Python通过pytesseract库实现识别图片中的文字
目录
- 前言
- 一、pytesseract
- 1.pytesseract是什么
- 2.安装pytesseract
- 3.查看pytesseract版本
- 4.安装PIL
- 5.查看PIL版本
- 二、Tesseract OCR
- 1.Tesseract OCR是什么
- 2.安装Tesseract OCR
- 3.安装 Tesseract OCR 语言包
- 三、使用方法
- 1.引入库
- 2.打开图片文件
- 3.使用Tesseract进行文字识别
- 4.输出识别结果
- 总结
前言
大家好,我是空空star,本篇给大家分享一下通过Python的pytesseract库识别图片中的文字。
本篇所用软件相关版本:
macOS 11.6.5
Python 3.8.9
pytesseract 0.3.10
Pillow 9.4.0
一、pytesseract
1.pytesseract是什么
Pytesseract是一个Python的OCR库,它可以识别图片中的文本并将其转换成文本形式。Pytesseract基于Google的Tesseract OCR引擎,具有较高的准确性和可靠性。它可以读取多种格式的图片,包括PNG、JPEG、GIF等。Pytesseract可以应用于自然语言处理、数据挖掘、OCR识别等领域。
2.安装pytesseract
pip install pytesseract
3.查看pytesseract版本
pip show pytesseract
Name: pytesseract
Version: 0.3.10
Summary: Python-tesseract is a python wrapper for Google’s Tesseract-OCR
Home-page: https://github.com/madmaze/pytesseract
Author: Samuel Hoffstaetter
Author-email: samuel@hoffstaetter.com
License: Apache License 2.0
Requires: packaging, Pillow
Required-by:
4.安装PIL
Pillow库是Python图像处理库,pytesseract使用它来处理图像。
pip install pillow
5.查看PIL版本
pip show pillow
Name: Pillow
Version: 9.4.0
Summary: Python Imaging Library (Fork)
Home-page: https://python-pillow.org
Author: Alex Clark (PIL Fork Author)
Author-email: aclark@python-pillow.org
License: HPND
Requires:
Required-by: image, imageio, matplotlib, pytesseract, wordcloud
二、Tesseract OCR
1.Tesseract OCR是什么
Tesseract OCR是一种开源的OCR(Optical Character Recognition,光学字符识别)引擎,它能够将图像中的文本内容识别并转换为可编辑的文本格式。它最初由惠普实验室开发,现在由谷歌维护和更新。Tesseract OCR支持超过100种语言,包括中文、英文、法文、德文等。它可以在多种操作系统上运行,包括Windows、Linux、macOS等。Tesseract OCR被广泛应用于数字化文档、自动化数据输入、智能搜索等方面。
2.安装Tesseract OCR
macOS下:
brew install tesseract
3.安装 Tesseract OCR 语言包
macOS下:
brew install tesseract-lang
三、使用方法
1.引入库
import pytesseract from PIL import Image
2.打开图片文件
img = Image.open("demo.png")
3.使用Tesseract进行文字识别
