FP-growth算法发现频繁项集——发现频繁项集
上篇介绍了如何构建FP树,FP树的每条路径都满足最小支持度,我们需要做的是在一条路径上寻找到更多的关联关系。
抽取条件模式基
首先从FP树头指针表中的单个频繁元素项开始。对于每一个元素项,获得其对应的条件模式基(conditional pattern base),单个元素项的条件模式基也就是元素项的关键字。条件模式基是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前辍路径(perfix path)。简而言之,一条前缀路径是介于所査找元素项与树根节点之间的所有内容。
下图是以{s:2}或{r:1}为元素项的前缀路径:
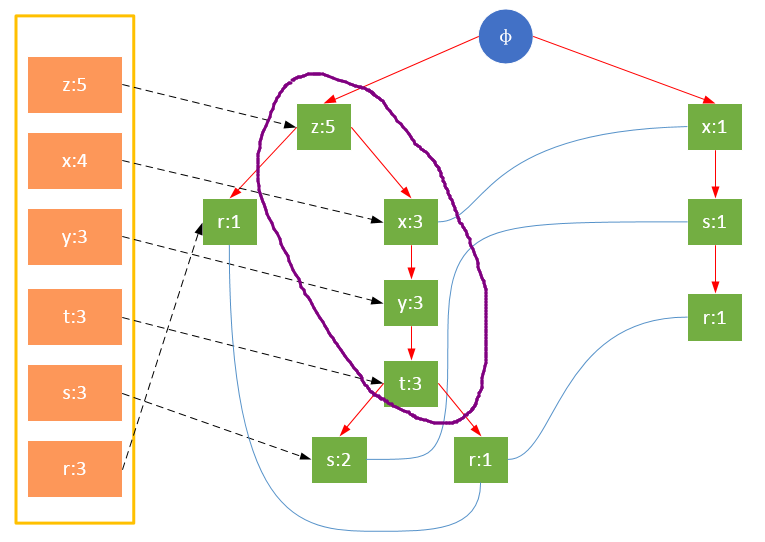
{s}的条件模式基,即前缀路径集合共有两个:{{z,x,y,t}, {x}};{r}的条件模式基共三个:{{z}, {z,x,y,t}, {x,s}}。
寻找条件模式基的过程实际上是从FP树的每个叶子节点回溯到根节点的过程。我们可以通过头指针列表headTable开始,通过指针的连接快速访问到所有根节点。下表是上图FP树的所有条件模式基:

创建条件FP树
为了发现更多的频繁项集,对于每一个频繁项,都要创建一棵条件FP树。可以使用刚才发现的条件模式基作为输入数据,并通过相同的建树代码来构建这些树。然后,递归地发现频繁项、发现条件模式基,以及发现另外的条件树。
以频繁项r为例,构建关于r的条件FP树。r的三个前缀路径分别是{z},{z,x,y,t},{x,s},设最小支持度minSupport=2,则y,t,s被过滤掉,剩下{z},{z,x},{x}。y,s,t虽然是条件模式基的一部分,但是并不属于条件FP树,即对于r来说,它们不是频繁的。如下图所示,y→t→r和s→r的全局支持度都为1,所以y,t,s对于r的条件树来说是不频繁的。
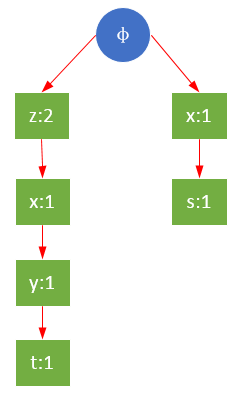
过滤后的r条件树如下:
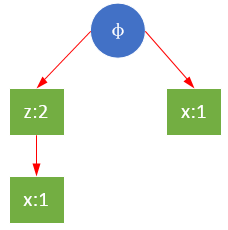
重复上面步骤,r的条件模式基是{z,x},{x},已经没有能够满足最小支持度的路径, 所以r的条件树仅有一个。需要注意的是,虽然{z,x},{x}中共存在两个x,但{z,x}中,z是x的父节点,在构造条件FP树时不能直接将父节点移除,仅能从子节点开始逐级移除。
代码如下:
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(basePat, headTable):
condPats = {}
treeNode = headTable[basePat][1]
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats
def mineTree(inTree, headerTable, minSup=1, preFix=set([]), freqItemList=[]):
# order by minSup asc, value asc
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: (p[1][0],p[0]))]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
# 通过条件模式基找到的频繁项集
condPattBases = findPrefixPath(basePat, headerTable)
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None:
print('condPattBases: ', basePat, condPattBases)
