使用Python对零售商品进行数据分析
目录
- 一、主要内容:
- 二、使用工具
- 三、数据来源
- 四、字段含义
- 五、数据清洗
- 1、查看总体数据特征
- 2、修改列名
- 3、检验缺失数据
- 4、查看并转换数据类型
- 5、查看异常值并删除
- 六、数据分析
- 1、总体销量数据
- 2、商品维度分析
- 3、店铺维度分析
- 4、销售情况分析
- 5、相关性分析
- 6、用户分析
一、主要内容:
1、清洗数据。将列名统一修改、处理缺失数据和异常数据、转换日期等数据类型
2、查看总体销售情况
3、商品维度进行分析。主要分析内容有:商品价格分析,商品销售量、销售额情况分析,商品关联分析
4、店铺维度进行分析。主要分析内容有:店铺销售量、销售额法分析,店铺促销情况分析,店铺销售时间分析,周均消费次数分析,客单价分析等
5、相关性分析:用关联关系表和相关矩阵图初步对变量之间的关系进行分析。
6、用户维度进行分析。主要分析内容有:分析用户基本购买情况,按时间(周)对用户购买情况进行分析,用户购买力分析,用户复购率分析,RFM区分用户。
二、使用工具
Python
三、数据来源
该数据集包含2018年6月1日-2018年7月5日的公司零售的交易信息。
四、字段含义
- SDATE(订单日期)
- STORE_CODE(商店编号)
- POSID(POS机编号)
- BASK_CODE(用户编号)
- PROD_CODE(商品编号)
- ITEM_QUANTITY(商品数量)
- ITEM_SPEND(商品实际价格)
- NORMAL_PRICE(商品单价)
- DISCOUNT_TYPE(折扣类型)
- DISCOUNT_AMOUNT(折扣金额)
五、数据清洗
1、查看总体数据特征
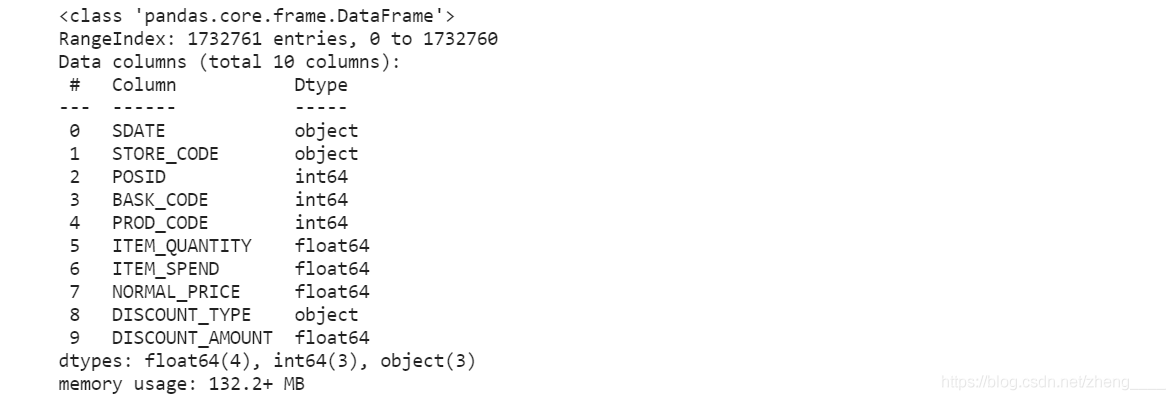
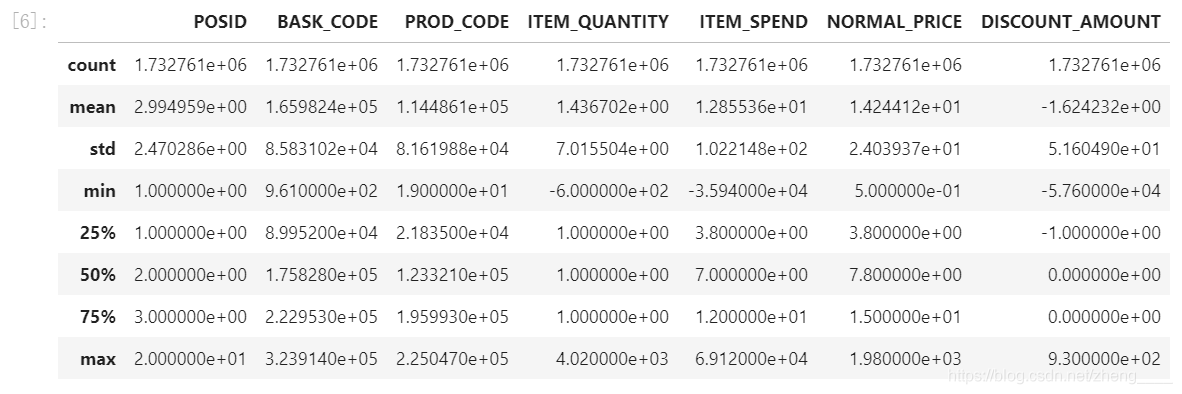
从图片中初步可以看出数据集可能存在的异常数据以及需要进行初步处理的地方有以下几点:
