使用selenium模拟登录解决滑块验证问题的实现
本次主要是使用selenium模拟登录网页端的TX新闻,本来最开始是模拟请求的,但是某一天突然发现,部分账号需要经过滑块验证才能正常登录,如果还是模拟请求,需要的参数太多了,找的心累。不过好在TX的滑块验证是他们自己开发的,没有极验那么复杂,当然相反的,想要模拟就得自己去一点点探索了,毕竟对极验滑块的破解,网上已经可以找到现成的代码来用了。下面说一下模拟的实现过程和我遇见的问题。
1.登录入口
我是通过点击打开链接来当做登录入口的
部分代码实现:
driver = webdriver.Chrome() driver.get(url)
2.点击“账号密码登录”
selenium可以实现对网页元素的定位,我这里是通过id属性来定位“帐号密码登录”按钮的。这里需要注意的是,有时候可能会因为网络不好等问题导致加载登录入口页会很慢,所以在点击“帐号密码登录”按钮前,需要做一个判断:判断代表“帐号密码登录”的HTML元素是否已经加载完成。
“账号密码登录”按钮的id属性截图:

部分代码实现:
element = WebDriverWait(driver, 5, 0.5).until( EC.presence_of_element_located((By.ID, "switcher_plogin")) ) # from selenium.webdriver.common.by import By element.click()
3.输入账号、密码并点击登录
这一步比较简单,直接上代码:
driver.find_element_by_id('u').send_keys('123456') # 输入用户名
driver.find_element_by_id('p').send_keys('ccccc') # 输入密码
driver.find_element_by_id('login_button').click() # 点击登录
4.滑块验证过程
1)简要说明
因为主要目的就是为了模拟滑块验证,所以在输入用户名和密码的时候直接选择输入“123456”和“ccccc”,这样就必然会跳到滑块验证的页面:

接下来的问题就是如何模拟滑动的过程。这里首先要说一下,经过多次测试发现,TX的滑块验证每次需要拖动的距离是有一定范围的,“缺口”部分的位置基本上都在靠右侧的一面,不像极验的滑块验证,“缺口”部分可能出现在任意的位置,这样在实现“滑动”过程前,就必须判断每次滑动的距离是多少。所以,对于TX的滑块验证,只要设置一个大概的距离“模拟滑动”即可,失败的时候可以通过增减移动距离进行重试,后面会进一步说明。
2)为什么找不到“蓝色滑块”
前面已经点击了“登录”并跳转到“安全验证”的页面,接着就是去模拟“拖动”截图中的“蓝色滑块”,所以首先要告诉driver,代表“蓝色滑块”的html元素是什么。代表“蓝色滑块”的html元素截图:

通过上面的截图可以知道,id值为"tcaptcha_drag_button"的div标签代表的就是“蓝色滑块”,所以最开始我是直接尝试去拖动它,但是这时候发现报错了,部分截图如下:
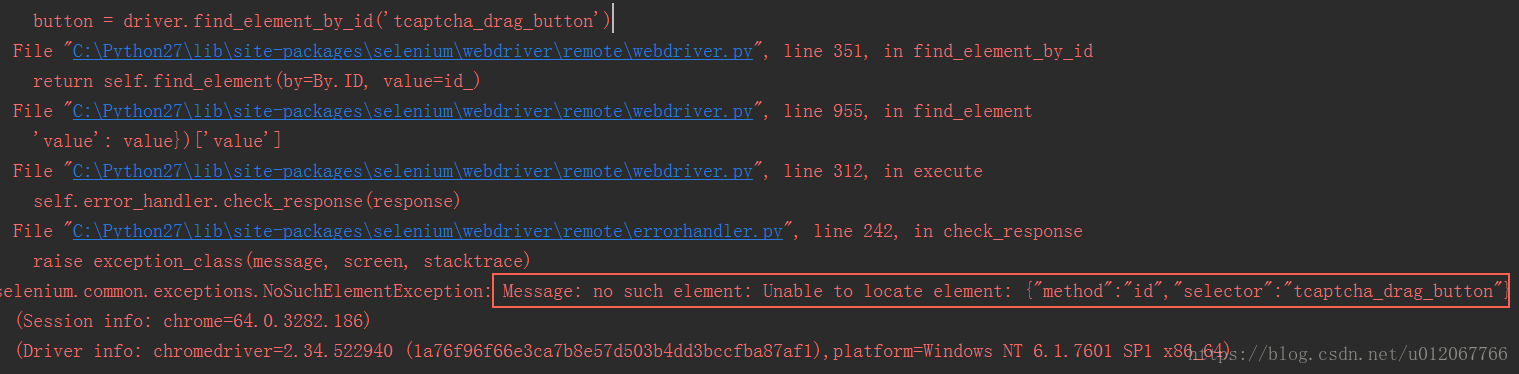
报错的原因很明显,在当前得到的所有html元素中,找不到id值为"tcaptcha_drag_button"的div标签。这是为什么?
