Pandas Query方法使用深度总结
目录
- 获取数据
- 载入数据
- 使用 query() 方法
- 以 In-place 的方式执行 query 方法
- 指定多个条件查询
- 比较数值列
- 比较多个列
- 查询索引
- 比较多列
- 总结
大多数 Pandas 用户都熟悉 iloc[] 和 loc[] 索引器方法,用于从 Pandas DataFrame 中检索行和列。但是随着检索数据的规则变得越来越复杂,这些方法也随之变得更加复杂而臃肿。
同时 SQL 也是我们经常接触且较为熟悉的语言,那么为什么不使用类似于 SQL 的东西来查询我们的数据呢
事实证明实际上可以使用 query() 方法做到这一点。因此,在今天的文章中,我们将展示如何使用 query() 方法对数据框执行查询
获取数据
我们使用 kaggle 上的 Titanic 数据集作为本文章的测试数据集,下载地址如下:https://www.kaggle.com/datasets/tedllh/titanic-train
当然也可以在文末获取到萝卜哥下载好的数据集
载入数据
下面文末就可以使用 read_csv 来载入数据了
import pandas as pd
df = pd.read_csv('titanic_train.csv')
df
数据集有 891 行和 12 列:
使用 query() 方法
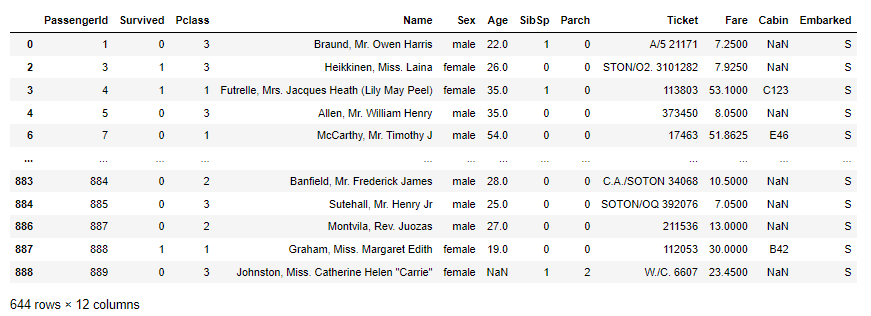
让我们找出从南安普敦 (‘S’) 出发的所有乘客,可以使用方括号索引,代码如下所示:
df[df['Embarked'] == 'S']
如果使用 query() 方法,那么看起来更整洁:
df.query('Embarked == "S"')
与 SQL 比较,则 query() 方法中的表达式类似于 SQL 中的 WHERE 语句。
结果是一个 DataFrame,其中包含所有从南安普敦出发的乘客:
query() 方法接受字符串作为查询条件串,因此,如果要查询字符串列,则需要确保字符串被正确括起来:
很多时候,我们可能希望将变量值传递到查询字符串中,可以使用 @ 字符执行此操作:
embarked = 'S'
df.query('Embarked == @embarked')
或者也可以使用 f 字符串,如下所示:
df.query(f'Embarked == "{embarked}"')
就个人而言,我认为与 f-string 方式相比,使用 @ 字符更简单、更优雅,你认为呢
如果列名中有空格,可以使用反引号 (``) 将列名括起来:
df.query('`Embarked On` == @embarked')
以 In-place 的方式执行 query 方法
当使用 query() 方法执行查询时,该方法将结果作为 DataFrame 返回,原始 DataFrame 保持不变。如果要更新原始 DataFrame,需要使用 inplace 参数,如下所示:
df.query('Embarked == "S"', inplace=True)
当 inplace 设置为 True 时,query() 方法将不会返回任何值,原始 DataFrame 被修改。
指定多个条件查询
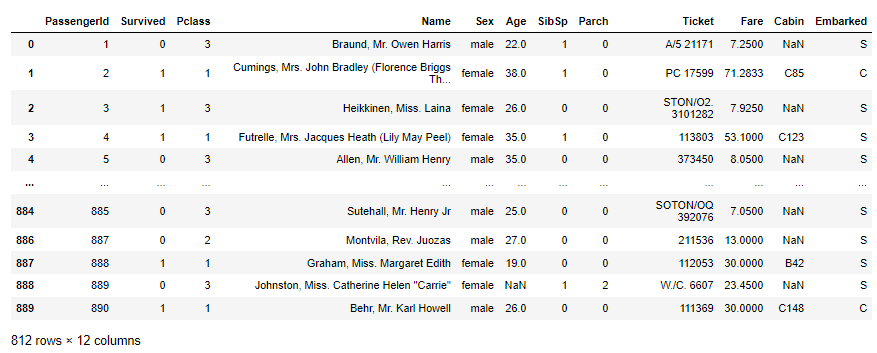
我们可以在查询中指定多个条件,例如假设我想获取所有从南安普敦 (‘S’) 或瑟堡 (‘C’) 出发的乘客。如果使用方括号索引,这种语法很快变得非常笨拙:
df[(df['Embarked'] == 'S') | (df['Embarked'] == 'C')]
我们注意到,在这里我们需要在查询的条件下引用 DataFrame 两次,而使用 query() 方法,就简洁多了:
