Python遍历pandas数据方法总结
前言
Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法。其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单。Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合。DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式。
在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中。本文通过该例程介绍对pandas数据遍历的几种方法。
for..in循环迭代方式
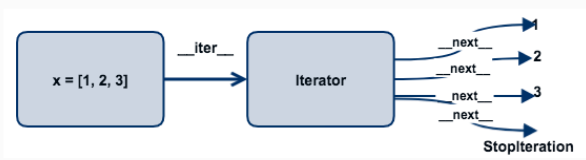
for语句是Python内置的迭代器工具,用于从可迭代容器对象(如列表、元组、字典、集合、文件等)中逐个读取元素,直到容器中没有更多元素为止,工具和对象之间只要遵循可迭代协议即可进行迭代操作。
具体的迭代的过程:可迭代对象通过__iter__方法返回迭代器,迭代器具有__next__方法,for循环不断地调用__next__方法,每次按序返回迭代器中的一个值,直到迭代到最后,没有更多元素时抛出异常StopIteration(python自动处理异常)。迭代的优点是无需把所有元素一次加载到内存中,可以在调用next方法时逐个返回元素,避免出现内存空间不够的情况。
>>> x = [1,2,3] >>> its = x.__iter__() #列表是可迭代对象,否则会提示不是迭代对象 >>> its <list_iterator object at 0x100f32198> >>> next(its) # its包含此方法,说明its是迭代器 1 >>> next(its) 2 >>>next(its) 3 >>> next(its) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
实现代码如下:
def haversine_looping(df): disftance_list = [] for i in range(0,len(df)): disftance_list.append(df.iloc[i][‘high']/df.iloc[i][‘open']) return disftance_list
关于上述代码中range的实现方法,我们也可根据迭代器协议自实现相同功能的迭代器(自带iter方法和next方法)应用在for循环中,代码如下:
class MyRange: def __init__(self, num): self.i = 0 self.num = num def __iter__(self): return self def __next__(self): if self.i < self.num: i = self.i self.i += 1 return i else: raise StopIteration() for i in MyRange(10): print(i)
我们也可以通过列表解析的方式用更少的代码实现数据处理功能
disftance_list = [df.iloc[i][‘high']/df.iloc[i][‘open'] for i in range(0,len(df))]
iterrows()生成器方式
iterrows是对dataframe行进行迭代的一个生成器,它返回每行的索引及包含行本身的对象。所谓生成器其实是一种特殊的迭代器,内部支持了迭代器协议。Python中提供生成器函数和生成器表达式两种方式实现生成器,每次请求返回一个结果,不需要一次性构建一个结果列表,节省了内存空间。
生成器函数:编写为常规的def语句,但是使用yield语句一次返回一个结果,在每个结果之间挂起和继续它们的状态。
def gensquares(N): for i in range(N): yield i**2 print gensquares(5) for i in gensquares(5): print(i) <generator object gensquares at 0xb3d37fa4> 0 1 4 9 16
生成器表达式:类似列表解析,按需产生结果的一个对象。
print (x**2 for x in range(5)) print list(x**2 for x in range(5)) <generator object <genexpr> at 0xb3d31fa4> [0, 1, 4, 9, 16]
iterrows()实现代码如下:
def haversine_looping(df): disftance_list = [] for index,row in df.iterrows(): disftance_list.append(row[‘high']/row[‘open']) return disftance_list
iterrows代码如下,yield语句挂起该函数并向调用者发送回一组值:
def iterrows(self): columns = self.columns klass = self._constructor_sliced for k, v in zip(self.index, self.values): s = klass(v, index=columns, name=k) yield k, s
apply()方法循环方式
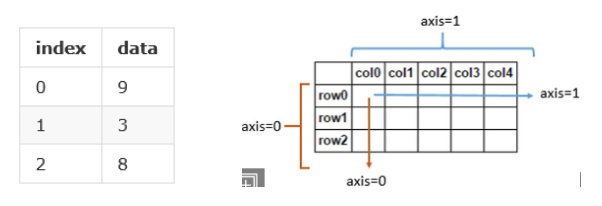
apply()方法可将函数应用于dataframe特定行或列。函数由lambda方式在代码中内嵌实现,lambda函数的末尾包含axis参数,用来告知Pandas将函数运用于行(axis = 1)或者列(axis = 0)。
实现代码如下:
df.apply(lambda row: row[‘high']/row[‘open'], axis =1)
Pandas series 的矢量化方式
Pandas的DataFrame、series基础单元数据结构基于链表,因此可将函数在整个链表上进行矢量化操作,而不用按顺序执行每个值。Pandas包括了非常丰富的矢量化函数库,我们可把整个series(列)作为参数传递,对整个链表进行计算。
实现代码如下:
dftest4['rate'] = dftest4['high']/dftest4['open']
Numpy arrays的矢量化方式
由于函数的矢量化实现中只使用了series的数值,因此可使用values 方法将链表从Pandas series转换为NumPy arrays,把NumPy array作为参数传递,对整个链表进行计算。
实现代码如下:
dftest5['rate'] = dftest5['high'].values/dftest5['open'].values
总结