1)数据表中的SDATE字段需要将数据类型转换为日期型方便后续计算;
2)数据表中的ITEM_SPEND字段有负值,即商品实付金额为负,为异常数据;
3)数据表中的ITEM_QUANTITY字段有负值,即商品数量为负,为异常数据;
4)数据表中的DISCOUNT_AMOUTN字段数据有正值,即折扣后金额比折扣前金额高,为异常数据。
5)为方便阅读与查看,将列名统一改为符合驼峰命名法
2、修改列名
item.columns = ['shop_date','store_id','pos_id','user_id','prod_id','item_quantity','item_spend','normal_price','discount_type','discount_amount']
3、检验缺失数据
item.apply(lambda x: sum(x.isnull()) / len(x), axis=0)
4、查看并转换数据类型
(1)查看数据表类型
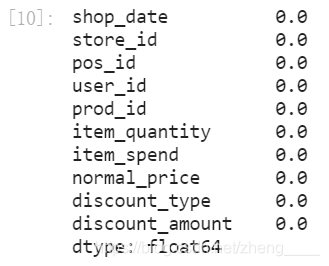
如图可发现数据中没有缺失数据,因此不需要进行缺失值处理
(2)转换数据类型
数据类型中的object表示如果一列中含有多个类型,则该列的类型会是object,同样字符串类型的列也会被当成object类型,因此object类型中SDATE数据类型应为日期类型,此外数值类型由于涉及零售的金钱问题,也应都调整为两位小数。
因此最终数据表数据类型需要调整的地方主要有以下几点:
- 1)调整日期数据类型
- 2)将金钱调整为两位小数
- 3)查看调整后数据类型
#日期数据类型
item.shop_date = pd.to_datetime(item.shop_date)
#金钱保留两位小数
pd.set_option('display.float_format', lambda x: '%.2f' % x)#将所有数据转换为两位小数
(3)查看修改后数据表数据类型
