数据结构简明备忘录 线性表
线性表
线性表是线性结构的抽象,线性结构的特点是结构中的数据元素之间存在一对一的线性关系。
数据元素之间的位置关系是一个接一个的排列:
.除第一个位置的数据元素外,其他数据元素位置的前面都只有一个数据元素。
.除最后一个位置的外,其他数据元素位置的后面都只有一个元素。
线性表通常表示为:L=(D,R)
D是数据元素的有限集合
R是数据元素之间关系的有限集合
public interface IListDS<T> {
int GetLength(); //求长度
void Clear(); //清空
bool IsEmpty(); //判空
void Append(T item); //附加
void Insert(T item, int i); //插入
T Delete(int i); //删除
T GetElement(int i); //取表元素
int Locate(T value); //按值查找
}
顺序表
顺序表是线性表的顺序存储(Sequence Storage),是指在内存中用一块地址连续的空间依次存放线性表的数据元素(Sequence List),具有随机存取的特点。
w: 每个数据元素占w个存储单元
A1:顺序表的基地址(Base Address)
Loc(Ai)=Loc(A1)+(i-1)*w 1<=i<=n
为了理解顺序表,闪电学习了这样一个例题,有兴趣的朋友可以在自己的机器上写一下。
有数据类型为整型的顺序表La和Lb,其数据元素均按从小到大的升序排列,编写一个算法将它们合并成一个表Lc,要求Lc中数据元素也按升序排列。
算法思路:
依次扫描La和Lb的数据元素,比较La和Lb当前数据元素的值,将较小值的数据元素赋给Lc,如此直到一个顺序表被扫描完,然后将未完的那个顺序表中余下的数据元素赋给Lc即可。Lc的容量要能够容纳La和Lb两个表相加的长度。
思路图示: 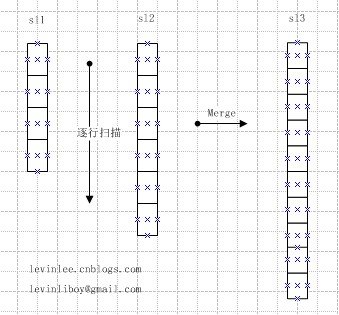
代码如下:
public class SeqList<T> : IListDS<T> {
private int maxsize; //顺序表的容量
private T[] data; //数组,用于存储顺序表中的数据元素
private int last; //指示顺序表最后一个元素的位置
//构造器
public SeqList(int size)
{
data = new T[size];
maxsize = size;
last = -1; //如果顺序表为空,last=-1
}
//索引器
public T this[int index]
{
get { return data[index]; }
set { data[index] = value; }
}
//最后一个元素的位置属性
public int Last
{
get { return last; }
}
//容量属性
public int Maxsize
{
get { return maxsize; }
set { maxsize = value; }
}
//判断顺序表是否为空
public bool IsEmpty()
{
if (last == -1)
return true;
else
return false;
}
//判断顺序表是否为满
public bool IsFull()
{
if (last == maxsize - 1)
return true;
else
return false;
}
//求顺序表的长度
public int GetLength()
{
return last + 1;
}
//清空顺序表
public void Clear()
{
last = -1;
}
//在顺序表末尾添加新元素
public void Append(T item)
{
if (IsFull())
{
Console.WriteLine("List is full.");
return;
}
data[++last] = item;
}
//在顺序表第i个数据元素位置插入一个数据元素
public void Insert(T item, int i)
{
if (IsFull())
return;
if (i < 1 || i > last + 2)
return;
if (i == last + 2)
data[last + 1] = item;
else
{
for (int j = last; j >= i - 1; --j)
{
data[j + 1] = data[j];
}
data[i - 1] = item;
}
++last;
}
//删除顺序表的第i个数据元素
public T Delete(int i)
{
T tmp = default(T);
if (IsEmpty())
return tmp;
if (i < 1 || i > last + 1)