myCondTree.disp()
print('*' * 30)
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
condPats = findPrefixPath('z', myheader)
print('z', condPats)
condPats = findPrefixPath('x', myheader)
print('x', condPats)
condPats = findPrefixPath('y', myheader)
print('y', condPats)
condPats = findPrefixPath('t', myheader)
print('t', condPats)
condPats = findPrefixPath('s', myheader)
print('s', condPats)
condPats = findPrefixPath('r', myheader)
print('r', condPats)
mineTree(myFPTree, myheader, 2)
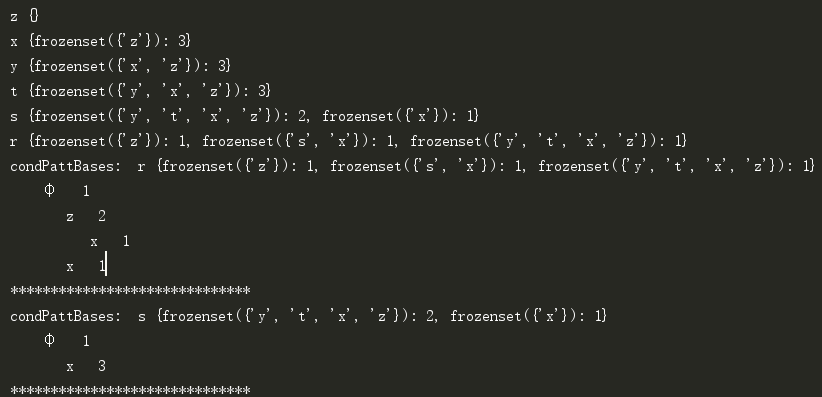
控制台信息:
总结
本篇文章就到这了,本例可以发现两个频繁项集{z,x}和{x}。取得频繁项集后,可以根据置信度发现关联规则,这一步较为简单,可参考上篇的相关内容,不在赘述。希望能够给你带来帮助,也希望您能够多多关注我们的其他精彩内容!
相关推荐
-
FP-Growth算法的Java实现+具体实现思路+代码
FP-Growth算法原理 其他大佬的讲解 FP-Growth算法详解 FP-Growth算法的Java实现 这篇文章重点讲一下实现.如果看了上述给的讲解,可知,需要两次扫描来构建FP树 第一次扫描 第一次扫描,过滤掉所有不满足最小支持度的项:对于满足最小支持度的项,按照全局支持度降序排序. 按照这个需求,可能的难点为如何按照全局支持度对每个事务中的item排序.我的实现思路 扫描原数据集将其保存在二维列表sourceData中 维护一个Table,使其保存每个item的全局支持度TotalSu
-

Java编程实现A*算法完整代码
前言 A*搜寻算法俗称A星算法.这是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法.常用于游戏中 通过二维数组构建的一个迷宫,"%"表示墙壁,A为起点,B为终点,"#"代表障碍物,"*"代表算法计算后的路径 本文实例代码结构: % % % % % % % % o o o o o % % o o # o o % % A o # o B % % o o # o o % % o o o o o % % % % % % % % =======
-
详解Java如何实现FP-Growth算法
FP-Growth算法的Java实现 这篇文章重点讲一下实现.需要两次扫描来构建FP树 第一次扫描 第一次扫描,过滤掉所有不满足最小支持度的项:对于满足最小支持度的项,按照全局支持度降序排序. 按照这个需求,可能的难点为如何按照全局支持度对每个事务中的item排序. 我的实现思路 扫描原数据集将其保存在二维列表sourceData中 维护一个Table,使其保存每个item的全局支持度TotalSup 在Table中过滤掉低于阈值minSup的项 将Table转换为List,并使其按照Total
-
FP-growth算法发现频繁项集——构建FP树