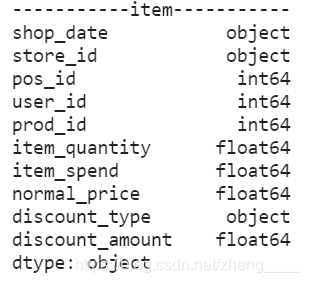
5、查看异常值并删除
根据上一小节对数据的初步查看发现的问题进行操作,在上一小节中发现数据表中商品数量、订单总金额、商品实付金额均有负值,且折扣金额为正,折扣金额的计算可能受到金额为负的影响,此外,数据也可能存在空值。因此,异常值的删除主要有以下几个操作:
1)将商品数量、订单总金额、商品实付金额为负值的调整为正值;
2)新建销售总金额字段:销售总金额=单价*数量根据修改后的数据进行折扣金额的计算:折扣金额=销售总金额-实际付款金额(ITEM_SPEND),与实际折扣金额不同的可以判定为异常数据,进行删除操作;
3)删除过后分析是否还存在折扣金额为正的数据,若存在,也进行删除操作。

最后发现不存在折扣金额与实际折扣不同的数据,可以判定无异常值。
六、数据分析
1、总体销量数据
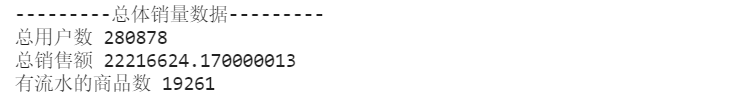
由总体销售情况分析可知,商店在2018年6月1日-2018年7月5日共有280878个用户进店购买过商品,总销售额为22216624.17元,有流水的商品数共19261个。
2、商品维度分析
(1)商品价格分析
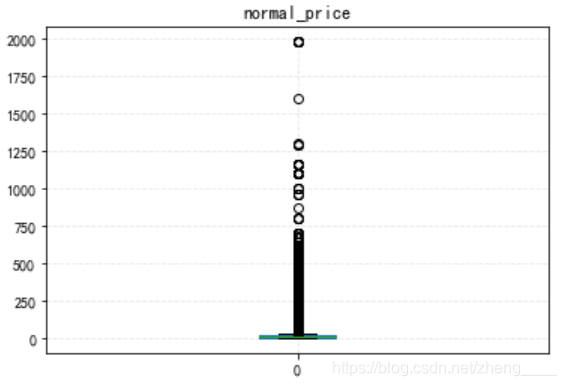
由初步价格箱型图可知,客户比较青睐店铺内的低价商品,且由此图无法很明显的看出商品价格具体情况,因此下面将商品价格为0-50的价格提取出来进行分析
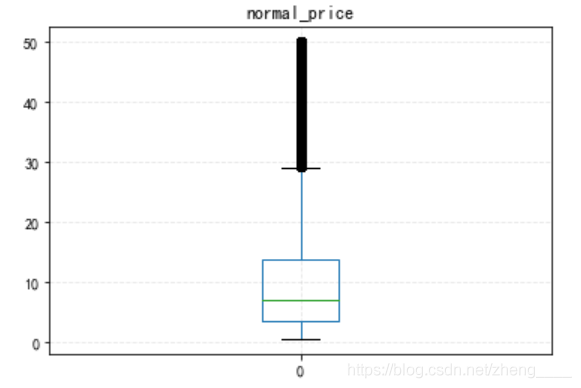
#求商品价格的四分位数 df_1 = pd.to_numeric(item_normal['normal_price']) q = [df_1.quantile(i) for i in [0,.25,.5,.75,1]];q[-1] += 1 q
[0.5, 3.6, 7.0, 13.8, 51.0]
由最后的箱型图可知,商品价格最多的在3.6元~13.8元之间,也符合消费者在零售商店购买的商品价格会比较低,店家可以根据消费者的消费情况对商品进行调整,多上架一些平价、常用的商品供消费者选择。
