selenium跳过webdriver检测并模拟登录淘宝
简介
模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网站的升级,采取该策略比较难实现了。因为你使用get/post方式进行爬取数据,会提示需要登录,而登录又是一大难题,需要滑动验证码验证。当你想使用IP代理池进行跳过检验时,发现登录时需要手机短信验证码验证,由此可以知道旧的全自动爬取数据对于大型网站比较困难了。
selenium是一款优秀的WEB自动化测试工具,所以现在采用selenium进行半自动化爬取数据,支持模拟登录淘宝和自动处理滑动验证码。
编写思路
由于现在大型网站对selenium工具进行检测,若检测到selenium,则判定为机器人,访问被拒绝。所以第一步是要防止被检测出为机器人,如何防止被检测到呢?当使用selenium进行自动化操作时,在chrome浏览器中的consloe中输入windows.navigator.webdriver会发现结果为Ture,而正常使用浏览器的时候该值为False。所以我们将windows.navigator.webdriver进行屏蔽。
在代码中添加:
options = webdriver.ChromeOptions()
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
同时,为了加快爬取速度,我们将浏览器模式设置为不加载图片,在代码中添加:
options = webdriver.ChromeOptions()
# 不加载图片,加快访问速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
至此,关键的步骤我们已经懂了,剩下的就是编写代码的事情了。在给定的例子中,需要你对html、css有一定了解。
比如存在以下代码:
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
print(taobao_name.text)
第1行代码指的是从根目录(//)开始寻找任意(*)一个class名为btn_tip的元素,并找到btn_tip的子元素a标签中的子元素span
第2行代码指的是等待某个CSS元素出现,否则代码停留在这里一直检测。以.开头的在CSS中表示类名(class),以#开头的在CSS中表示ID名(id)。A > B,指的是A的子元素B。所以这行代码可以理解为寻找A的子元素B的子元素C的子元素D的子元素E出现,否则一直在这里检测。
第3行代码指的是打印某个元素的文本内容
使用教程
点击这里下载下载chrome浏览器
查看chrome浏览器的版本号,点击这里下载对应版本号的chromedriver驱动
pip安装下列包
[x] pip install selenium
点击这里登录微博,并通过微博绑定淘宝账号密码
在main中填写chromedriver的绝对路径
在main中填写微博账号密码
#改成你的chromedriver的完整路径地址 chromedriver_path = "/Users/bird/Desktop/chromedriver.exe" #改成你的微博账号 weibo_username = "改成你的微博账号" #改成你的微博密码 weibo_password = "改成你的微博密码"
演示图片
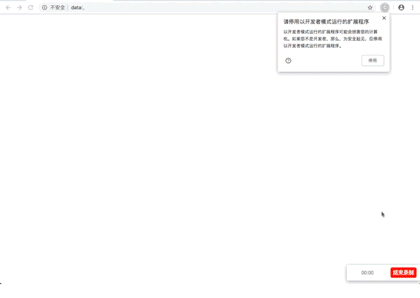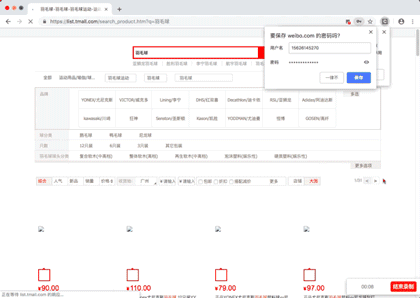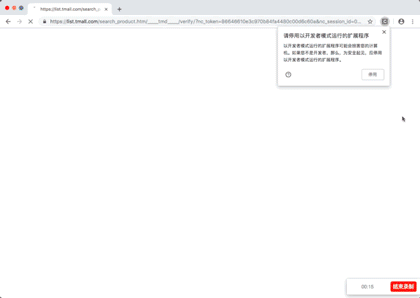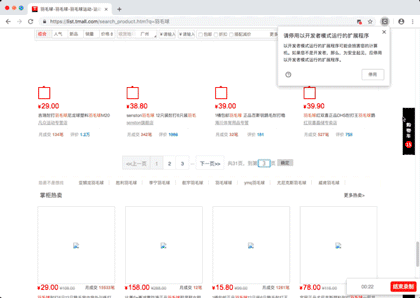
源代码
项目源代码在GitHub仓库
项目持续更新,欢迎您star本项目
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们
相关推荐
-

python使用selenium登录QQ邮箱(附带滑动解锁)
前言 最近因为工作需要 用selenium做了一个QQ邮箱的爬虫(登录时部分帐号要滑动解锁),先简单记录一下. 这个问题先可以分为两个部分:1.登录帐号和2.滑动解锁.python版本3.5.4 问题分析:登录+滑动解锁 其实登录账号的部分本来很简单,用selenium打开QQ邮箱官网:https://mail.qq.com 然后切换frame输入帐号 和密码点击登录即可,但是部分账号,或者可以说是异地登录的QQ账号需要滑动解锁验证码才能继续登录(下图) 看到这张图我们应该不难想到: 1.我们需
-
python+selenium实现登录账户后自动点击的示例
公司在codereview的时候限制了看代码的时间,实际上不少代码属于框架自动生成,并不需要花费太多时间看,为了达标,需要刷点时间(鼠标点击网页固定区域).我想到可以利用自动化测试的手段完成这种无效的体力劳动. 首先,明确一下需求: 自动打开网页 登陆账号 每隔一定时间点击一下固定区域 我想到的方案有两个,sikuli或者python+selenium.sikuli的优点是逻辑操作简单直接,使用图片作为标示,缺点是需要窗口固定,并且无法后台运行.selenium稍复杂一定,但是运行速度快,窗口可