text = pytesseract.image_to_string(img, lang='chi_sim')
4.输出识别结果
print(text)
原图
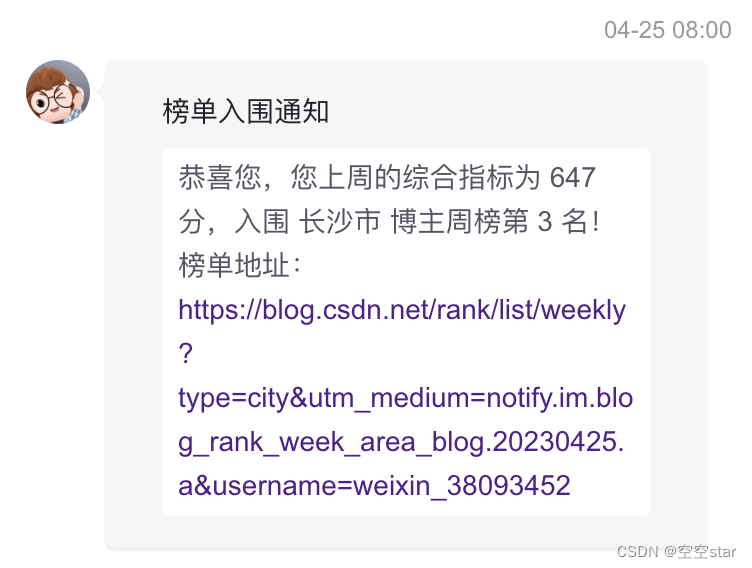
识别出的文字截图
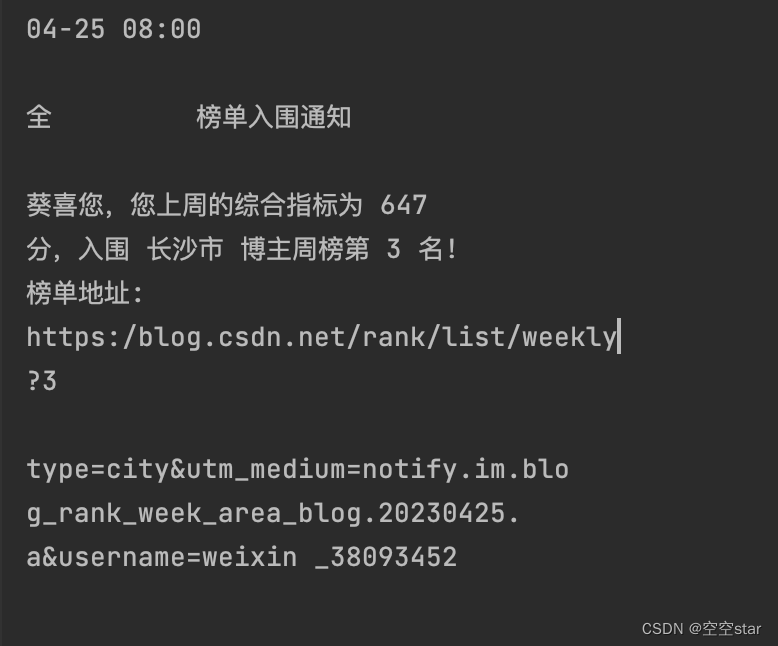
总结
image_to_string是一个Python函数,它是由tesseract OCR引擎提供的。这个函数的作用是将一个图像中的文本转换成字符串,也就是把图像中的文字识别出来,并把它们转换成计算机可以处理的字符串格式。这个函数可以接受多种格式的图像,例如JPEG、PNG、BMP等。在使用这个函数前,需要确保已经安装了tesseract OCR引擎。
以上就是Python通过pytesseract库实现识别图片中的文字的详细内容,更多关于Python pytesseract识别图片中文字的资料请关注我们其它相关文章!
相关推荐
-
python利用 pytesseract快速识别提取图片中的文字((图片识别)
目录 前言 一.配置环境 1. 安装python依赖 2. 安装识别引擎 二.使用步骤 1.引入库 2.提取图片文字 3.运行效果 总结 提示:本文多图,请手机端注意流量. 前言 利用python做图片识别,识别提取图片中的文字会有很多方法,但是想要简单一点怎么办,那就可以使用tesseract识别引擎来实现,一行代码就可以做到提取图片文本. 一.配置环境 1. 安装python依赖 本程序用到了两个python库,pytesseract和PIL,所以先来安装. 运行以下命令 pip insta
-
Python基于内置库pytesseract实现图片验证码识别功能
这篇文章主要介绍了Python基于内置库pytesseract实现图片验证码识别功能,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 环境准备: 1.安装Tesseract模块 git文档地址:https://digi.bib.uni-mannheim.de/tesseract/ 下载后就是一个exe安装包,直接右击安装即可,安装完成之后,配置一下环境变量,编辑 系统变量里面 path,添加下面的安装路径: 2.如果您想使用其他语言,请下载相应的
-
python 识别图片中的文字信息方法
最近朋友需要一个可以识别图片中的文字的程序,以前做过java验证码识别的程序: 刚好最近在做一个python项目,所以顺便用Python练练手 1.需要的环境: 2.7或者3.4版本的python 2.需要安装pytesseract库 依赖PIL和tesseract-ocr库 本地环境是ubuntu,下面说一下 具体步骤: 2.7 1.安装PIL: 直接使用pip 安装: pip install Pillow 2.安装tesseract-ocr: apt-get install tesserac
-
如何使用Python进行OCR识别图片中的文字
朋友需要一个工具,将图片中的文字提取出来.我帮他在网上找了一些OCR的应用,都不好用.所以准备自己研究,写一个Web APP供他使用. OCR1,全称Optical character recognition,或者optical character reader,中文译名叫做光学文字识别.它是把图像文件中的手写文本,打印文本转换为机器编码文本的一种方法. OCR技术广泛用于识别打印纸张中的文字数据 -- 比如护照,支票,银行声明,收据,统计表单,邮件等.OCR的早期版本,需要对图片中的每个文字都
-
如何利用Python识别图片中的文字
一.前言 不知道大家有没有遇到过这样的问题,就是在某个软件或者某个网页里面有一篇文章,你非常喜欢,但是不能复制.或者像百度文档一样,只能复制一部分,这个时候我们就会选择截图保存.但是当我们想用到里面的文字时,还是要一个字一个字打出来.那么我们能不能直接识别图片中的文字呢?答案是肯定的. 二.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需
-

如何利用Python识别图片中的文字详解