(2)查看销量排名前十和最后的商品
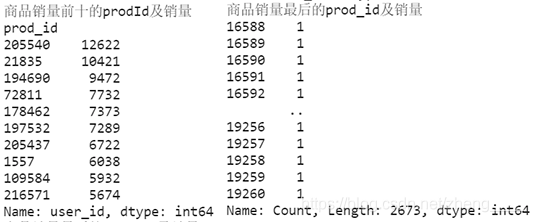
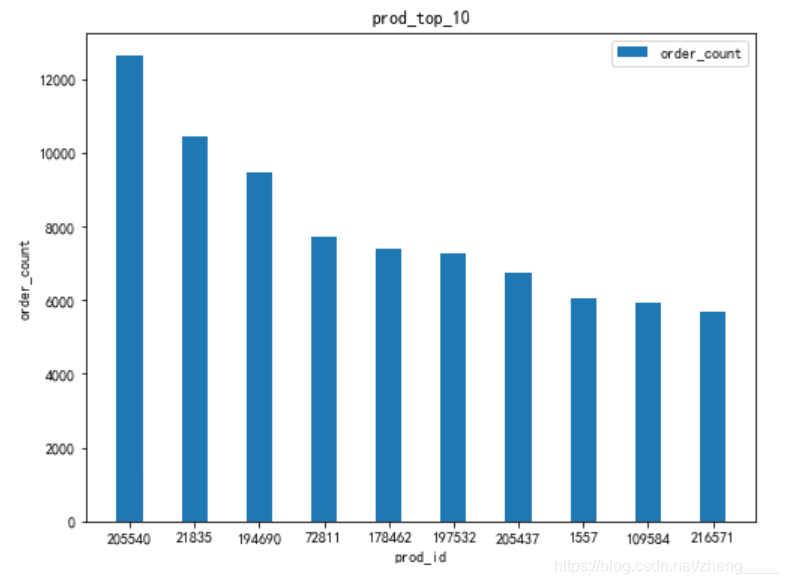
本小节分析了商品销售量前10和商品销售量最后的商品数量,此外将商品销售量前10的商品绘制柱状图进行分析。
由图表可知,前3销售量的商品很明显比后面商品销量多,差别至少为2000以上,而商品销量最后的商品在计算过程中发现有很多商品销量为1,将所有销量为1的商品提取出来,共有2673个,这2673个商品在这一段时间只销售了1个商品,可能为商品为不常用商品,也可能是商品本身有其他问题。
(3)查看销售额排名前十和后十的商品
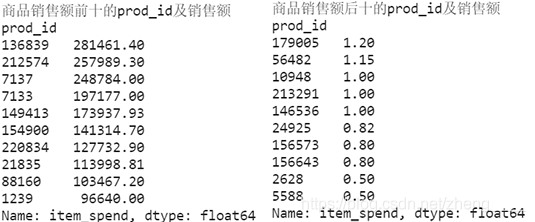
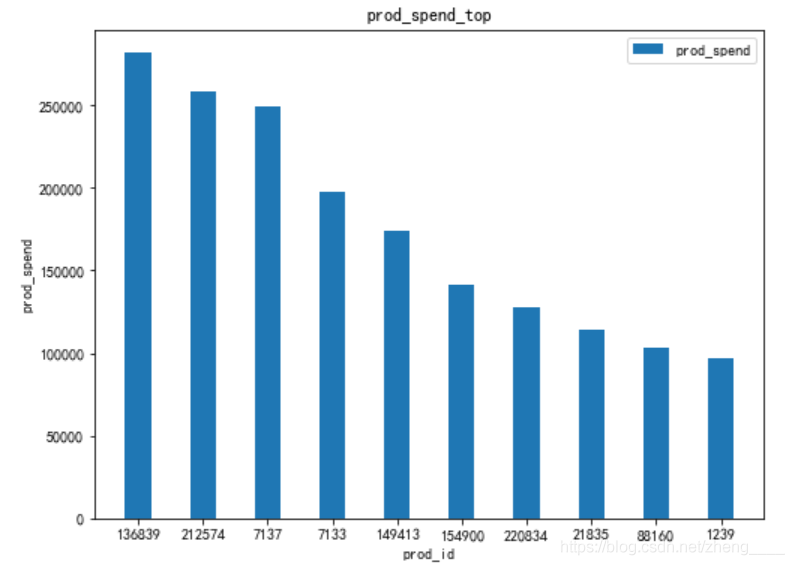
本小节主要分析了商品销售额前10和商品销售量后10的商品,此外将商品销售量前10的商品绘制柱状图进行分析。由图表可知,前3销售量的商品很明显比后面商品销售额多,差别至少为50000以上,而商品销量最后的商品仅仅在1元左右,这些商品无论是数量还是销售额都很少,商品可能存在问题。
(4)查看销售量与销售额关系
由于商品销售量最后的销售量为1,数量共2673个,因此查看销售量最后2673个商品中同时销售额在后10的商品,发现销售额最后的商品均为销量为1的商品,本小节查看了销售额和销售量最后的商品编号,找出之后根据具体的商品,找出原因,考虑如何优化或者是否要下架。
(5)商品关联度分析
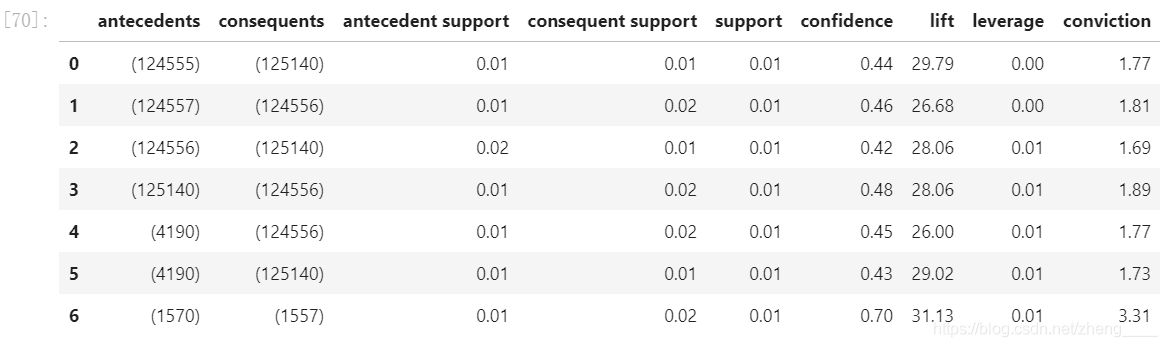
从以上的结果可以总结出:
从总体上看,所有组合商品中支持度数值偏低,这是由于平台销售的商品种类繁多,也可能是用户同时购买两个商品的可能性低,需要进一步进行分析;