return tmp;
if (i == last + 1)
tmp = data[last--];
else
{
tmp = data[i - 1];
for (int j = i; j <= last; ++j)
data[j] = data[j + 1];
}
--last;
return tmp;
}
//获得顺序表的第i个数据元素
public T GetElement(int i)
{
if (IsEmpty() || (i < 1) || (i > last + 1))
return default(T);
return data[i-1];
}
//在顺序表中查找值为value的数据元素
public int Locate(T value)
{
if (IsEmpty())
return -1;
int i = 0;
for (i = 0; i <= last; ++i)
{
if (value.Equals(data[i]))
break;
}
if (i > last)
return -1;
return i;
}
}
public class GenericList
{
public GenericList()
{ }
public SeqList<int> Merge(SeqList<int> La, SeqList<int> Lb)
{
SeqList<int> Lc = new SeqList<int>(La.Maxsize+Lb.Maxsize);
int i = 0;
int j = 0;
int k = 0;
//两个表中元素都不为空
while ((i <= (La.GetLength() - 1)) && (j <= (Lb.GetLength() - 1)))
{
if (La[i] < Lb[j])
Lc.Append(La[i++]);
else
Lc.Append(Lb[j++]);
}
//a表中还有数据元素
while (i <= (La.GetLength() - 1))
Lc.Append(La[i++]);
//b表中还有数据元素
while (j <= (Lb.GetLength() - 1))
Lc.Append(Lb[j++]);
return Lc;
}
}
static void Main(string[] args)
{
SeqList<int> sl1 = new SeqList<int>(4);
sl1.Append(1);
sl1.Append(3);
sl1.Append(4);
sl1.Append(7);
SeqList<int> sl2 = new SeqList<int>(6);
sl2.Append(2);
sl2.Append(5);
sl2.Append(6);
sl2.Append(8);
sl2.Append(11);
sl2.Append(14);
GenericList gl = new GenericList();
SeqList<int> sl3 = gl.Merge(sl1, sl2);
Console.WriteLine("length:" + sl3.GetLength());
for (int i = 0; i < sl3.GetLength(); i++)
{
Console.WriteLine(i + ":" + sl3[i]);
}
}
好了,下一次学习链表。
作者:LevinLee
相关推荐
-
python数据结构树和二叉树简介
一.树的定义 树形结构是一类重要的非线性结构.树形结构是结点之间有分支,并具有层次关系的结构.它非常类似于自然界中的树.树的递归定义:树(Tree)是n(n≥0)个结点的有限集T,T为空时称为空树,否则它满足如下两个条件:(1)有且仅有一个特定的称为根(Root)的结点:(2)其余的结点可分为m(m≥0)个互不相交的子集Tl,T2,-,Tm,其中每个子集本身又是一棵树,并称其为根的子树(Subree). 二.二叉树的定义 二叉树是由n(n≥0)个结点组成的有限集合.每个结点最多有两个子树的有序树
-
Python常见数据结构详解
本文详细罗列归纳了Python常见数据结构,并附以实例加以说明,相信对读者有一定的参考借鉴价值. 总体而言Python中常见的数据结构可以统称为容器(container).而序列(如列表和元组).映射(如字典)以及集合(set)是三类主要的容器. 一.序列(列表.元组和字符串) 序列中的每个元素都有自己的编号.Python中有6种内建的序列.其中列表和元组是最常见的类型.其他包括字符串.Unicode字符串.buffer对象和xrange对象.下面重点介绍下列表.元组和字符串. 1.列表 列表是
-
Python实现基本线性数据结构