FP代表频繁模式(Frequent Pattern),算法主要分为两个步骤:FP-tree构建.挖掘频繁项集. FP树表示法 FP树通过逐个读入事务,并把事务映射到FP树中的一条路径来构造.由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠.路径相互重叠越多,使用FP树结构获得的压缩效果越好:如果FP树足够小,能够存放在内存中,就可以直接从这个内存中的结构提取频繁项集,而不必重复地扫描存放在硬盘上的数据. 一颗FP树如下图所示: 通常,FP树的大小比未压缩的数据小,因为数据的事务常
-
python+pyqt5实现24点小游戏
本文实例为大家分享了python实现24点游戏的具体代码,供大家参考,具体内容如下 描述:一副牌中A.J.Q.K可以当成是1.11.12.13.任意抽取4张牌,用加.减.乘.除(可加括号)把牌面上的数算成24.每张牌对应的数字必须用一次且只能用一次.在规定时间内输入算式,输入正确加十分,输入错误生命值减一,点击确定提交并进入下一题,点击清空可清空算式.点击开始游戏进入游戏,可重新开始游戏. from PyQt5 import QtCore, QtWidgets from PyQt5.QtWidg
-
FP-growth算法发现频繁项集——发现频繁项集
上篇介绍了如何构建FP树,FP树的每条路径都满足最小支持度,我们需要做的是在一条路径上寻找到更多的关联关系. 抽取条件模式基 首先从FP树头指针表中的单个频繁元素项开始.对于每一个元素项,获得其对应的条件模式基(conditional pattern base),单个元素项的条件模式基也就是元素项的关键字.条件模式基是以所查找元素项为结尾的路径集合.每一条路径其实都是一条前辍路径(perfix path).简而言之,一条前缀路径是介于所査找元素项与树根节点之间的所有内容. 下图是以{s:2}或{
-
Docker搭建RabbitMq的普通集群和镜像集群的详细操作
目录 一.搭建RabbitMq的运行环境 1.通过search查询rabbitmq镜像 2.通过pull拉取rabbitmq的官方最新镜像 3.创建容器 4.启动管理页面 5.设置erlang cookie 二.普通模式 三.镜像模式 普通集群:多个节点组成的普通集群,消息随机发送到其中一个节点的队列上,其他节点仅保留元数据,各个节点仅有相同的元数据,即队列结构.交换器结构.vhost等.消费者消费消息时,会从各个节点拉取消息,如果保存消息的节点故障,则无法消费消息,如果做了消息持久化,那么得等
-
ZooKeeper集群操作及集群Master选举搭建启动
目录 ZooKeeper介绍 ZooKeeper特征 分层命名空间 搭建ZK集群 启动zk集群 zk集群master选举 ZooKeeper介绍 ZooKeeper 是一个为 分布式应用 提供的 分布式 .开源的 协调服务 . 它公开了一组简单的 原语 ,分布式应用程序可以根据这些原语来实现用于 同步 .配置维护 以及 命名 的更高级别的服务. 怎么理解协调服务呢?比如我们有很多应用程序,他们之间都需要读写维护一个 id ,那么这些 id 怎么命名呢,程序一多,必然会乱套,ZooKeeper 能
-
BootStrap 动态添加验证项和取消验证项的实现方法
bootstrap 中的bootstrapValidator可以对前端的数据进行验证,但是有的时候我们需要动态的添加验证,这样需要我们动态的对bootstrapValidator的内容做修改. 传统的bootstrapValidator验证是 $('#MaintainEntryForm').bootstrapValidator({ message: '输入值无效!', feedbackIcons: { valid: 'glyphicon glyphicon-ok', invalid: 'glyp
-
关于docker compose安装redis集群的问题(集群扩容、集群收缩)