商品组合[1570] --> [1557]的置信度最高,表示支持率在1%的情况下购买商品编号1570的用户中有70%会购买商品编号1557,可以对这两种商品进行捆绑销售;
3、店铺维度分析
进行店铺维度的分析可以分析各店铺销售情况,判断哪些店铺销售情况不好,考虑是否需要对店铺员工进行培训或裁员。
(1)店铺销售量情况分析
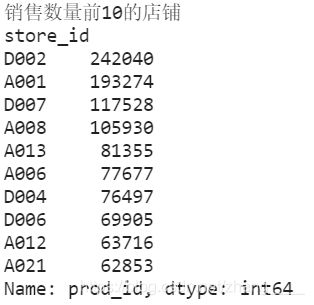
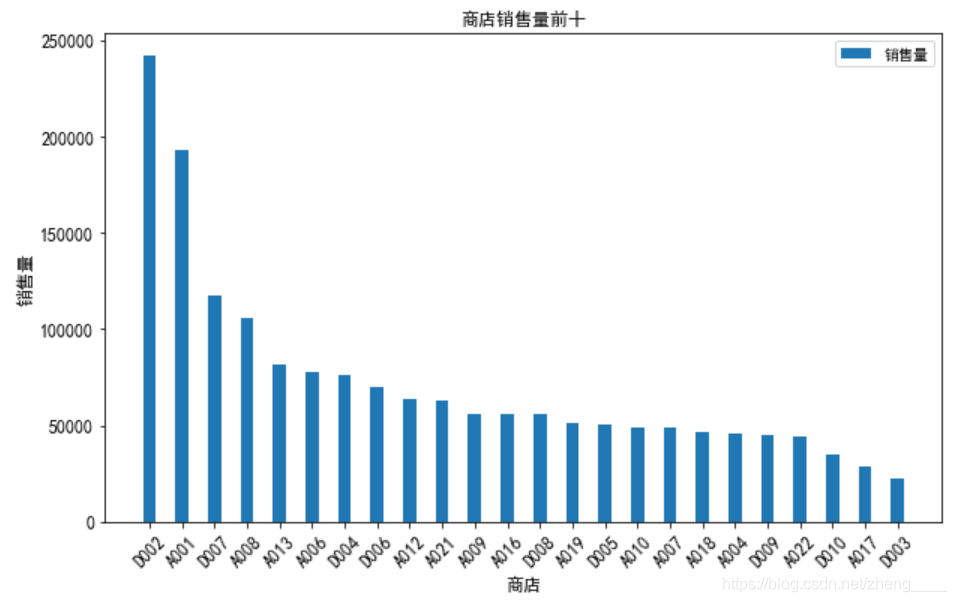
本小节分析了商品销售量前10的店铺,可以发现商品销售数量前2的店铺销售量远超过后面的店铺,超过150000个商品,说明D002和A001两个店铺商品数量销售情况很好。
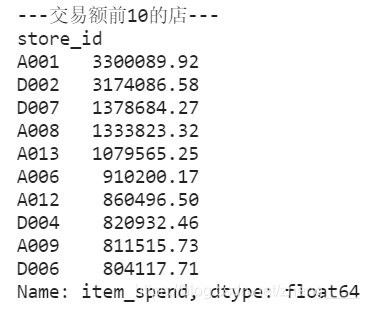
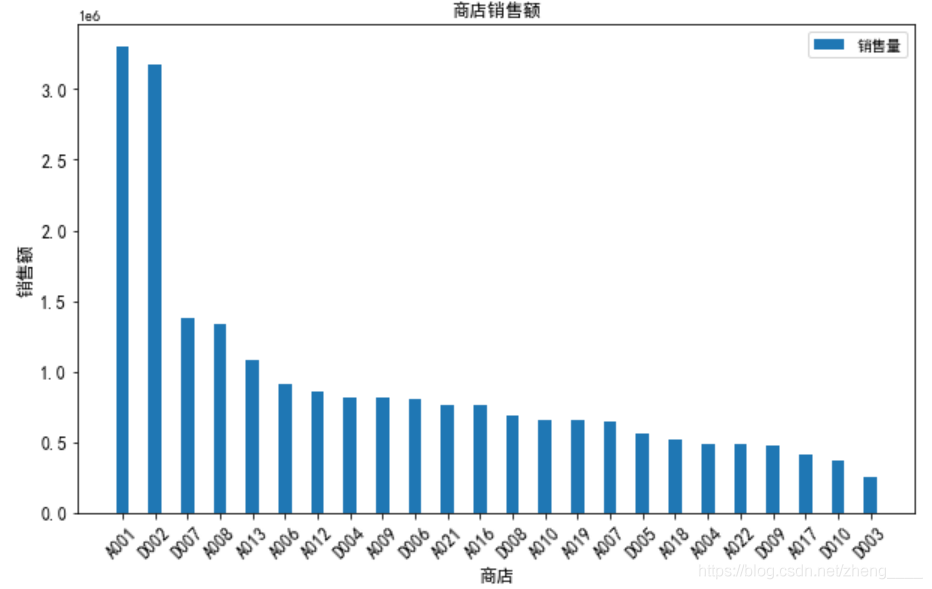
本小节分析了商品销售额前10的店铺,进行图表分析,可以发现A001和D002两个店铺销售额远超其他店铺,至少超过了2000000元,根据上小节分析,这两个店铺销售量与销售额均远超其他店铺,说明两个店铺销售情况良好。
(2)店铺促销情况分析
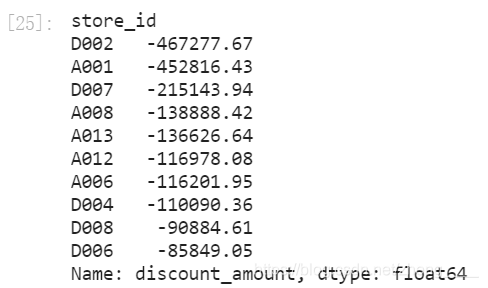
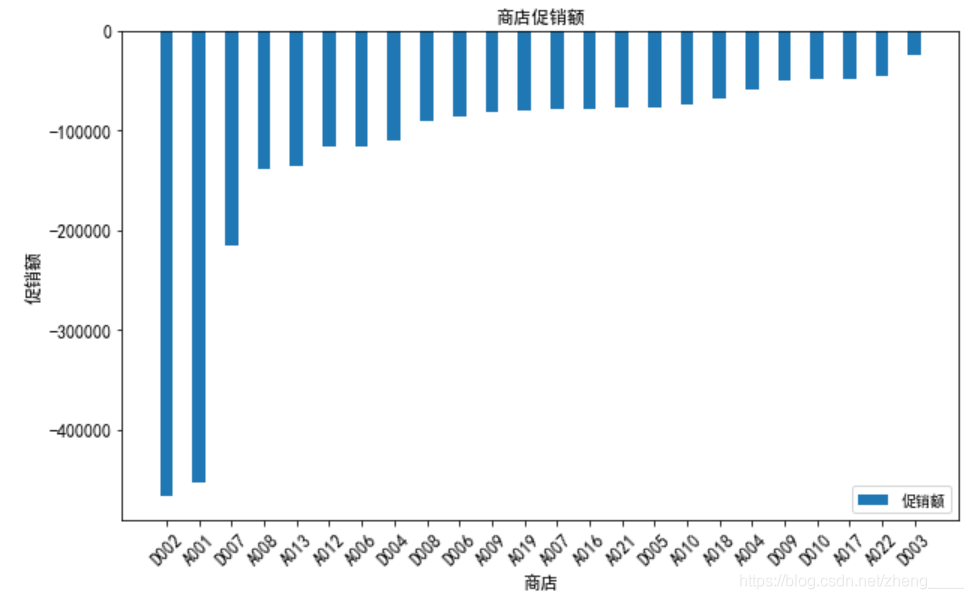
4、销售情况分析
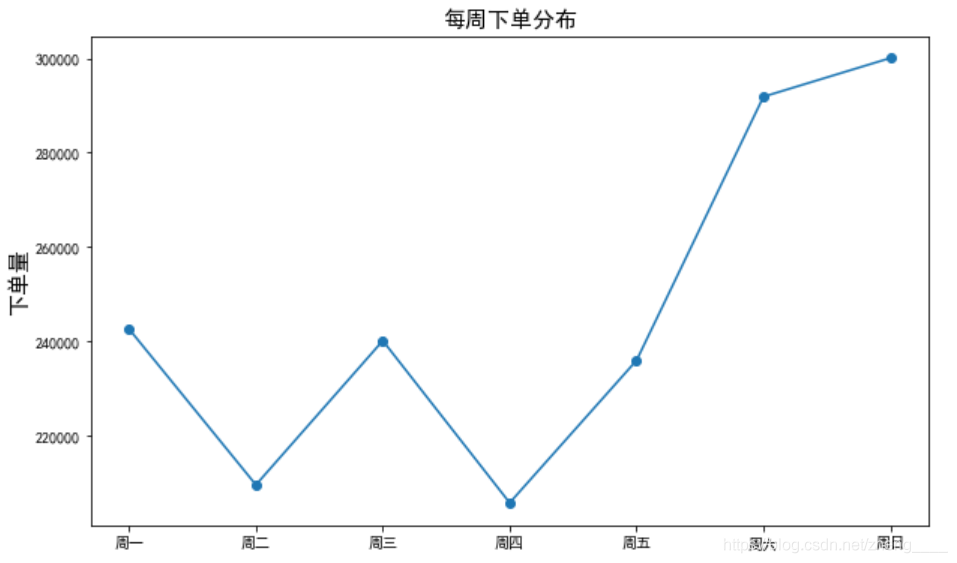
(1)下单时间分析
(2)销售额分析
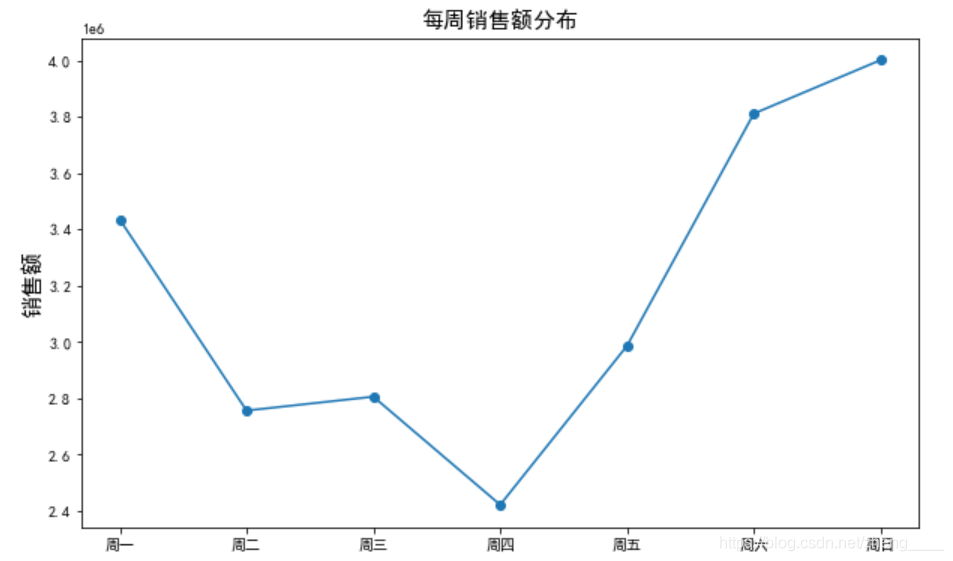
由于数据表中时间仅有日期,没有具体的销售时间,且数据量由2018年6月1日-2018年7月5日,仅有约一个月的时间,因此分析月销售量没有很大的意义,因此首先对每周周一至周日的销售情况进行分组计算,求出一周内不同天的销售情况,分析每周哪一天销售情况最好。