数组 数组的设计 数组设计之初是在形式上依赖内存分配而成的,所以必须在使用前预先请求空间.这使得数组有以下特性: 1.请求空间以后大小固定,不能再改变(数据溢出问题): 2.在内存中有空间连续性的表现,中间不会存在其他程序需要调用的数据,为此数组的专用内存空间: 3.在旧式编程语言中(如有中阶语言之称的C),程序不会对数组的操作做下界判断,也就有潜在的越界操作的风险(比如会把数据写在运行中程序需要调用的核心部分的内存上). 因为简单数组强烈倚赖电脑硬件之内存,所以不适用于现代的程序设计.欲使用可
-
Python中列表、字典、元组、集合数据结构整理
本文详细归纳整理了Python中列表.字典.元组.集合数据结构.分享给大家供大家参考.具体分析如下: 列表: 复制代码 代码如下: shoplist = ['apple', 'mango', 'carrot', 'banana'] 字典: 复制代码 代码如下: di = {'a':123,'b':'something'} 集合: 复制代码 代码如下: jihe = {'apple','pear','apple'} 元组: 复制代码 代码如下: t = 123,456,'hello' 1.列表 空
-

python实现bitmap数据结构详解
bitmap是很常用的数据结构,比如用于Bloom Filter中:用于无重复整数的排序等等.bitmap通常基于数组来实现,数组中每个元素可以看成是一系列二进制数,所有元素组成更大的二进制集合.对于Python来说,整数类型默认是有符号类型,所以一个整数的可用位数为31位. bitmap实现思路 bitmap是用于对每一位进行操作.举例来说,一个Python数组包含4个32位有符号整型,则总共可用位为4 * 31 = 124位.如果要在第90个二进制位上操作,则要先获取到操作数组的第几个元素,
-
python数据结构之二叉树的建立实例
先建立二叉树节点,有一个data数据域,left,right 两个指针域 复制代码 代码如下: # -*- coding: utf - 8 - *- class TreeNode(object): def __init__(self, left=0, right=0, data=0): self.left = left self.right = right self.data = data 复制代码 代码如下: class BTree(object):
-
python数据结构之二叉树的遍历实例
遍历方案 从二叉树的递归定义可知,一棵非空的二叉树由根结点及左.右子树这三个基本部分组成.因此,在任一给定结点上,可以按某种次序执行三个操作: 1).访问结点本身(N) 2).遍历该结点的左子树(L) 3).遍历该结点的右子树(R) 有次序: NLR.LNR.LRN 遍历的命名 根据访问结点操作发生位置命名:NLR:前序遍历(PreorderTraversal亦称(先序遍历)) --访问结点的操作发生在遍历其左右子树之前.LNR:中序遍历(InorderTraversal)
-
C#数据结构与算法揭秘二 线性结构
上文对数据结构与算法,有了一个简单的概述与介绍,这篇文章,我们介绍一中典型数据结构--线性结构. 什么是线性结构,线性结构是最简单.最基本.最常用的数据结构.线性表是线性结构的抽象(Abstract), 线性结构的特点是结构中的数据元素之间存在一对一的线性关系. 这 种一对一的关系指的是数据元素之间的位置关系,即: (1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素: (2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素.也就是说,数据元素是一个接一个的排
-
数据结构简明备忘录 线性表
线性表 线性表是线性结构的抽象,线性结构的特点是结构中的数据元素之间存在一对一的线性关系. 数据元素之间的位置关系是一个接一个的排列: .除第一个位置的数据元素外,其他数据元素位置的前面都只有一个数据元素. .除最后一个位置的外,其他数据元素位置的后面都只有一个元素. 线性表通常表示为:L=(D,R) D是数据元素的有限集合 R是数据元素之间关系的有限集合 线性表的基本操作: 复制代码 代码如下: public interface IListDS<T> { int GetLength(); /
-
Java数据结构之线性表
线性表是其组成元素间具有线性关系的一种数据结构,对线性表的基本操作主要有,获取元素,设置元素值,遍历,插入,删除,查找,替换,排序等.而线性表可以采用顺序储存结构和链式储存结构,本节主要讲解顺序表.单链表以及双链表的各种基本操作. 1:线性表抽象的数据类型 线性表:是由n(n>=0)个数据相同的元素组成的有限序列.线性表的定义接口如下 public interface IList<T> { /** * 是否为空 * @return */ boolean isEmpty(); /** *
-