一.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需要完成一个繁琐的工作. (1)Tesseract的安装及配置 Tesseract的安装我们可以移步到该网址 https://digi.bib.uni-mannheim.de/tesseract/,我们可以看到如下界面: 有很多版本供大家选择,大家可以根据自己的需求选择.其中w32表示32
-
Python+Pillow+Pytesseract实现验证码识别
目录 一.环境配置 二.验证码识别 实例1 实例2 实例3 昨天十行代码实现文字识别,感觉怎样,是不是很爽 今天咋们继续利用pillow和pytesseract来实现验证码的识别 一.环境配置 需要 pillow 和 pytesseract 这两个库,pip install 安装就好了. pip install pillow -i http://pypi.douban.com/simple --trusted-host pypi.douban.com pip install pytesserac
-
python利用pytesseract 实现本地识别图片文字
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import glob from os import path import os import pytesseract from PIL import Image from queue import Queue import threading import datetime import cv2 def convertimg(picfile, outdir): '''调整图片大小,对于过大的图片进行
-
python基于OpenCV模板匹配识别图片中的数字
前言 本博客主要实现利用OpenCV的模板匹配识别图像中的数字,然后把识别出来的数字输出到txt文件中,如果识别失败则输出"读取失败". 操作环境: OpenCV - 4.1.0 Python 3.8.1 程序目标 单个数字模板:(这些单个模板是我自己直接从图片上截取下来的) 要处理的图片: 终端输出: 文本输出: 思路讲解 代码讲解 首先定义两个会用到的函数 第一个是显示图片的函数,这样的话在显示图片的时候就比较方便了 def cv_show(name, img): cv2.imsh
-
Python3调用百度AI识别图片中的文字功能示例【测试可用】
本文实例讲述了Python3调用百度AI识别图片中的文字功能.分享给大家供大家参考,具体如下: 首先pip install命令安装baidu-aip模块,如下图所示(这里使用pip3 install baidu-aip命令): 编辑Python代码时注意,需要首先引入AipOcr和re两个模块,即: from aip import AipOcr import re 示例代码如下: from aip import AipOcr import re APP_ID='***' API_KEY='***
-
C# .NET实现扫描识别图片中的文字
目录 环境配置 操作步骤 调用API接口扫描并读取图片中的文字 C# VB.NET 注意事项 环境配置 本文以C#及VB.NET代码为例,介绍如何扫描并读取图片中的文字. 本次程序环境如下: Visual Studio版本要求不低于2017 图片扫描工具:Spire.OCR for .NET 图片格式:png(这里的图片格式支持JPG.PNG.GIF.BMP.TIFF等格式) 扫描的图片文字:中文(另外可支持英语.日语.韩语.德语.法语等) .NET Framework 4.6.1 下面是具体步
-
python pytesseract库的实例用法
说明 1.pytesseract需要与安装在本地的tesseract-ocr.exe文件一起使用. 2.需要注意的是,安装时必须选择中文包,默认只支持英文识别. 安装命令 pip install pytesseract 实例 import pytesseract from PIL import Image text = pytesseract.image_to_string(Image.open(r"d:\Desktop\39DEE621-40EA-4ad1-90CC-79EB51D39347.