(): optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() return loss optimizer.step(closure)
Adam算法
adam算法来源:Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
其公式如下
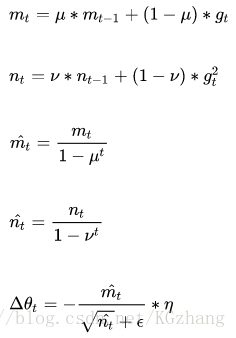
其中,前两个公式分别是对梯度的一阶矩估计和二阶矩估计,可以看作是对期望E|gt|,E|gt^2|的估计;
公式3,4是对一阶二阶矩估计的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整。
最后一项前面部分是对学习率n形成的一个动态约束,而且有明确的范围。
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
参数
params(iterable):可用于迭代优化的参数或者定义参数组的dicts。lr (float, optional):学习率(默认: 1e-3)betas (Tuple[float, float], optional):用于计算梯度的平均和平方的系数(默认: (0.9, 0.999))eps (float, optional):为了提高数值稳定性而添加到分母的一个项(默认: 1e-8)weight_decay (float, optional):权重衰减(如L2惩罚)(默认: 0)step(closure=None)函数:执行单一的优化步骤closure (callable, optional):用于重新评估模型并返回损失的一个闭包
torch.optim.adam源码
import math from .optimizer import Optimizer class Adam(Optimizer): def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,weight_decay=0): defaults = dict(lr=lr, betas=betas, eps=eps,weight_decay=weight_decay) super(Adam, self).__init__(params, defaults) def step(self, closure=None): loss = None if closure is not None: loss = closure() for group in self.param_groups: for p in group['params']: if p.grad is None: continue grad = p.grad.data state = self.state[p] # State initialization if len(state) == 0: state['step'] = 0 # Exponential moving average of gradient values state['exp_avg'] = grad.new().resize_as_(grad).zero_() # Exponential moving average of squared gradient values state['exp_avg_sq'] = grad.new().resize_as_(grad).zero_() exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq'] beta1, beta2 = group['betas'] state['step'] += 1 if group['weight_decay'] != 0: grad = grad.add(group['weight_decay'], p.data) # Decay the first and second moment running average coefficient exp_avg.mul_(beta1).add_(1 - beta1, grad) exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad) denom = exp_avg_sq.sqrt().add_(group['eps']) bias_correction1 = 1 - beta1 ** state['step'] bias_correction2 = 1 - beta2 ** state['step'] step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1 p.data.addcdiv_(-step_size, exp_avg, denom) return loss
Adam的特点有
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点;
2、对内存需求较小;
3、为不同的参数计算不同的自适应学习率;
4、也适用于大多非凸优化-适用于大数据集和高维空间。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
关于torch.optim的灵活使用详解(包括重写SGD,加上L1正则)
torch.optim的灵活使用详解 1. 基本用法: 要构建一个优化器Optimizer,必须给它一个包含参数的迭代器来优化,然后,我们可以指定特定的优化选项, 例如学习速率,重量衰减值等. 注:如果要把model放在GPU中,需要在构建一个Optimizer之前就执行model.cuda(),确保优化器里面的参数也是在GPU中. 例子: optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) 2. 灵活的设置各层的
-
在pytorch中动态调整优化器的学习率方式
在深度学习中,经常需要动态调整学习率,以达到更好地训练效果,本文纪录在pytorch中的实现方法,其优化器实例为SGD优化器,其他如Adam优化器同样适用. 一般来说,在以SGD优化器作为基本优化器,然后根据epoch实现学习率指数下降,代码如下: step = [10,20,30,40] base_lr = 1e-4 sgd_opt = torch.optim.SGD(model.parameters(), lr=base_lr, nesterov=True, momentum=0.9) de