df.query('Embarked in ("S","C")')
查询结果如下
如果要查找所有不是从南安普敦(‘S’)或瑟堡(‘C’)出发的乘客,可以在 Pandas 中使用否定运算符 (~):
df[~((df['Embarked'] == 'S') | (df['Embarked'] == 'C'))]
使用 query() 方法,只需要使用 not 运算符:
df.query('Embarked not in ("S","C")')
以下输出显示了从皇后镇 (‘Q’) 出发的乘客以及缺失值的乘客:

说到缺失值,该怎么查询缺失值呢,当应用于列名时,我们可以使用 isnull() 方法查找缺失值:
df.query('Embarked.isnull()')
现在将显示 Embarked 列中缺少值的行:

其实可以直接在列名上调用各种 Series 方法:
df.query('Name.str.len() < 20') # find passengers whose name is
# less than 20 characters
df.query(f'Ticket.str.startswith("A")') # find all passengers whose
# ticket starts with A
比较数值列
我们还可以轻松比较数字列:
df.query('Fare > 50')
以下输出显示了票价大于 50 的所有行:

比较多个列
还可以使用 and、or 和 not 运算符比较多个列,以下语句检索 Fare 大于 50 和 Age 大于 30 的所有行:
df.query('Fare > 50 and Age > 30')
下面是查询结果

查询索引
通常当我们想根据索引值检索行时,可以使用 loc[] 索引器,如下所示:
df.loc[[1],:] # get the row whose index is 1; return as a dataframe
但是使用 query() 方法,使得事情变得更加直观:
df.query('index==1')
结果如下

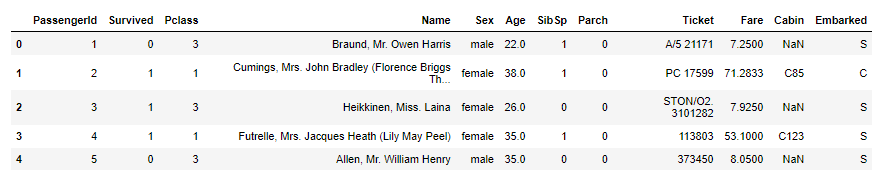
如果要检索索引值小于 5 的所有行:
df.query('index<5')
结果如下
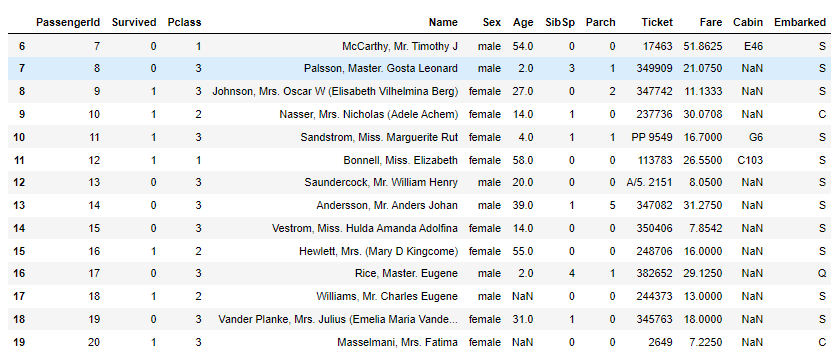
我们还可以指定索引值的范围:
df.query('6 <= index < 20')
结果如下
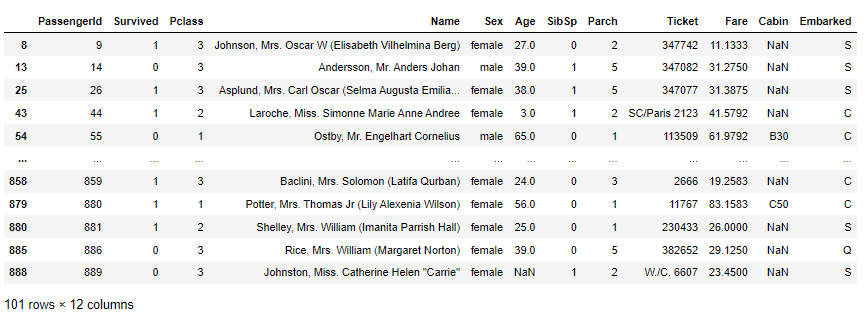
比较多列
我们还可以比较列之间的值,例如以下语句检索 Parch 值大于 SibSp 值的所有行:
df.query('Parch > SibSp')
结果如下
总结
从上面的示例可以看出,query() 方法使搜索行的语法更加自然简洁,希望感兴趣的小伙伴多加练习,真正的达到融会贯通的地步哦~
到此这篇关于Pandas Query方法使用深度总结的文章就介绍到这了,更多相关Pandas Query方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas查询数据df.query的使用
目录 使用dataframe条件表达式查询 复杂条件查询 使用df.query可以简化查询 方法对比:使用df[(df[“a”] > 3) & (df[“b”]<5)]的方式:使用df.query(“a>3 & b<5”)的方式: df = pd.read_csv("beijing_tianqi_2018.csv") df.head() ymd bWendu yWendu tianqi fengxiang fengli aqi aqiInfo
