postgresql13主从搭建Ubuntu
目录
- 数据库安装基本设置
- 设置环境变量
- 主库创建流复制的用户
- 从库设置+从主库进行数据流复制
- 从库进行数据流复制之后,重启从库,主从模式正式工作
- 查看主从运行状态
- 主备切换
- 备->主
- 主->备
数据库安装基本设置
先安装完数据库以后,安装路径如下:
数据库安装完毕以后,
服务的安装路径为:/usr/lib/postgresql/13/bin/
数据路径为:/var/lib/postgresql/13/main/
配置文件路径为:/etc/postgresql/13/main/
pg_hba.config路径为:/etc/postgresql/13/main/postgresql.conf # postgres用户密码修改 #修改postgres密码为123456 passwd postgres #在输入密码的位置输入密码123456 #切换到postgres用户 su - postgres #修改数据库账号postgres的密码为123456 psql -c "alter user postgres with password '123456';" exit
设置环境变量
vi /etc/profile 在最后增加 export PGDATA=/var/lib/postgresql/13/main/ export PATH=$PATH:$HOME/bin:$PGDATA:/usr/lib/postgresql/13/bin 保存后,使环境变量立即生效 source /etc/profile
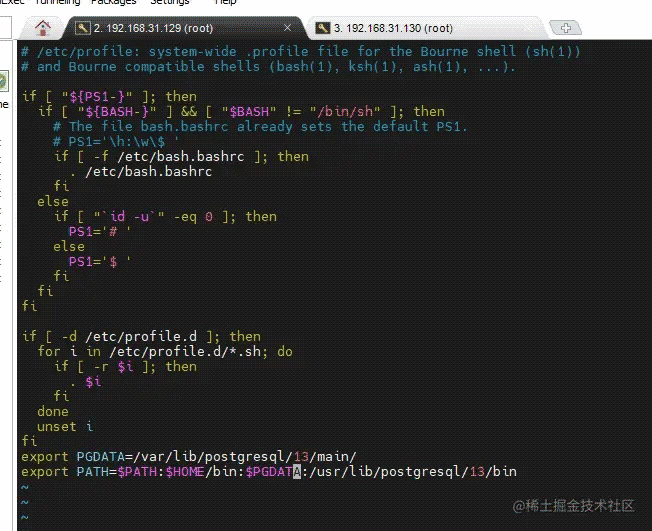
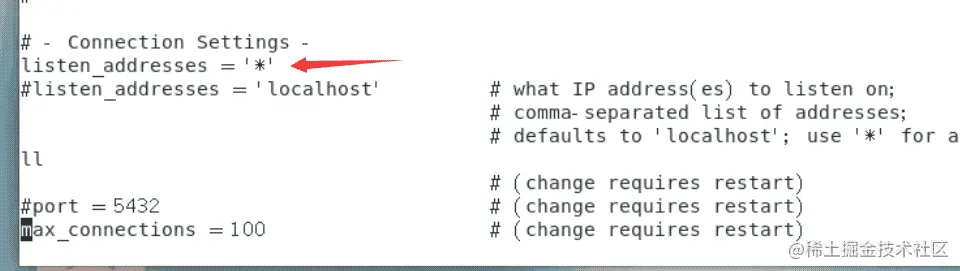
#设置允许远程连接 #编辑postgresql.conf配置文件 vi /etc/postgresql/13/main/postgresql.conf #增加允许任何用户连接,新增 listen_addresses = '*' #设置从库复制槽名称为pgstandby1,设置了复制槽名称以后,复制流将由异步变为同步 synchronous_standby_names = 'pgstandby1' #保存修改 Esc :wq

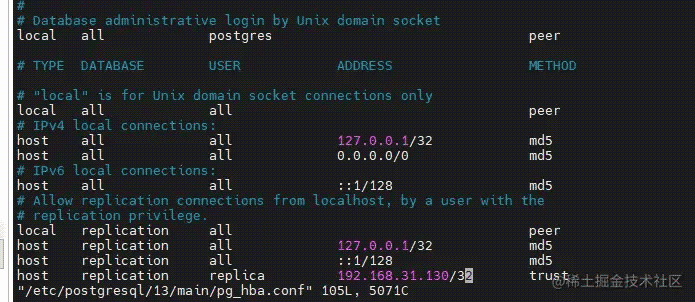
#修改配置文件pg_hba.conf,设置访问规则 #编辑pg_hba.conf配置文件 vi /etc/postgresql/13/main/pg_hba.conf #新增 host all all 0.0.0.0/0 md5 访问规则,并修改加密方式为md5(设置允许任何客户端远程连接) #新增 host replication replica 192.168.31.130/32 trust(设置允许replica用户由主库复制到从库,其中ip为从库的ip) #保存修改 Esc :wq
主库创建流复制的用户
su - postgres psql -c "CREATE ROLE replica login replication encrypted password 'replica'"; exit; systemctl restart postgresql
至此,主库设置就完成了,介于将来主库、从库会进行提级和降级操作或者主从互换操作,所以建议对从库也进行相同的主库设置
从库设置+从主库进行数据流复制
pg_basebackup -h 192.168.31.129 -D $PGDATA -U replica -P -X stream -R -C -S pgstandby1
其中:
-h指向主库的ip,
-D指数据从主库复制到从库的路径
-U指用户名,即从库以replica的用户进行流复制
-P表示显示流复制的过程
-X表示复制方式,stream表示以流的方式进行