由图表可以看出,周一至周五的下单量在一条线上下波动,没有很大的起伏,周六和周日两天的下单量远远高于周一至周五的下单量,高出了至少50000单,销售额也是同样的趋势,超出了至少400000元,可以看出一般周末用户的下单量与交易额会远远高于工作日的下单情况,商家可以考虑在周末多上一些商品供用户选择。
(3)每日销售额/销售量分析
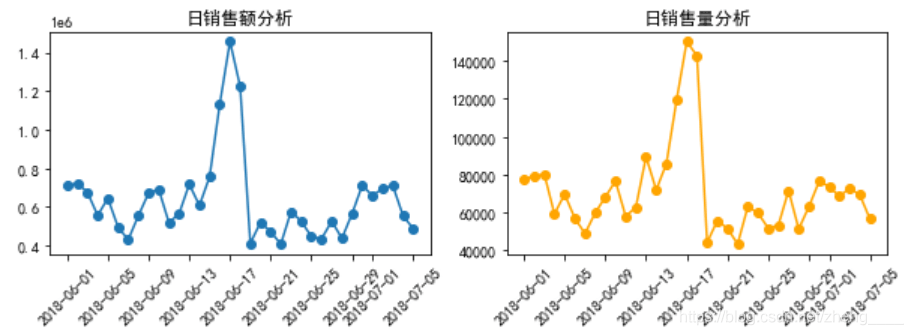
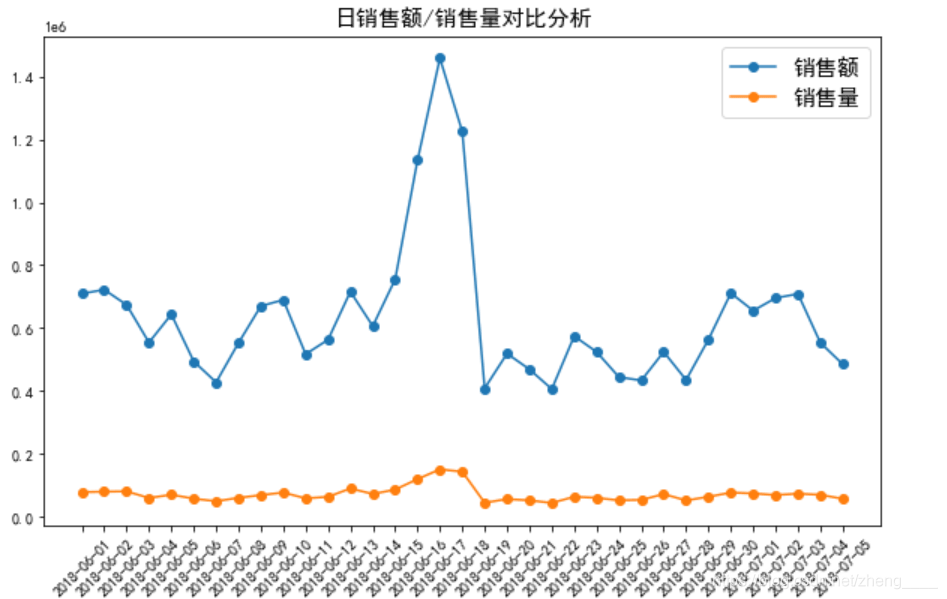
本小节分组计算了日销售额与日销售量的数据,并绘制了折线图进行趋势对比分析,由图中可知,销售量与销售额的趋势几乎相同,且均在2018年6月16日达到最高,。
(4)周均消费次数/金额
总订单数 280878 次
周数 6 周
周均消费次数 46813 次
周均消费金额为: 3702770.0 元
(5)客单价
商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。
客单价为: 79.0 元
由于数据表中数据量由2018年6月1日-2018年7月5日,仅有约一个月的时间,因此分析月销售量没有很大的意义,因此首先对每周周一至周日的销售情况进行分组计算,求出不同周的大致销售情况,最终结果可知总订单数为280878次,共有6周的数据,周均消费次数为46813次
5、相关性分析
查看数据相关性
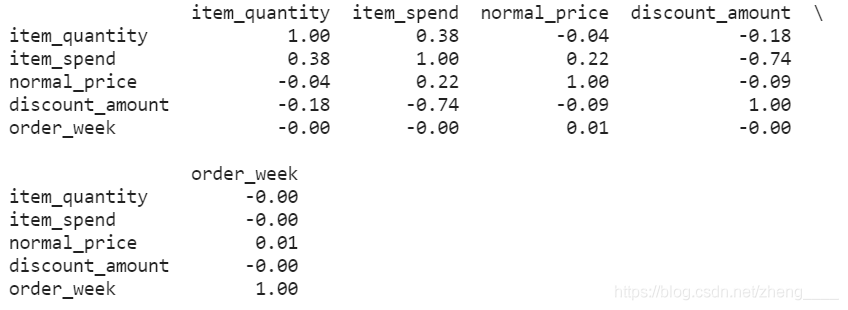
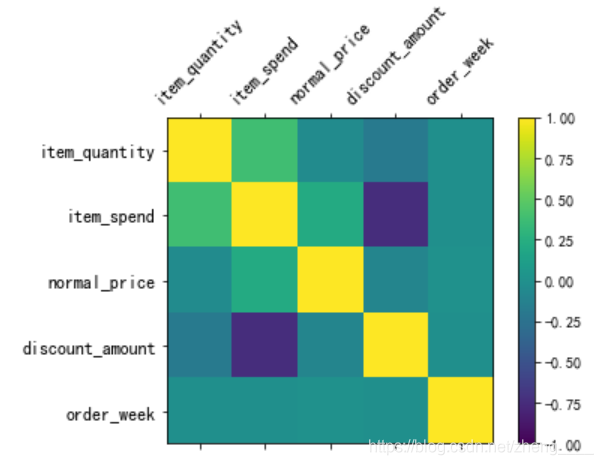
我们可以查看数据的相关性,值越接近1,说明相关性越强。也可以把相关性信息进行可视化,颜色越接近黄色相关性越高,越接近紫色相关性越低。由相关性图可知,商品销售总额与商品数量、折扣金额和商品销售总额相关性相对强,周数和销售额相关性最弱
6、用户分析
(1)用户角度分析
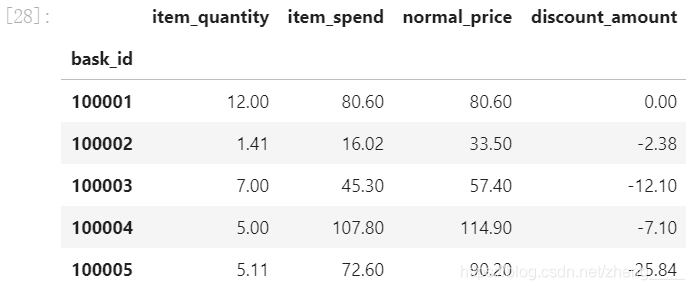
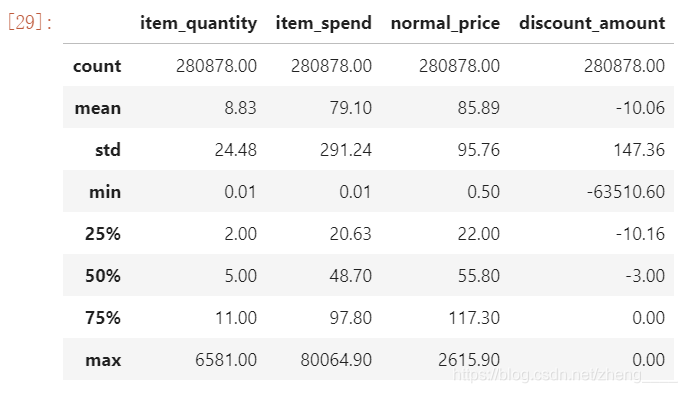