-
pandas之query方法和sample随机抽样操作
query方法 在 pandas 中,支持把字符串形式的查询表达式传入 query 方法来查询数据,其表达式的执行结果必须返回布尔列表.在进行复杂索引时,由于这种检索方式无需像普通方法一样重复使用 DataFrame 的名字来引用列名,一般而言会使代码长度在不降低可读性的前提下有所减少. 例如 In [61]: df.query('((School == "Fudan University")&' ....: ' (Grade == "Senior")&am
-

pandas 查询函数query的用法说明
query() 函数简介 pandas的query()方法是基于DataFrame列的计算代数式,对于按照某列的规则进行过滤的操作,可以使用query方法. 代码示例 import pandas as pd df = pd.DataFrame({'a':[1, 2, 3, 4, 5, 6], 'b':[1, 2, 3, 4, 5, 6], 'c':[1, 2, 3, 4, 5, 6]}) query_list = [1, 2] df_2 = df.query('c not in @query_l
-
Pandas使用query()优雅的查询实例
目录 常规用法 多条件查询 引用变量 索引选取 多索引选取 特殊字符 对于 Pandas 根据条件获取指定数据,相信大家都能够轻松的写出相应代码,但是如果你还没用过 query,相信你会被它的简洁所折服! 常规用法 先创建一个 DataFrame. import pandas as pd df = pd.DataFrame( {'A': ['e', 'd', 'c', 'b', 'a'], 'B': ['f', 'b', 'c', 'd', 'e'], 'C': ra
-
Pandas探索之高性能函数eval和query解析
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一. 相较于 Python 的内置函数, Pandas 库为我们提供了一系列性能更高的数据处理函数,本节将向大家介绍 Pandas 库
-
Pandas Query方法使用深度总结
目录 获取数据 载入数据 使用 query() 方法 以 In-place 的方式执行 query 方法 指定多个条件查询 比较数值列 比较多个列 查询索引 比较多列 总结 大多数 Pandas 用户都熟悉 iloc[] 和 loc[] 索引器方法,用于从 Pandas DataFrame 中检索行和列.但是随着检索数据的规则变得越来越复杂,这些方法也随之变得更加复杂而臃肿. 同时 SQL 也是我们经常接触且较为熟悉的语言,那么为什么不使用类似于 SQL 的东西来查询我们的数据呢 事实证明实际上
-
浅析ThinkPHP中execute和query方法的区别
初学ThinkPHP的时候,很多人都对execute()和query()方法的区别搞不懂,本文就此浅析二者的区别.大家都知道,ThinkPHP中execute()和query()方法都可以在参数里直接输入SQL语句.但是不同的是execute()通常用来执行insert或update等SQL语句,而query常用来执行select等语句. execute()方法将返回影响的记录数,如果执行SQL的select语句的话,返回的结果将是表的总记录数: 复制代码 代码如下: $model = M( "
-
连接pandas以及数组转pandas的方法