JS实现线性表的顺序表示方法示例【经典数据结构】
本文实例讲述了JS实现线性表的顺序表示方法.分享给大家供大家参考,具体如下: 线性表的顺序表示指的是用一组地址连接的存储单元依次存储线性表的数据元素.通常称这种存储结构的线性表为顺序表. 顺序表的特点是以元素在计算机内物理位置相邻来表示数据元素之间的逻辑关系.每一个数据元素的存储位置都和线性表的起始位置相差一个和数据元素在线性表中的位序成正比的常数.也就是说只要确定了存储线性表的起始位置,线性表中的任一元素都可以随机存储,所以说,顺序表是一种随机存取的存储结构. 高级语言中的数组与其相似,所以我
-
C++ 数据结构线性表-数组实现
C++ 数据结构线性表-数组实现 线性表的数组实现,实现几个核心的功能,语言是C++,如果有更好的想法和意见,欢迎留言~~~ /* Author : Moyiii * 线性表的数组实现,仅作学习之用,当然如果 * 你想拿去用,随你好啦. */ #include<iostream> using namespace std; //顺序表 class SeqList { public: //构造函数,接受一个默认的列表大小 SeqList(int size = MAX_LIST_SIZE); //析
-
Java数据结构(线性表)详解
线性表的链式存储与实现 实现线性表的另一种方法是链式存储,即用指针将存储线性表中数据元素的那些单元依次串联在一起.这种方法避免了在数组中用连续的单元存储元素的缺点,因而在执行插入或 删除运算时,不再需要移动元素来腾出空间或填补空缺.然而我们为此付出的代价是,需要在每个单元中设置指针来表示表中元素之间的逻辑关系,因而增加了额外的存储空间的开销. 单链表 链表是一系列的存储数据元素的单元通过指针串接起来形成的,因此每个单元至少有两个域,一个域用于数据元素的存储,另一个域是指向其他单元的指针.这里具有
-
JS实现线性表的链式表示方法示例【经典数据结构】
本文实例讲述了JS实现线性表的链式表示方法.分享给大家供大家参考,具体如下: 从上一节可以,顺序存储结构的弱点就是在插入或删除操作时,需要移动大量元素.所以这里需要介绍一下链式存储结构,由于它不要求逻辑上相邻的元素在物理位置上也相邻,所以它没有顺序存储结构的弱点,但是也没有顺序表可随机存取的优点. 下面介绍一下什么是链表. 线性表的链式存储结构用一组任意的存储单元存储线性表的数据元素.所以,每一个数据元素除了存储自身的信息之外,还需要存储一个指向其后继的存储位置的信息.这两部分信息组成了元素的存
-
python数据结构之线性表的顺序存储结构
用Python仿照C语言来实现线性表的顺序存储结构,供大家参考,具体内容如下 本文所采用的数据结构模板为 <数据结构教程>C语言版,李春葆.尹为民等著. 该篇所涉及到的是线性表的顺序存储结构. 代码: # !/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'MrHero' class Node(object): """ 线性表的存储结构 和 C 语言中的链式存储结构类似 ""&q
-
php数据结构之顺序链表与链式线性表示例
本文实例讲述了php数据结构之顺序链表与链式线性表.分享给大家供大家参考,具体如下: 链表操作 1. InitList(L):初始化链表 2. DestroyList(L):删除连接 3. ClearList(L):清空链表 4. ListEmpty(L):判断是否为空 5. ListLength(L):链表长度 6. getElem(L,i):取出元素 7. LocateElem(L,e):判断e是否在链表中 8. PriorEl
-
C语言编程数据结构线性表之顺序表和链表原理分析
目录 线性表的定义和特点 线性结构的特点 线性表 顺序存储 顺序表的元素类型定义 顺序表的增删查改 初始化顺序表 扩容顺序表 尾插法增加元素 头插法 任意位置删除 任意位置添加 线性表的链式存储 数据域与指针域 初始化链表 尾插法增加链表结点 头插法添加链表结点 打印链表 任意位置的删除 双向链表 测试双向链表(主函数) 初始化双向链表 头插法插入元素 尾插法插入元素 尾删法删除结点 头删法删除结点 doubly-Linked list.c文件 doubly-Linkedlist.h 线性表的定
-
C语言数据结构之线性表的链式存储结构
1.什么是线性表的链式存储结构 -链表 存储结点:包括元素本身的信息,还有元素之间的关系逻辑的信息 这个结点有:数据域和指针域 一个指针域:指向后继结点, 单链表 二个指针域: 指向前继结点,还有一个指向后继结点 双链表 2.原理是: s=(LinkNode *)malloc(sizeof(LinkNode));// s->data=e; //这里赋值了 s->next=p->next; // p->next=s; //这里把指针s给到了p 结点a-> 结点b -> 结