-R表示创建一个standby.signal文件,该文件作为一个从库的标识文件,存在此文件,则表示从库
-C指定在启动备份之前应创建由--slot选项命名的复制插槽。如果插槽已存在,则会引发错误。即pgstandby1表示插槽的名称。主库、备库指定插槽名称后,流复制为同步复制,否则为异步复制。
从库进行数据流复制之后,重启从库,主从模式正式工作
systemctl restart postgresql
注:Ubuntu上使用仓库安装的postgresql从库启动,必须要使用systemctl重启,无法通过pg_ctl进行。
这时,就可以看到备库服务器上自动生成了standby.signal文件。同时,也看到在$PGDATA路径下,数据库自动帮我们配置了关于流复制的主库的信息:
$ cat $PGDATA/postgresql.auto.conf # Do not edit this file manually! # It will be overwritten by the ALTER SYSTEM command. #primary_conninfo = 'user=replica passfile=''/var/lib/postgresql/.pgpass'' channel_binding=prefer host=192.168.31.129 port=5432 sslmode=prefer sslcompression=0 sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any' primary_conninfo = 'user=replica host=192.168.31.129 port=5432 application_name=pgstandby1' primary_slot_name = 'pgstandby1'
查看主从运行状态
主从搭建后,主库运行状态为: ps -ef|grep postgres

可以看到有一个walsender在向从库发送
从库运行状态为:

可以看到有一个walreceiver在接收数据,startup recovering 000000030000000000000030也是从库的标识
通过SQL语句查看主从信息:
select * from pg_stat_replication;
select application_name, client_addr, sync_state from pg_stat_replication;
//查询复制插槽名称
SELECT * FROM pg_replication_slots
//下面这句话是删除pgstandby1复制插槽的语句
select pg_drop_replication_slot('pgstandby1');
主备切换
备->主
#在备库下执行命令 pg_ctl promote
主->备
# 在数据库的数据路径下$PGDATA,新增一个standby.signal文件 touch standby.signal 同时,也看到在$PGDATA路径下,编辑postgresql.auto.conf的主库的信息: $ vi $PGDATA/postgresql.auto.conf # Do not edit this file manually! # It will be overwritten by the ALTER SYSTEM command. primary_conninfo = 'user=replica host=192.168.31.130 port=5432 application_name=pgstandby1' primary_slot_name = 'pgstandby1' wq #重启新备库启动 systemctl restart postgresql
以上就是postgresql13主从搭建Ubuntu的详细内容,更多关于postgresql13 主从搭建的资料请关注我们其它相关文章!