pandas转数组 np.array(pandas) 数组转pandas pandas.DataFrame(numpy) pandas连接,只是左右接上,不合并值 df = pd.concat([suojindf,df], axis=1) 以上这篇连接pandas以及数组转pandas的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
在Pycharm中安装Pandas库方法(简单易懂)
开发环境的搭建是一件入门比较头疼的事情,在上期的文稿基础上,增加一项Anaconda的安装介绍.Anaconda是Python的一个发行版本,安装好了Anaconda就相当于安装好了Python,并且里面还集成了很多Python科学计算的第三方库.比如我们需要用到的Pandas.numpy.dateutil等等,高达几百种.因此,安装了Anaconda,就不需要再专门的一个个安装第三方库.只要在使用Pycharm时调用Anaconda环境,便可以方便的使用其中的各种库.且各个库之间的依赖性很好,
-
pandas round方法保留两位小数的设置实现
pandas中可以使用round(n)方法返回 x 的小数点四舍五入到n个数字.简洁的说就是,四舍五入的保留小数点后的几个数字.round()不添加任何参数的时候,等同于round(0)就是取整.直接看例子: import pandas as pd import numpy as np df_round = pd.DataFrame(np.random.random([3, 3]), columns=['A', 'B', 'C'], index=['one', 'two', 'three'])
-
Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
python安装numpy和pandas的方法步骤
最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,不过使用python安装numpy和pandas因为linux环境没有外网遇到了很多问题就记下来了.首要条件,python版本必须是2.7以上. linux首先安装依赖包 yum -y install blas blas-devel lapack-devel lapack yum -y install seaborn scipy yum -y install freetype freetype-devel libpng lib
-
nodeJS express路由学习req.body与req.query方法实例详解
目录 引言 前端路由 后端路由 Express路由教学 GET/POST路由演示 详解req处理数据的方法 引言 所谓 路由 就是根据不同的 url 地址展示不同的内容或页面 形象点 举个栗子: 电话的拨号界面咱们都见过都使用过 你输入一串号码,就可以拨号给指定的联系人 路由也是这个道理,你请求不同的 url 地址,服务器给你展示不同的内容或页面. 假如我们有一台提供 Web 服务的服务器的网络地址是192.168.1.66:8080 然后我们的服务器下挂载有如下一个资源 192.168.1.6
-
利用numpy和pandas处理csv文件中的时间方法
环境:numpy,pandas,python3 在机器学习和深度学习的过程中,对于处理预测,回归问题,有时候变量是时间,需要进行合适的转换处理后才能进行学习分析,关于时间的变量如下所示,利用pandas和numpy对csv文件中时间进行处理. date (UTC) Price 01/01/2015 0:00 48.1 01/01/2015 1:00 47.33 01/01/2015 2:00 42.27 #coding:utf-8 import datetime import pandas as