pandas中关于apply+lambda的应用
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任 何参数都不会被传递,kwargs是一个包含关键字参数的字典。简单说apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致,与map的区别是前者针对column,后者针对元素
lambda是匿名函数,即不再使用def的形式,可以简化脚本,使结构不冗余何简洁
a = lambda x : x + 1 a(10) 11
两者结合可以做很多很多事情,比如split在series里很多功能不可用,而index就可以做
比如有一串数据如下,要切分为总数,正确数,正确率,则可这样做
96%(1368608/1412722)
97%(1389916/1427922)
97%(1338695/1373803)
96%(1691941/1745196)
95%(1878802/1971608)
97%(944218/968845)
96%(1294939/1336576)
import pandas as pd
#先生成一个dataframe
d = {"col1" : ["96%(1368608/1412722)",
"97%(1389916/1427922)",
"97%(1338695/1373803)",
"96%(1691941/1745196)",
"95%(1878802/1971608)",
"97%(944218/968845)",
"96%(1294939/1336576)"]}
df1 = pd.DataFrame(d)
#切分原文中识别率总数,采用apply + 匿名函数
#lambda 函数的意思是选取x的序列值 ,比如 x[6:9]
#index函数的意思是把当前字符位置转变为所在位置的位数
#-1是最后一位
df1['正确数'] = df1.iloc[:,0].apply(lambda x : x[x.index('(') + 1 : x.index('/')])
df1['总数'] = df1.iloc[:,0].apply(lambda x : x[x.index('/') + 1 : -1])
df1['正确率'] = df1.iloc[:,0].apply(lambda x : x[:x.index('(')])
df1

示例2
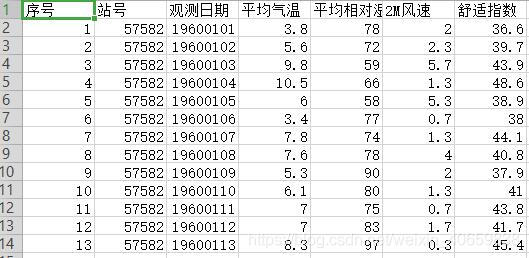
由一组dataframe数据,包括有数值型的三列气象要素,由这三列通过公式计算人体舒适指数

应用到的人体舒适指数计算公式:

import pandas as pd
import numpy as np
import math
path='D:\\data\\57582.csv' #文件路径
data=pd.read_csv(path,index_col=0,encoding='gbk') #读取数据有中文时用gbk解码
#定义舒适指数公式函数,结果保留1位小数
def get_CHB(T,RH,S):
return round(1.8*T-0.55*(1.8*T-26)*(1-RH/100)-3.2*math.sqrt(S)+32,1)
#增加一列CHB并计算数据后赋值
data['舒适指数']=data.apply(lambda x:get_CHB(x['平均气温'],x['平均相对湿度'],x['2M风速']),axis=1)
#打印结果
print(data)
#保存结果
data.to_csv('D:\\CHB.csv',encoding='gbk')
代码中使用了apply和lambda的组合,传入的参数x为整个data数据,在函数中引入的参数则是x[‘平均气温’],x[‘平均相对湿度’],x[‘2M风速’],与自定义的函数get_CHB对应。最后需使用axis=1来指定是对列进行运算。
结果如图所示:
到此这篇关于pandas中关于apply+lambda的应用的文章就介绍到这了,更多相关pandas apply+lambda内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas对DataFrame单列/多列进行运算(map, apply, transform, agg)
1.单列运算 在Pandas中,DataFrame的一列就是一个Series, 可以通过map来对一列进行操作: df['col2'] = df['col1'].map(lambda x: x**2) 其中lambda函数中的x代表当前元素.可以使用另外的函数来代替lambda函数,例如: define square(x): return (x ** 2) df['col2'] = df['col1'].map(square) 2.多列运算 apply()会将待处理的对象拆分成多个片段,然后对各
-
pandas apply 函数 实现多进程的示例讲解
前言: 在进行数据处理的时候,我们经常会用到 pandas .但是 pandas 本身好像并没有提供多进程的机制.本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行.其中,我们主要借助 joblib库,这个库为python 提供了一个非常简洁方便的多进程实现方法. 所以,本文将按照下面的安排展开,前面可能比较啰嗦,若只是想知道怎么用可直接看第三部分: - 首先简单介绍 pandas 中的分组聚合操作 groupby. - 然后简单介绍 joblib 的使用方法. - 最后,
-
浅谈Pandas中map, applymap and apply的区别
1.apply() 当想让方程作用在一维的向量上时,可以使用apply来完成,如下所示 In [116]: frame = DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon']) In [117]: frame Out[117]: b d e Utah -0.029638 1.081563 1.280300 Ohio 0.647747 0.831136 -1.
-