目录 一.redis 配置信息模板 二.编写批量生成配置文件脚本 三.批量生成配置文件 四.编写 docker-compose 文件 五.做集群.分配插槽 六.测试: 七.手动扩容 八.添加主从节点 1.添加主节点 2.添加从节点 九.分配插槽 十.集群测试 十一.常用命令 一.redis 配置信息模板 文件名:redis-cluster.tmpl # redis端口 port ${PORT} #redis 访问密码 requirepass 123456 #redis 访问Master节点密码
-
Python cookbook(数据结构与算法)从序列中移除重复项且保持元素间顺序不变的方法
本文实例讲述了Python从序列中移除重复项且保持元素间顺序不变的方法.分享给大家供大家参考,具体如下: 问题:从序列中移除重复的元素,但仍然保持剩下的元素顺序不变 解决方案: 1.如果序列中的值时可哈希(hashable)的,可以通过使用集合和生成器解决. # example.py # # Remove duplicate entries from a sequence while keeping order def dedupe(items): seen = set() for item i
-
详解MongoDB中用sharding将副本集分配至服务器集群的方法
关于副本集 副本集是一种在多台机器同步数据的进程. 副本集体提供了数据冗余,扩展了数据可用性.在多台服务器保存数据可以避免因为一台服务器导致的数据丢失. 也可以从硬件故障或服务中断解脱出来,利用额外的数据副本,可以从一台机器致力于灾难恢复或者备份. 在一些场景,可以使用副本集来扩展读性能.客户端有能力发送读写操作给不同的服务器. 也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力. mongodb副本集是一组拥有相同数据的mongodb实例,主mongodb接受所有的写操作,所有的其他实
-
C#使用Consul集群进行服务注册与发现
前言 我个人觉得,中间件的部署与使用是非常难记忆的:也就是说,如果两次使用中间件的时间间隔比较长,那基本上等于要重新学习使用. 所以,我觉得学习中间件的文章,越详细越好:因为,这对作者而言也是一份珍贵的备忘资料. Consul简介 Consul一个什么,我想大家通过搜索引擎一定可以搜索到:所以,我就不在重复他的官方描述了. 这里,我为大家提供一个更加好理解的描述. Consul是什么? Consul本质上是一个Socket通信中间件. 它主要实现了两个功能,服务注册与发现与自身的负载均衡的集群.
-
Docker consul的容器服务更新与发现的问题小结
目录 一.Docker consul的容器服务更新与发现 1.什么是服务注册与发现 2.什么是consul? 3.consul提供的一些关键特性 二.Consul部署 第一步:consul服务器上操作如下 1.建立 consul 服务 2.设置代理,后台启动 consul 服务器 第二步:registrator部署 192.168.80.20 上操作如下: 4.容器服务自动加入Nginx集群 5.安装Nginx.httpd测试镜像 6.在consul服务器中查看镜像是否注册 7.在web浏览器中
-
SpringCloud Eureka服务治理之服务注册服务发现
目录 什么是Eureka Eureka核心概念服务注册和服务发现 服务注册 服务发现 Eureka实战 Eureka服务端单节点构建 Eureka服务端集群构建 Eureka客户端构建 什么是Eureka Netflix Eureka 是一款由 Netflix 开源的基于 REST 服务的注册中心,用于提供服务发现功能.Spring Cloud Eureka 是 Spring Cloud Netflix 微服务套件的一部分,基于 Netflix Eureka 进行了二次封装,主要负责完成微服务架