3)切换frame
为什么出现上面的问题?通过查找相关的资料才知道,在跳转到“安全验证”的页面的时候,“进入”了一个新的frame,可以理解为,在“登录页面”嵌套了一个“验证页面”,而当前的driver加载的html元素全部都是“登录页面”的,想要找到并拖动“蓝色滑块”,就要先切换到“验证页面”,这里通过driver.switch_to方法实现:
iframe = driver.find_element_by_xpath('//iframe') # 找到“嵌套”的iframe
driver.switch_to.frame(iframe) # 切换到iframe
4)模拟拖动
切换到iframe之后,就可以通过driver.find_element_by_id('tcaptcha_drag_button')找到“蓝色滑块”并拖动它了。拖动操作会用到selenium.webdriver的ActionChains类,部分代码如下:
button = driver.find_element_by_id('tcaptcha_drag_button') # 找到“蓝色滑块”
action = ActionChains(driver) # 实例化一个action对象
action.click_and_hold(button).perform() # perform()用来执行ActionChains中存储的行为
action.reset_actions()
action.move_by_offset(180, 0).perform() # 移动滑块
5)构造移动轨迹
为了使拖动过程模拟的更“真实”,可以构造一个滑动轨迹,我这里也是参考了别人的代码看这里,简单实现了一下,实际上TX新闻的滑块验证对这方面好像要求不是很严格:
def get_track(distance): track = [] current = 0 mid = distance * 3 / 4 t = 0.2 v = 0 while current < distance: if current < mid: a = 2 else: a = -3 v0 = v v = v0 + a * t move = v0 * t + 1 / 2 * a * t * t current += move track.append(round(move)) return track
6)如何确定已经“验证成功”了
接下来的问题就是,我如何告诉程序,已经“验证成功”了呢?经过测试发现,当拖动滑块完成拼图“验证成功”后,网页又从“安全验证”的页面又跳回了“登录页面”,滑动前截图:

滑动验证成功的截图:
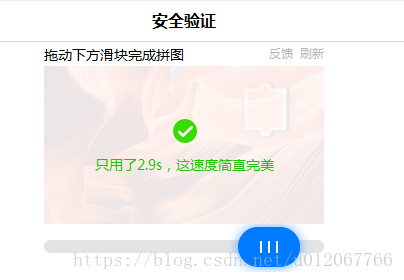
成功后跳转回“登录”页面:

通过上面的截图我们可以知道,在“验证通过”之前,在“安全验证”页面我们一直可以看到“拖动下方滑块完成拼图”的文字提示,也就是说,如果验证没有通过,那么在当前的所有html元素中,我们是可以找到文本为“拖动下方滑块完成拼图”的标签的:
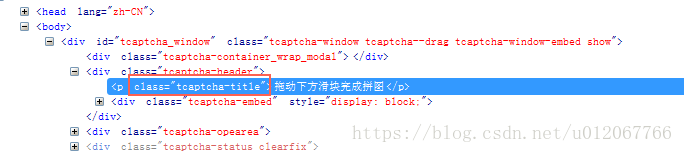
通过截图可以知道,该标签的class为"tcaptcha-title",通过driver.find_element_by_class_name('tcaptcha-title').text来判断验证是否成功。
7)重试
前面说了,我们可以通过提前设置一个“可能的”值当初始距离来移动滑块,如果移动的距离“过长”,就减小该值当做下次移动的距离,所以可以加一个while循环。以上过程实现的完整代码如下:
# encoding=utf8
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
url = 'https://xui.ptlogin2.qq.com/cgi-bin/xlogin?&low_login=0&appid=636014201&target=self&border_radius=1&maskOpacity=40&s_url=http%3A//www.qq.com/qq2012/loginSuccess.htm'
def get_track(distance):
track = []
current = 0
mid = distance * 3 / 4
t = 0.2
v = 0
while current < distance:
if current < mid:
a = 2
else:
a = -3
v0 = v
v = v0 + a * t
move = v0 * t + 1 / 2 * a * t * t
current += move
track.append(round(move))
return track
def main():
driver = webdriver.Chrome()
driver.set_window_position(900, 10)
driver.get(url)
# 检测id为"switcher_plogin"的元素是否加在DOM树中,如果出现了才能正常向下执行
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, "switcher_plogin"))
)
element.click()
sleep(1)