pandas map(),apply(),applymap()区别解析
基础 以下操作基于python 3.6 windows 10 环境下 通过 将通过实例来演示三者的区别 toward_dict = {1: '东', 2: '南', 3: '西', 4: '北'} df = pd.DataFrame({'house' : list('AABCEFG'), 'price' : [100, 90, '', 50, 120, 150, 200], 'toward' : ['1','1','2','3','','3','2']}) df map()方法 通过df.(ta
-
详解Pandas的三大利器(map,apply,applymap)
目录 模拟数据 1.map demo 实际数据 2.apply demo apply实现需求 3.applymap DF数据加1 保留2位有效数字 实际工作中,我们在利用 pandas进行数据处理的时候,经常会对数据框中的单行.多行(列也适用)甚至是整个数据进行某种相同方式的处理,比如将数据中的 sex字段将 男替换成1,女替换成0. 在这个时候,很容易想到的是 for循环.用 for循环是一种很简单.直接的方式,但是运行效率很低.本文中介绍了 pandas中的三大利器: map.apply.a
-
解析pandas apply() 函数用法(推荐)
目录 Series.apply() apply 函数接收带有参数的函数 DataFrame.apply() apply() 计算日期相减示例 参考 理解 pandas 的函数,要对函数式编程有一定的概念和理解.函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它函数,也能作为函数的返回值. 函数作为对象能带来代码风格的巨大改变.举一个例子,有一个类型为 list 的变量,包含 从 1 到 10 的数据,需
-
pandas使用函数批量处理数据(map、apply、applymap)
前言 在我们对DataFrame对象进行处理时候,下意识的会想到对DataFrame进行遍历,然后将处理后的值再填入DataFrame中,这样做比较繁琐,且处理大量数据时耗时较长.Pandas内置了一个可以对DataFrame批量进行函数处理的工具:map.apply和applymap. 提示:为方便快捷地解决问题,本文仅介绍函数的主要用法,并非全面介绍 一.pandas.Series.map()是什么? 把Series中的值进行逐一映射,带入进函数.字典或Series中得出的另一个值. Ser
-
详谈pandas中agg函数和apply函数的区别
在利用python进行数据分析 这本书中其实没有明确表明这两个函数的却别,而是说apply更一般化. 其实在这本书的第九章'数组及运算和转换'点到了两者的一点点区别:agg是用来聚合运算的,所谓的聚合当然是合成的成分比较大些,这一节开头就点到了:聚合只不过是分组运算的其中一种而已.它是数据转换的一个特例,也就是说,它接受能够将一维数组简化为标量值的函数. 当然这两个函数都是作用在groupby对象上的,也就是分完组的对象上的,分完组之后针对某一组,如果值是一维数组,在利用完特定的函数之后,能做到
-
pandas中关于apply+lambda的应用
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数.args是一个包含将要提供给函数的按位置传递的参数的元组.如果省略了args,任 何参数都不会被传递,kwargs是一个包含关键字参数的字典.简单说apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致,与map的区别是前者针对column,后者针对元素 lambda是匿名函数,即不再使用def
-
Pandas中Apply函数加速百倍的技巧分享
目录 前言 实验对比 01 Apply(Baseline) 02 Swift加速 03 向量化 04 类别转化+向量化 05 转化为values处理 实验汇总 前言 虽然目前dask,cudf等包的出现,使得我们的数据处理大大得到了加速,但是并不是每个人都有比较好的gpu,非常多的朋友仍然还在使用pandas工具包,但有时候真的很无奈,pandas的许多问题我们都需要使用apply函数来进行处理,而apply函数是非常慢的,本文我们就介绍如何加速apply函数600倍的技巧. 实验对比 01 A
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
Pandas中map(),applymap(),apply()函数的使用方法
目录 指定pandas对象作为NumPy函数的参数 元素的应用 行/列的应用 pandas.DataFrame,pandas.Series方法 Pandas对象方法的函数应用 适用于Series的每个元素:map(),apply() 应用于DataFrame的每个元素:applymap() 应用于DataFrame的每行和每列:apply() 应用于DataFrame的特定行/列元素 将函数应用于pandas对象(pandas.DataFrame,pandas.Series)时,根据所应用的函数
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
pandas中apply和transform方法的性能比较及区别介绍
1. apply与transform 首先讲一下apply() 与transform()的相同点与不同点 相同点: 都能针对dataframe完成特征的计算,并且常常与groupby()方法一起使用. 不同点: apply()里面可以跟自定义的函数,包括简单的求和函数以及复杂的特征间的差值函数等(注:apply不能直接使用agg()方法 / transform()中的python内置函数,例如sum.max.min.'count'等方法) transform() 里面不能跟自定义的特征交互函数,
-
在pandas中遍历DataFrame行的实现方法
有如下 Pandas DataFrame: import pandas as pd inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}] df = pd.DataFrame(inp) print df 上面代码输出: c1 c2 0 10 100 1 11 110 2 12 120 现在需要遍历上面DataFrame的行.对于每一行,都希望能够通过列名访问对应的元素(单元格中的值).也就是说,需要类
-
对pandas中Series的map函数详解
Series的map方法可以接受一个函数或含有映射关系的字典型对象. 使用map是一种实现元素级转换以及其他数据清理工作的便捷方式. (DataFrame中对应的是applymap()函数,当然DataFrame还有apply()函数) 1.字典映射 import pandas as pd from pandas import Series, DataFrame data = DataFrame({'food':['bacon','pulled pork','bacon','Pastrami',