-
selenium+python实现自动登录脚本
os:windows 前提:Python,selenium,IEDriverServer.exe,ie浏览器 首先安装Python2.7 安装成功后,计算机联网状态下在cmd命令行下输入:pip install -U selenium selenium安装后,在selenium官网下载IEDriverServer.exe 将IEDriverServer.exe放到ie浏览器的安装目录下:C:\Program Files (x86)\Internet Explorer,并将该目录添加到计算机的环境
-
Python Selenium Cookie 绕过验证码实现登录示例代码
之前介绍过通过cookie 绕过验证码实现登录的方法.这里并不多余,会增加分析和另外一种方法实现登录. 1.思路介绍 1.1.直接看代码,内有详细注释说明 # FileName : Wm_Cookie_Login.py # Author : Adil # DateTime : 2018/3/20 19:47 # SoftWare : PyCharm from selenium import webdriver import time url = 'https://system.address'
-
使用selenium模拟登录解决滑块验证问题的实现
本次主要是使用selenium模拟登录网页端的TX新闻,本来最开始是模拟请求的,但是某一天突然发现,部分账号需要经过滑块验证才能正常登录,如果还是模拟请求,需要的参数太多了,找的心累.不过好在TX的滑块验证是他们自己开发的,没有极验那么复杂,当然相反的,想要模拟就得自己去一点点探索了,毕竟对极验滑块的破解,网上已经可以找到现成的代码来用了.下面说一下模拟的实现过程和我遇见的问题. 1.登录入口 我是通过点击打开链接来当做登录入口的 部分代码实现: driver = webdriver.Chrom
-
Python使用selenium实现网页用户名 密码 验证码自动登录功能
好久没有学python了,反正各种理由吧(懒惰总会有千千万万的理由),最近网上学习了一下selenium,实现了一个简单的自动登录网页,具体如下. 1.安装selenium: 如果你已经安装好anaconda3,直接在windows的dos窗口输入命令安装selenium: python -m pip install --upgrade pip 查看版本pip show selenium 2.接着去http://chromedriver.storage.googleapis.com/index.
-
python+selenium识别验证码并登录的示例代码
由于工作需要,登录网站需要用到验证码.最初是研究过验证码识别的,但是总是不能获取到我需要的那个验证码.直到这周五,才想起这事来,昨天顺利的解决了. 下面正题: python版本:3.4.3 所需要的代码库:PIL,selenium,tesseract 先上代码: #coding:utf-8 import subprocess from PIL import Image from PIL import ImageOps from selenium import webdriver import t
-
python+selenium实现京东自动登录及秒杀功能
本文实例为大家分享了selenium+python京东自动登录及秒杀的代码,供大家参考,具体内容如下 运行环境: python 2.7 python安装selenium 安装webdriver(这里是firefox) 其中selenium可以采用pip安装: pip install selenium webdriver下载地址 需要注意的是,webdriver的目录.对应浏览器的目录,都要添加到path. 代码如下: # _*_coding:utf-8_*_ from selenium impo
-
selenium+python实现自动化登录的方法
Selenium Python 提供了一个简单的API 便于我们使用 Selenium WebDriver编写 功能/验收测试. 通过Selenium Python的API,你可以直观地使用所有的 Selenium WebDriver 功能 .Selenium Python提供了一个很方便的接口来驱动 Selenium WebDriver , 例如Firefox.Chrome.Ie,以及Remote,目前支持的python版本有2.7或3.2以上. selenium 可以自动化测试.抢票.爬虫等
-
Python selenium实现微博自动登录的示例代码
(一)编程环境 操作系统:Win 10 编程语言:Python 3.6 (二)安装selenium 这里使用selenium实现. 如果没有安装过python的selenium库,则安装命令如下 pip install selenium (三)下载ChromeDriver 因为selenium要用到浏览器的驱动,这里我用的是Google Chrome浏览器,所以要先下载ChromeDriver.exe并放到C:\Program Files (x86)\Google\Chrome\Applicat