-
浅谈Pytorch torch.optim优化器个性化的使用
一.简化前馈网络LeNet import torch as t class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__init__() self.features = t.nn.Sequential( t.nn.Conv2d(3, 6, 5), t.nn.ReLU(), t.nn.MaxPool2d(2, 2), t.nn.Conv2d(6, 16, 5), t.nn.ReLU(), t.nn.MaxPool2d(2
-
torch.optim优化算法理解之optim.Adam()解读
目录 optim.Adam()解读 优化步骤 Adam算法 其公式如下 参数 torch.optim.adam源码 Adam的特点有 optim.Adam()解读 torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来. 为了使用torch.optim,需先构造一个优化器对象Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数. 要构建一个优化器optimizer,你必须给它一个可进行迭代优化的
-

蝴蝶优化算法及实现源码
目录 算法简介 香味 具体算法 参考文献 群智能算法学习笔记笔记内容和仿真代码可能会不断改动如有不当之处,欢迎指正 算法简介 蝴蝶优化算法(butterfly optimization algorithm, BOA)是Arora 等人于2019年提出的一种元启发式智能算法.该算法受到了蝴蝶觅食和交配行为的启发,蝴蝶接收/感知并分析空气中的气味,以确定食物来源/交配伙伴的潜在方向. 蝴蝶利用它们的嗅觉.视觉.味觉.触觉和听觉来寻找食物和伴侣,这些感觉也有助于它们从一个地方迁徙到另一个地方,逃离捕食
-
PHP排序算法之快速排序(Quick Sort)及其优化算法详解
本文实例讲述了PHP排序算法之快速排序(Quick Sort)及其优化算法.分享给大家供大家参考,具体如下: 基本思想: 快速排序(Quicksort)是对冒泡排序的一种改进.他的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,整个排序过程可以递归进行,以达到整个序列有序的目的. 基本算法步骤: 举个栗子: 假如现在待排序记录是: 6 2 7 3 8 9 第一步.创建变量 $low 指
-
python绘制评估优化算法性能的测试函数
测试函数主要是用来评估优化算法特性的,这里我用python3绘制了部分测试函数的图像.具体的测试函数可以结合维基百科来了解.想要显示某个测试函数的图片把代码结尾对应的注释去掉即可,具体代码如下: import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D def draw_pic(X, Y, Z, z_max, title, z_min=0): fig = plt.figur
-
Python光学仿真从Maxwell方程组到波动方程矢量算法理解学习
Maxwell方程组是十九世纪最伟大的公式,代表了传统物理学人对公式美学的孜孜追求,也影响了无数后来者的物理美学品味. 回顾历史,当1864年,Maxwell发出那篇著名的<电磁场的动力学理论>时,实则列出了二十个公式,以总结前人的物理学成果,我们将分量公式合并为矢量,可以得到八个式子,即 以上符号分别表示 二十年后,Heaviside对这二十个公式进行重新编排,得到了我们熟悉的形式,并将其命名为麦克斯韦方程组: 对上式中左侧两个旋度公式再取旋度,得到 其中, ∇ E = 0,所以可得到波动方
-
C++冒泡排序及其优化算法
目录 冒泡排序极其优化 算法步骤 全部程序 冒泡排序代码 优化思路 冒泡排序优化核心代码 冒泡排序极其优化 算法步骤 1.比较相邻的元素.如果第一个比第二个大,就交换他们两个. 2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.这步做完后,最后的元素会是最大的数. 3.针对所有的元素重复以上的步骤,除了最后一个. 4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较 全部程序 //为了随机生成区间 [m,n] 之间的整数,可以用公式 rand()%(n-m+1)
-
Python&Matlab实现灰狼优化算法的示例代码
目录 1 灰狼优化算法基本思想 2 灰狼捕食猎物过程 2.1 社会等级分层 2.2 包围猎物 2.3 狩猎 2.4 攻击猎物 2.5 寻找猎物 3 实现步骤及程序框图 3.1 步骤 3.2 程序框图 4 Python代码实现 5 Matlab实现 1 灰狼优化算法基本思想 灰狼优化算法是一种群智能优化算法,它的独特之处在于一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进.在了解灰狼优化算法的特点之前,我们有必要了解灰狼群中的等级制度. 灰狼群一般分为4个等级:处于第一等级的灰狼用α表示,处于第
-
C语言数据结构之堆排序的优化算法
目录 1.堆排序优化算法 1.1建堆的时间复杂度 1.1.1 向下调整建堆:O(N) 1.1.2 向上调整建堆:O(N*logN) 1.2堆排序的复杂度 1.2.1原堆排序的时间复杂度 1.2.2原堆排序的空间复杂度 1.3堆排序优化算法的复杂度 1.3.1 堆排序优化算法的时间复杂度 1.3.2 堆排序优化算法的空间复杂度 1.4堆排序实现逻辑 1.5堆排序实现代码 1.6演示结果 总结 在浏览本篇博文的小伙伴可先浅看一下上篇堆和堆排序的思想: 戳这里可跳转上篇文~~ 1.堆排序优化算法 要堆
-
基于Matlab实现嗅觉优化算法的示例代码
目录 1.概述 2.37 个 CEC 基准测试函数代码 3.F1 Matlab代码仿真 1.概述 嗅觉剂优化是一种新颖的优化算法,旨在模仿气味分子源尾随的药剂的智能行为.该概念分为三个阶段(嗅探,尾随和随机)是独特且易于实现的.此上传包含 SAO 在 37 个 CEC 基准测试函数上的实现. 2.37 个 CEC 基准测试函数代码 function [lb,ub,dim,fobj] = Select_Function(F) switch F case 'F1' %Admijan fobj = @