从用户角度看,每位用户平均购买8.83单位的商品,最多的用户购买了6581个商品,属于狂热用户。用户的平均消费金额(客单价)79.1元,标准差是291.24,结合分位数和最大值看,平均值和50~75分位之间的接近,肯定存在小部分的高额消费用户。
(2)按周维度分析
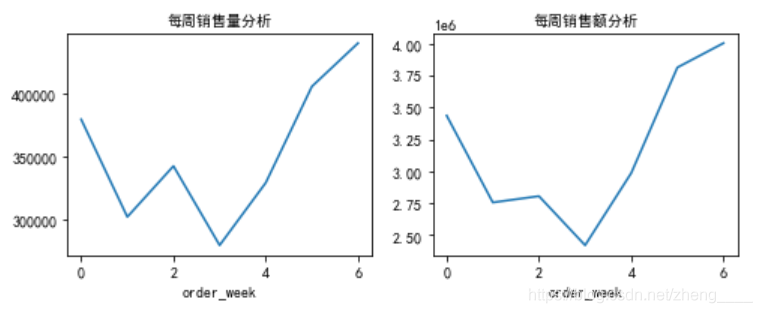
按周统计每周的商品销量和销售额。从图中可以看到,销售量和销售额趋势相同,没有什么异常的地方,前几周销量比较平稳,甚至有些下降,而后面几周销量逐渐高涨,可能是商店逐渐被用户所认可。
(3)观察用户消费购买力
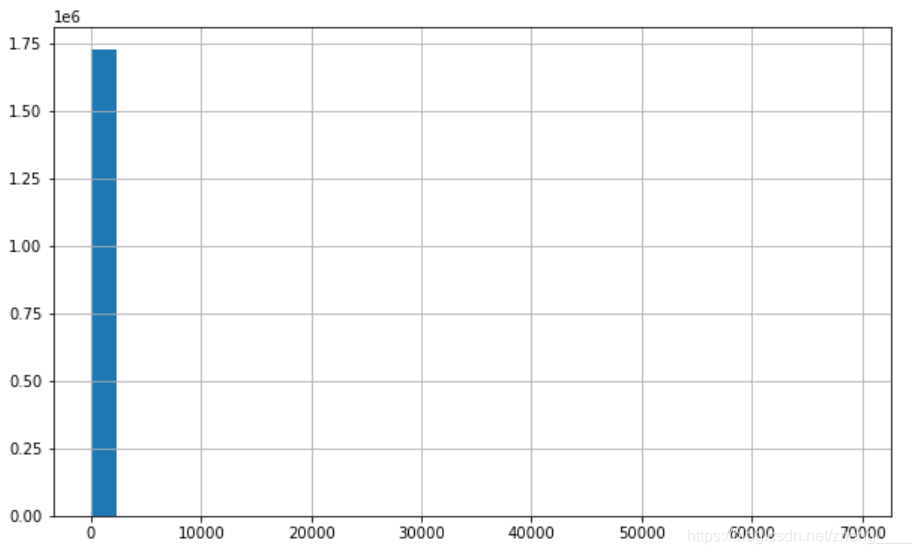
左边的直方图的x轴代表item_spend的分组,一共30组。y轴代表item_spend中对应到各个分组的频数。从直方图看,大部分用户的消费能力确实不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。
(4)分析用户的复购率
复购率 = 单位时间内,消费两次及以上的用户数 / 购买总用户数
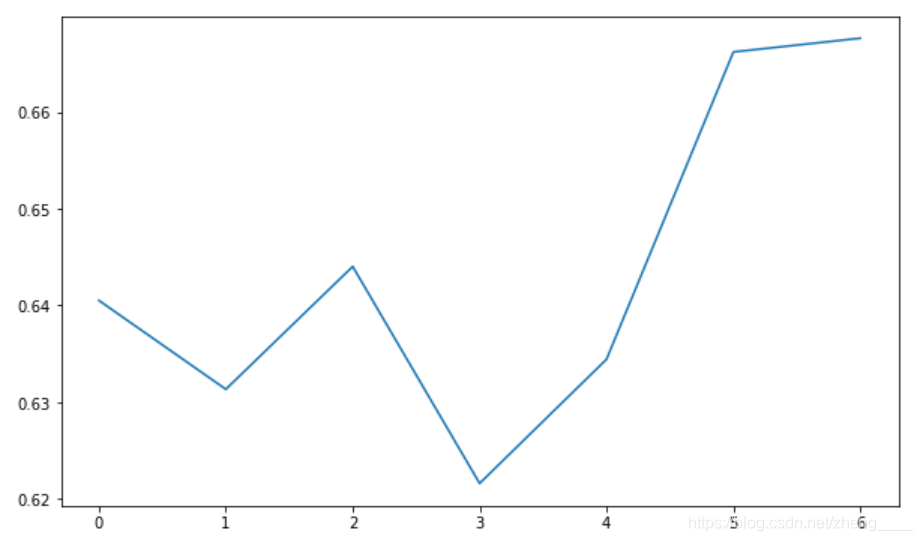
图上复购率可知复购率一直在62%以上,可能因为是零售商店,用户会经常购买商品,尤其到最后几周复购率更高,可能因为用户已经开始信任店铺
(5)用户RFM分析
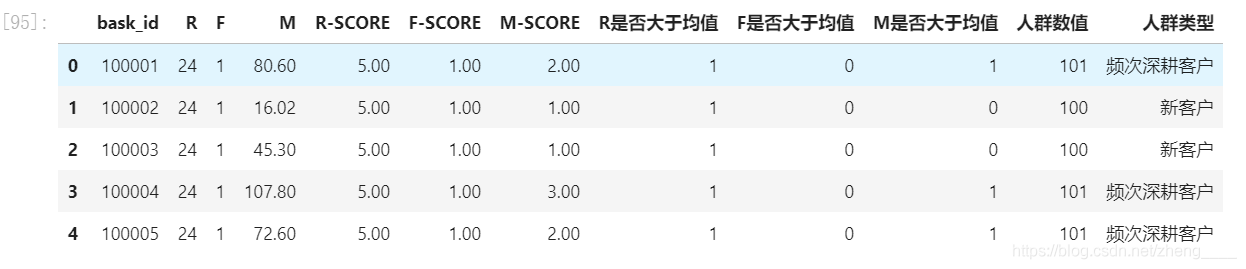
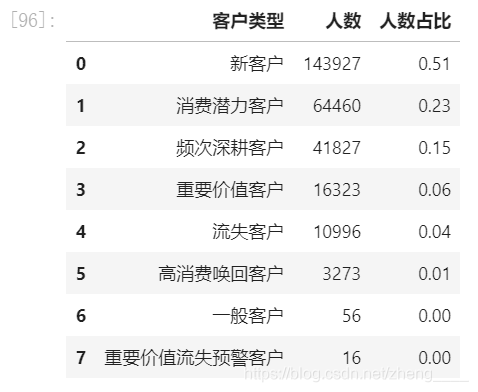
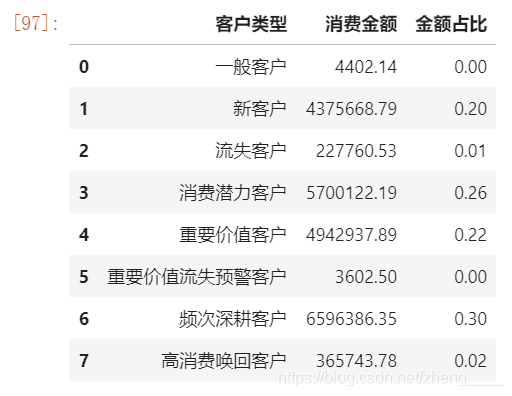

通过RFM方法,我们根据用户购买商品的数据进行分析,对用户进行了归类。在促销等很多过程中,可以更加精准化,针对不同类别的用户进行不同的符合其特点的促销方式和销售方式,不至于出现用户反感的情景。
以上就是使用Python对零售商品进行数据分析的详细内容,更多关于Python数据分析零售商品的资料请关注我们其它相关文章!