# 输入用户名和密码
driver.find_element_by_id('u').clear()
driver.find_element_by_id('u').send_keys('123456')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('ccccc')
sleep(1)
# 点击登录
driver.find_element_by_id('login_button').click()
sleep(5)
# 切换iframe
try:
iframe = driver.find_element_by_xpath('//iframe')
except Exception as e:
print 'get iframe failed: ', e
sleep(2) # 等待资源加载
driver.switch_to.frame(iframe)
# 等待图片加载出来
WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, "tcaptcha_drag_button"))
)
try:
button = driver.find_element_by_id('tcaptcha_drag_button')
except Exception as e:
print 'get button failed: ', e
sleep(1)
# 开始拖动 perform()用来执行ActionChains中存储的行为
flag = 0
distance = 195
offset = 5
times = 0
while 1:
action = ActionChains(driver)
action.click_and_hold(button).perform()
action.reset_actions() # 清除之前的action
print distance
track = get_track(distance)
for i in track:
action.move_by_offset(xoffset=i, yoffset=0).perform()
action.reset_actions()
sleep(0.5)
action.release().perform()
sleep(5)
# 判断某元素是否被加载到DOM树里,并不代表该元素一定可见
try:
alert = driver.find_element_by_class_name('tcaptcha-title').text
except Exception as e:
print 'get alert error: %s' % e
alert = ''
if alert:
print u'滑块位移需要调整: %s' % alert
distance -= offset
times += 1
sleep(5)
else:
print '滑块验证通过'
flag = 1
driver.switch_to.parent_frame() # 验证成功后跳回最外层页面
break
sleep(2)
driver.quit()
print "finish~~"
return flag
if __name__ == '__main__':
main()
5.小结
其实上面的代码还可以进一步“优化”。例如,当尝试三次滑动后如果仍然没有“验证成功”,就应该主动跳回“登录”页面,重新输入账号密码登录,进入下一次验证过程,而不是无休止的进行“滑块验证”。除此之外,以上只是对“滑块验证”部分进行了分析和模拟,实际情况是,通过了“滑块验证”后,有可能账号或密码错误了,这时候是不是应该重新输入账号密码进入新一轮验证过程呢?
所以,以上代码还有待继续完善,也欢迎看到这篇博文的人多多指正不足之处。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python2.7+selenium2实现淘宝滑块自动认证功能
本文为大家分享了python2.7+selenium2实现淘宝滑块自动认证的具体代码,供大家参考,具体内容如下 1.编译环境 操作系统:win7:语言:python2.7+selenium2:ide:pycharm:浏览器:IE10,chrome 2.1意外开始 今天登录淘宝时候发现吧密码搞忘了,选择找回密码时淘宝居然加了滑块认证. 恰巧自己也在学习selenium,就想试一试能不能实现自动拖动滑块. 2.2 度娘查找 由于自己没多少思路,第一选择就是问度娘,终于找到一篇文章,该文章使用C#实现
-
使用selenium模拟登录解决滑块验证问题的实现
本次主要是使用selenium模拟登录网页端的TX新闻,本来最开始是模拟请求的,但是某一天突然发现,部分账号需要经过滑块验证才能正常登录,如果还是模拟请求,需要的参数太多了,找的心累.不过好在TX的滑块验证是他们自己开发的,没有极验那么复杂,当然相反的,想要模拟就得自己去一点点探索了,毕竟对极验滑块的破解,网上已经可以找到现成的代码来用了.下面说一下模拟的实现过程和我遇见的问题. 1.登录入口 我是通过点击打开链接来当做登录入口的 部分代码实现: driver = webdriver.Chrom
-
Python模拟登录之滑块验证码的破解(实例代码)