相关推荐
-
开源数据库postgreSQL13在麒麟v10sp1源码安装过程详解
一.中标麒麟v10sp1在飞腾2000+系统安装略 二.系统依赖包安装 [root@ft2000db opt]# yum install bzip* [root@ft2000db opt]# nkvers ############## Kylin Linux Version ################# Release: Kylin Linux Advanced Server release V10 (Tercel) Kernel: 4.19.90-17.ky10.aarch64 Buil
-

PostgreSQL13基于流复制搭建后备服务器的方法
目录 实际操作 1.参数配置 2.使用pg_basebackup创建备机数据库 3.启动备机数据库服务器 4.检查 pg的高可用.负载均衡和复制特性矩阵如下 后备服务器作为主服务器的数据备份,可以保障数据不丢,而且在主服务器发生故障后可以提升为主服务器继续提供服务. 实际操作 1.参数配置 首先配置主机的postgresql.conf vim /usr/local/pgsql/data/postgresql.conf listen_addresses = '*' wal_level = hot_
-
postgresql数据库安装部署搭建主从节点的详细过程(业务库)
操作系统 64位CentOS 7 数据库搭建 一 业务数据库搭建 1. 安装 yum源(服务器可访问互联网时用) yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm 2. 安装客户端 yum install postgresql11 –y 3. 安装服务端 yum install postgresql11-serve
-
教你如何在Centos8-stream安装PostgreSQL13
目录 一.安装postgresql13-server 二.初始化PostgreSQL 三.启动postgresql数据库 四.修改配置文件和创建数据库密码和数据库 五.添加远程访问权限: 六.配置开机启动数据库脚本 七.数据库定时备份脚本 一.安装postgresql13-server yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.
-
Postgresql主从异步流复制方案的深入探究
前言 数据库的备份工作在日常生产中极为重要,如果你咨询一个DBA如何才能设计出高可用的数据备份与恢复方案,相信很多人都会从架构上给出很多容灾的意见.但归根到底,如果业务环节中数据库还牵涉到分布式环境,我认为一个好的方案需要达到三大要求: 多副本 持久化 一致性 日常架构设计中,我们不仅要保证数据额的成功备份,还要保证备份的数据可以快速恢复.在众多备份恢复可靠性方案中 主从复制 技术,可以说是最常见的实现,本文主要是介绍postgresql主备数据库的异步流复制的环境搭建与主备切换的操作实践,除了
-
CentOS PostgreSQL 12 主从复制(主从切换)操作
主从复制 1. 基于文件的日志传送 创建一个高可用性(HA)集群配置可采用连续归档,集群中主服务器工作在连续归档模式下,备服务器工作在连续恢复模式下(1台或多台可随时接管主服务器),备持续从主服务器读取WAL文件. 连续归档不需要对数据库表做任何改动,可有效降低管理开销,对主服务器的性能影响也相对较低. 直接从一个数据库服务器移动WAL记录到另一台服务器被称为日志传送,PostgreSQL通过一次一文件(WAL段)的WAL记录传输实现了基于文件的日志传送. 日志传送所需的带宽取根据主服务器的事务
-
Postgresql 检查数据库主从复制进度的操作
如何查看主从复制的状态,且备库应用落后了多少字节 这些信息要在主库中查询 查看流复制的信息可以使用主库上的视图 select pid,state,client_addr,sync_priority,sync_state from pg_stat_replication; pg_stat_replication中几个字断记录了发送wal的位置及备库接收到的wal的位置. sent_location--发送wal的位置 write_location--备库接收到的wal的位置 flush_locat
-
postgresql13主从搭建Ubuntu
目录 数据库安装基本设置 设置环境变量 主库创建流复制的用户 从库设置+从主库进行数据流复制 从库进行数据流复制之后,重启从库,主从模式正式工作 查看主从运行状态 主备切换 备->主 主->备 数据库安装基本设置 先安装完数据库以后,安装路径如下: 数据库安装完毕以后, 服务的安装路径为:/usr/lib/postgresql/13/bin/ 数据路径为:/var/lib/postgresql/13/main/ 配置文件路径为:/etc/postgresql/13/main/ pg_hba.c
-
MySQL主从搭建(多主一从)的实现思路与步骤