使用timeit方法对以上几种遍历方式进行执行时间测试,测试结果如下。可以看出循环执行的速度是最慢的,iterrows()针对Pandas的dataframe进行了优化,相比直接循环有显著提升。apply()方法也是在行之间进行循环,但由于利用了类似Cython的迭代器的一系列全局优化,其效率要比iterrows高很多。NumPy arrays的矢量化运行速度最快,其次是Pandas series矢量化。由于矢量化是同时作用于整个序列的,可以节省更多的时间,相比使用标量操作更好,NumPy使用预编译的C代码在底层进行优化,同时也避免了Pandas series操作过程中的很多开销,例如索引、数据类型等等,因此,NumPy arrays的操作要比Pandas series快得多。
您可能感兴趣的文章:
- 对pandas的dataframe绘图并保存的实现方法
- Python科学计算之Pandas详解
- python之pandas用法大全
- python实现在pandas.DataFrame添加一行
相关推荐
-
对pandas的dataframe绘图并保存的实现方法
对dataframe绘图并保存: ax = df.plot() fig = ax.get_figure() fig.savefig('fig.png') 可以制定列,对该列各取值作统计: label_dis = df.label.value_counts() ax = label_dis.plot(title='label distribution', kind='bar', figsize=(18, 12)) fig = ax.get_figure() fig.savefig('label_d
-
python实现在pandas.DataFrame添加一行
实例如下所示: from pandas import * from random import * df = DataFrame(columns=('lib', 'qty1', 'qty2'))#生成空的pandas表 for i in range(5):#插入一行<span id="transmark" style="display:none;"></span> df.loc[i] = [randint(-1,1) for n in ran
-
python之pandas用法大全
一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1)) df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001
-

Python科学计算之Pandas详解
起步 Pandas最初被作为金融数据分析工具而开发出来,因此 pandas 为时间序列分析提供了很好的支持. Pandas 的名称来自于面板数据(panel data)和python数据分析 (data analysis) .panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型. 在我看来,对于 Numpy 以及 Matplotlib ,Pandas可以帮助创建一个非常牢固的用于数据挖掘与分析的基础.而Scipy当然是另一个主要的也十分出色的科学计
-
Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
python用pandas数据加载、存储与文件格式的实例
数据加载.存储与文件格式 pandas提供了一些用于将表格型数据读取为DataFrame对象的函数.其中read_csv和read_talbe用得最多 pandas中的解析函数: 函数 说明 read_csv 从文件.URL.文件型对象中加载带分隔符的数据,默认分隔符为逗号 read_table 从文件.URL.文件型对象中加载带分隔符的数据.默认分隔符为制表符("\t") read_fwf 读取定宽列格式数据(也就是说,没有分隔符) read_clipboard 读取剪贴板中的数据,
-
一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
python遍历目录的方法小结
本文实例总结了python遍历目录的方法.分享给大家供大家参考,具体如下: 方法一使用递归: """ def WalkDir( dir, dir_callback = None, file_callback = None ): for item in os.listdir( dir ): print item; fullpath = dir + os.sep + item if os.path.isdir( fullpath ): WalkDir( fullpath, dir
-
python遍历数组的方法小结
本文实例总结了python遍历数组的方法.分享给大家供大家参考.具体分析如下: 下面介绍两种遍历数组的方法,一种是直接通过for in 遍历数组,另外一种是通过rang函数先获得数组长度,在根据索引遍历数组 第一种,最常用的,通过for in遍历数组 colours = ["red","green","blue"] for colour in colours: print colour # red # green # blue 下面的方法可以先获
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
Python使用pandas对数据进行差分运算的方法
如下所示: >>> import pandas as pd >>> import numpy as np # 生成模拟数据 >>> df = pd.DataFrame({'a':np.random.randint(1, 100, 10),\ 'b':np.random.randint(1, 100, 10)},\ index=map(str, range(10))) >>> df a b 0 21
-
Python Pandas多种添加行列数据方法总结
目录 前言 1. 增加列数据 2. 增加行数据 补充:pandas根据现有列新添加一列 总结 前言 发现自己学习python 的各种库老是容易忘记,所有想利用这个平台,记录和分享一下学习时候的知识点,以后也能及时的复习,最近学习pandas,那我们来看看pandas添加数据的一些方法 创建一个dataframe 1. 增加列数据 为dataframe增加一列新数据,需要确保增加列的长度与原数据保持一致 如果是增加一列相同数据可以直接输入 df['level'] = 1 插入的数据是需要通过源数据
-
Python遍历目录下文件、读取、千万条数据合并详情
目录 一.使用Python进行文件和文件夹的判断 二.使用Python完整的获取所有文件及文件夹并读取相应的文件 三.使用Python合并数据 append的使用 一.使用Python进行文件和文件夹的判断 递归 :主要目的就是遍历文件夹和文件 对文件夹和文件进行属性判断 首先对文件夹进行遍历,看文件夹里有什么样的文件,读取出文件夹中的所有文件 import os path= "./data" #路径 files = os.listdir(path) #os.listdir() 方法用