相关推荐
-

python数据分析实战指南之异常值处理
目录 异常值 1.异常值定义 2.异常值处理方式 2.1 均方差 2.2 箱形图 3.实战 3.1 加载数据 3.2 检测异常值数据 3.3 显示异常值的索引位置 总结 异常值 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 常用的异常值分析方法为3σ原则.箱型图分析.机器学习算法检测,一般情况下对异常值的处理都是删除和修正填补,即默认为异常值对整个项目的作用不大,只有当我们的目的是要求准确找出离群点,并对离群点进行分析时有必要用到机器学
-
Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
分享4款Python 自动数据分析神器
目录 1.PandasGUI 2.PandasProfiling 3.Sweetviz 4.dtale 4.1数据操作(Actions) 4.2数据可视化(Visualize) 4.3高亮显示(Highlight) 前言: 我们做数据分析,在第一次拿到数据集的时候,一般会用统计学或可视化方法来了解原始数据.比如了解列数.行数.取值分布.缺失值.列之间的相关关系等等,这个过程我们叫做 EDA(Exploratory Data Analysis,探索性数据分析). 用pandas一行行写代码,那太痛
-
Python对口红进行数据分析来选定情人节礼物
目录 前言: 准备工作 驱动安装 模块使用与介绍 流程解析 完整代码 效果展示 结尾 前言: 情人节.三八女神节.520.七夕节.圣诞节.元旦.生日.新年.各种纪念日……这些节日,对于每一个有女朋友的男同胞们来说都存在一个困惑的问题:送女朋友什么礼物好? 其实送礼物这件事,说难也不难,但也绝不是一件简单的事儿hhh- 送对了感情升温,送错了让你恢复单身! 但只要在挑选礼物的时候记得以下这几点,想要踩雷都很难了. 1.符合对方的审美,平时多留意一下女朋友喜欢什么东西. 2.颜值即正义,女孩子都是颜
-
python数据分析近年比特币价格涨幅趋势分布
目录 使用技术点: 使用工具: 导入第三方库 大家好,我是辣条. 曾经有一个真挚的机会,摆在我面前,但是我没有珍惜,等到失去的时候才后悔莫及,尘世间最痛苦的事莫过于此,如果老天可以再给我一个再来一次机会的话,我会买下那个比特币,哪怕付出所有零花钱,如果非要在这个机会加上一个期限的话,我希望是十年前. 看着这份台词是不是很眼熟,我稍稍改了一下,曾经差一点点点就购买比特币了,肠子都悔青了现在,今天对比特币做一个简单的数据分析. # 安装对应的第三方库 !pip install pandas !pip
-
Python数据分析之分析千万级淘宝数据
目录 1.项目背景与分析说明 2.导入相关库 4.模型构建 1)流量指标的处理 2)用户行为指标 3)漏斗分析 4)客户价值分析(RFM分析) 1.项目背景与分析说明 1)项目背景 网购已经成为人们生活不可或缺的一部分,本次项目基于淘宝app平台数据,通过相关指标对用户行为进行分析,从而探索用户相关行为模式. 2)数据和字段说明 本文使用的数据集包含了2014.11.18到2014.12.18之间,淘宝App移动端一个月内的用户行为数据.该数据有12256906天记录,共6列数据. user_i
-
使用Python对零售商品进行数据分析
目录 一.主要内容: 二.使用工具 三.数据来源 四.字段含义 五.数据清洗 1.查看总体数据特征 2.修改列名 3.检验缺失数据 4.查看并转换数据类型 5.查看异常值并删除 六.数据分析 1.总体销量数据 2.商品维度分析 3.店铺维度分析 4.销售情况分析 5.相关性分析 6.用户分析 一.主要内容: 1.清洗数据.将列名统一修改.处理缺失数据和异常数据.转换日期等数据类型 2.查看总体销售情况 3.商品维度进行分析.主要分析内容有:商品价格分析,商品销售量.销售额情况分析,商品关联分析
-
Python人工智能之波士顿房价数据分析
目录 1.数据概览分析 1.1 数据概览 1.2 数据分析 2. 项目总体思路 2.1 数据读取 2.2 模型预处理 (1)数据离群点处理 (2)数据归一化处理 2.3. 特征工程 2.4. 模型选择 2.5. 模型评价 2.6. 模型调参 3. 项目总结 [人工智能项目]机器学习热门项目-波士顿房价 1.数据概览分析 1.1 数据概览 本次提供: train.csv,训练集: test.csv,测试集: submission.csv 真实房价文件: 训练集404行数据,14列,每行数据表示房屋
-
基于Python实现的微信好友数据分析
最近微信迎来了一次重要的更新,允许用户对"发现"页面进行定制.不知道从什么时候开始,微信朋友圈变得越来越复杂,当越来越多的人选择"仅展示最近三天的朋友圈",大概连微信官方都是一脸的无可奈何.逐步泛化的好友关系,让微信从熟人社交逐渐过渡到陌生人社交,而朋友圈里亦真亦幻的状态更新,仿佛在努力证明每一个个体的"有趣". 有人选择在朋友圈里记录生活的点滴,有人选择在朋友圈里展示观点的异同,可归根到底,人们无时无刻不在窥探着别人的生活,唯独怕别人过多地了解
-
使用Python对微信好友进行数据分析
1.准备工作 1.1 库介绍 只有登录微信才能获取到微信好友的信息,本文采用wxpy该第三方库进行微信的登录以及信息的获取. wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展. wxpy一些常见的场景: •控制路由器.智能家居等具有开放接口的玩意儿 •运行脚本时自动把日志发送到你的微信 •加群主为好友,自动拉进群中 •跨号或跨群转发消息 •自动陪人聊天 •逗人玩 总而言之,可用来实现各种微信个人号的自动化操作. 1.2 wxpy库安装 wxpy 支持
-
Python实现的微信好友数据分析功能示例
本文实例讲述了Python实现的微信好友数据分析功能.分享给大家供大家参考,具体如下: 这里主要利用python对个人微信好友进行分析并把结果输出到一个html文档当中,主要用到的python包为itchat,pandas,pyecharts等 1.安装itchat 微信的python sdk,用来获取个人好友关系.获取的代码 如下: import itchat import pandas as pd from pyecharts import Geo, Bar itchat.login() f
-
Python实现的北京积分落户数据分析示例
本文实例讲述了Python实现的北京积分落户数据分析.分享给大家供大家参考,具体如下: 北京积分落户状况 获取数据(爬虫/文件下载)-> 分析 (维度-指标) 从公司维度分析不同公司对落户人数指标的影响 , 即什么公司落户人数最多也更容易落户 从年龄维度分析不同年龄段对落户人数指标影响 , 即什么年龄段落户人数最多也更容易落户 从百家姓维度分析不同姓对落户人数的指标影响 , 即什么姓的落户人数最多即也更容易落户 不同分数段的占比情况 # 导入库 import numpy as np import
-
python实现秒杀商品的微信自动提醒功能(代码详解)
技术实现原理:获取京东的具体的商品信息,然后再使用微信发送提醒 工具:需要两个微信号,这两个微信号互为好友 1.收集自己想要的商品url 我们就以京东来举例,获取京东的秒杀商品信息: 首先,我们在网页上打开京东,搜索我们想要的商品,这边我就以我最近买的东西为例子: 我们需要找到它的商品信息,需要打开浏览器的开发者模式,之后我们需要选择自己的配送地址,这个时候里面就发送一些接口请求: 我们选择一个有用的商品信息接口: 找到自己想要商品的信息接口,来判断它是否有货: 一般规则是:如果这个接口书籍里面
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-
Python 制作查询商品历史价格的小工具
一年一度的双十一就快到了,各种砍价.盖楼.挖现金的口令将在未来一个月内充斥朋友圈.微信群中.玩过多次双十一活动的小编表示一顿操作猛如虎,一看结果2毛5.浪费时间不说而且未必得到真正的优惠,双十一电商的"明降暗升"已经是默认的潜规则了.打破这种规则很简单,可以用 Python 写一个定时监控商品价格的小工具. 思路 第一步抓取商品的价格存入 Python 自带的 SQLite 数据库 每天定时抓取商品价格 使用 pyecharts 模块绘制价格折线图,让低价一目了然 抓取京东价格 从商品
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.