模拟登录之滑块验证码的破解,具体代码如下所示: # 图像处理标准库 from PIL import Image # web测试 from selenium import webdriver # 鼠标操作 from selenium.webdriver.common.action_chains import ActionChains # 等待时间 产生随机数 import time, random # 滑块移动轨迹 def get_tracks1(distance): # 初速度 v = 0 #
-

vue实现登录时滑块验证
本文实例为大家分享了vue实现登录时滑块验证的具体代码,供大家参考,具体内容如下 1.效果图 2. 新建 SliderCheck.vue组件 <template> <!-- 拖动验证--> <div class="slider-check-box"> <div class="slider-check" :class="rangeStatus ? 'success' : ''">
-
python爬取企查查企业信息之selenium自动模拟登录企查查
最近接了个小项目需要批量搜索企查查上的相关企业并把指定信息保存到Excel文件中,由于企查查需要登录后才能查看所有搜索到的信息所以第一步需要模拟登录企查查. python模拟登录企查查最重要的是自动拖拽验证插件 先介绍下项目中使用到的工具与库 Python的selenium库: Web应用程序测试的工具,Selenium可以模拟用户在浏览器中的操作,就像真实用户使用一样. 官方技术文档:https://www.selenium.dev/selenium/docs/api/py/index.htm
-
python3.7+selenium模拟淘宝登录功能的实现
在使用selenium去获取淘宝商品信息时会遇到登录界面 这个登录界面处理的难度在于滑动验证的实现,有的人使用微博登录,避免了滑动验证,那可不可以使用密码登录呢?答案是可以的 实现思路 首先导入需要的库 from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.web
-
Selenium之模拟登录铁路12306的示例代码
最近接触了一些selenium模块的相关知识,觉得还挺有意思的,于是决定亲自尝试写一些爬虫程序来强化selenium模块(一定要多尝试.多动手.多总结).本文主要使用python爬虫来模拟登录铁路12306官网.这儿得吐槽一句,铁路12306网站的反爬机制做的还是比较好. 话不多说,下面跟小墨一起来学习如何通过爬虫来实现铁路12306的登录. 一. 验证码破解 当我们输入账号和密码后,在点击登录按钮之前,还需要对验证码进行操作.对验证码的识别,已经有相关的处理平台,我们只需要借助第三方平台即可.
-
selenium+超级鹰实现模拟登录12306
最近迷上了用selenium去登陆各大网站,别说selenium真挺好用,可以轻松搞定ajax动态加载的网页,不用很费劲的去抓包查找.咳咳-跑题了,回归正题. 这次用selenium去登录12306网站,听说比较困难.我就去试了试,发现它的验证码实在是那啥-就是这样的.听头疼的. 我来说说主要的代码编写吧. 过程: 用我们的开发者工具定位到输入账号和密码的窗口,找到并send_keys driver.find_element_by_id('username').send_keys('用户名')
-
python 密码验证(滑块验证)
目录 题目描述: 解题思路/算法分析/问题及解决 实验代码 题目描述: (1)模拟登陆界面,判别用户名和密码,给出合适的提示,如果超过三次,锁定输入.用代替密码:或者最新输入显示,前面的变成:安全性措施.(2)同时添加如下图的加强验证(京东).(3)在触动滚动条时再出现空缺位置. 拓展: 增加注册页面,可供用户注册新用户 增加数字验证码区别人机 解题思路/算法分析/问题及解决 滑块验证就是将滑块的移动和图片小块的移动相绑定,在滑块松开时触发相对应的检查函数,为了有一定的容错率,设定滑块的位置与设
-
python3.8.1+selenium实现登录滑块验证功能
python3.8.1+selenium解决登录滑块验证的问题,先给大家分享一个效果图,感觉不错,可以参考实现代码. 这里的滑块是qq邮箱的截图,如图所示,可以作为同类滑块验证的参考. """ auther = "zwb",这里使用的python版本是3.8.1,selenium版本是3.141.0,webdriver是谷歌,版本是81.0.4044.138(正式版本) (64 位) webdriver各版本对应的浏览器下载地址:https://npm.t
-
python+opencv+selenium自动化登录邮箱并解决滑动验证的问题
前言 大家做自动化登录时可能都遇到过滑块验证码需要手动验证的问题,这次我们就来解决他 如下: 在我们做自动化登录时,总会遇到各种奇奇怪怪的验证码,滑块验证码就是其中最常见的一种.若我们的程序自动输入账号密码之后,还需要我们人工去滑动验证码那还能称得上是自动化吗? 那么先给大家说一下我的'解题步骤'. 1.使用selenium打开邮箱首页. 2.定位到账号密码框,键入账号密码. 3.获取验证图片,使用opencv处理返回滑块应拖动的距离. 4.创建鼠标事件,模拟拖动滑块完成验证. 需要解