背景: 由于最近公司项目好像有点受不住并发压力了,优化迫在眉睫.由于当前系统是单数据库系统原因,能优化的地方也尽力优化了但是数据库瓶颈还是严重限制了项目的并发能力.所以就考虑了添加数据库来增大项目并发能力. 思路: 1: 创建集中库: 主要就是存储历史数据.作为查询使用. 2:创建多个业务库:满足项目高并发的能力. demo环境: 1: VM ware 虚拟机 - centOS 7 centOS-1: 192.168.194.3 主 100-------业务库 centOS-2: 192.168
-
mysql5.6主从搭建以及不同步问题详解
目录 一.mysql主从复制原理 二.mysql编译安装 三.主从配置 四.主从不同步 系统:centos6.6 主:192.168.142.129 mysql-5.6.30.tar.gz 从:192.168.142.130 192.168.142.131 mysql-5.6.30.tar.gz 一.mysql主从复制原理 (1) master将改变记录到二进制日志(binary log)中: (2) slave将master的binary log events拷贝到它的中继日志(relay l
-
MySQL基于GTID主从搭建
目录 一.用xtarbackup备份数据库 1.1 优势 1.2 安装 1.3 使用 1.3.1 普通备份 1.3.2 tar备份 1.3.3 xbstream备份 1.3.4 恢复 二.基于GTID做数据同步 2.1 GTID的概念 2.2 GTID的组成 2.3 GTID的原理 2.4 GTID的优势 2.5 具体搭建过程 2.5.1 开启主(master)Gtid 2.5.2 在master上进行数据备份 2.5.3 解压备份的数据 2.5.4 配置slave的配置文件 2.5.5 恢复数
-
详解搭建ubuntu版hadoop集群
用到的工具:VMware.hadoop-2.7.2.tar.jdk-8u65-linux-x64.tar.ubuntu-16.04-desktop-amd64.iso 1. 在VMware上安装ubuntu-16.04-desktop-amd64.iso 单击"创建虚拟机"è选择"典型(推荐安装)"è单击"下一步" è点击完成 修改/etc/hostname vim hostname 保存退出 修改etc/hosts 127.0.0.1 loc
-
用Shell脚本快速搭建Ubuntu下的Nodejs开发环境
nodejs的确是很火,以前倒腾过,但是从来没有认真记录下什么.在ubuntu下搭建它的开发环境尝尝鲜,有一个捷径,它能让系统自动帮你安装所需要的东西,我们生成一段shell脚本,让它来完成以下工作: 安装 git下最新的node,node包管理器,Forever和Cloud9IDE工具(可选),mongodb 10gen:注:脚本的正常运行需要比较新版本的Ubuntu,而且需要联网,因为它会连接网络去下载所有的依赖包顺序安装. 1.脚本代码: 复制代码 代码如下: #!/bin/shecho
-
Centos7 Redis主从搭建配置的实现
一.环境介绍 Redis-master 172.18.8.19 Redis-slave 172.18.8.20 二.redis主的配置 #创建redis数据目录 mkdir -p /data0/redis_trade #redis主配置文件 root># cat redis_6379.conf |grep -Ev "^$|^#" bind 172.18.8.19 protected-mode yes port 6379 tcp-backlog 511 timeout 0
-
Django搭建MySQL主从实现读写分离
目录 一.MySQL主从搭建 操作步骤 二.Django实现读写分离 自动指定 一.MySQL主从搭建 主从配置原理: 主库写日志到 BinLog 从库开个 IO 线程读取主库的 BinLog 日志,并写入 RelayLog 再开一个 SQL 线程,读 RelayLog 日志,回放到从库中 主从配置流程: master 会将变动记录到二进制日志里面: master 有一个 I/O 线程将二进制日志发送到 slave: salve 有一个 I/O 线程把 master 发送的二进制写入到 rela
-
MySQL 搭建主从同步实现操作
目录 一.MySQL8.0主从同步 二.MySQL主从搭建 2.1Master上的操作 2.2Slave上的操作 一.MySQL 8.0 主从同步 主从同步的流程(原理): master 将变动记录到二进制日志文件(binary log)中,即配置文件中 log-bin 指定的文件,这些记录叫做二进制日志事件(binary log events): master 将二进制日志文件发送给 slave: slave 通过 I/O 线程读取文件中的内容写到 relay 日志中: slave 执行 re
-
基于Docker搭建Redis一主两从三哨兵的实现
这段时间正在学习Redis和容器相关的内容,因此想通过docker搭建一套redis主从系统来加深理解.看这篇文章可能你需要一定的docker基础,以及对redis主从和哨兵机制有所了解. 这次实验准备了三台云主机,系统为Debian,ip分别为: 35.236.172.131 , 35.201.200.251, 34.80.172.42. 首先分别在这三台主机上安装docker,然后每台主机上启动一个redis容器,运行redis-server服务,其中35.236.172.131作为mast