一文教你Python如何创建属于自己的IP池
目录
- 开发环境
- 模块使用
- 如果安装python第三方模块
- 如何配置pycharm里面的python解释器
- pycharm如何安装插件
- 代理ip结构
- 思路
- 一. 数据来源分析
- 二. 代码实现步骤
- 代码
开发环境
Python 3.8
Pycharm
模块使用
requests >>> pip install requests
parsel >>> pip install parsel
如果安装python第三方模块
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
点击齿轮, 选择add
添加python安装路径
pycharm如何安装插件
选择file(文件) >>> setting(设置) >>> Plugins(插件)
点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
选择相应的插件点击 install(安装) 即可
安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
代理ip结构
proxies_dict = {
"http": "http://" + ip:端口,
"https": "http://" + ip:端口,
}
思路
一. 数据来源分析
找我们想要数据内容, 从哪里来的
二. 代码实现步骤
发送请求, 对于目标网址发送请求
获取数据, 获取服务器返回响应数据(网页源代码)
解析数据, 提取我们想要的数据内容
保存数据, 爬音乐 视频 本地csv 数据库… IP检测, 检测IP代理是否可用 可用用IP代理 保存
- from 从
- import 导入
- 从 什么模块里面 导入 什么方法
- from xxx import * # 导入所有方法
代码
# 导入数据请求模块
import requests # 数据请求模块 第三方模块 pip install requests
# 导入 正则表达式模块
import re # 内置模块
# 导入数据解析模块
import parsel # 数据解析模块 第三方模块 pip install parsel >>> 这个是scrapy框架核心组件
lis = []
lis_1 = []
# 1. 发送请求, 对于目标网址发送请求 https://www.kuaidaili.com/free/
for page in range(11, 21):
url = f'https://www.kuaidaili.com/free/inha/{page}/' # 确定请求url地址
"""
headers 请求头 作用伪装python代码
"""
# 用requests模块里面get 方法 对于url地址发送请求, 最后用response变量接收返回数据
response = requests.get(url)
# <Response [200]> 请求之后返回response响应对象, 200状态码表示请求成功
# 2. 获取数据, 获取服务器返回响应数据(网页源代码) response.text 获取响应体文本数据
# print(response.text)
# 3. 解析数据, 提取我们想要的数据内容
"""
解析数据方式方法:
正则: 可以直接提取字符串数据内容
需要把获取下来html字符串数据 进行转换
xpath: 根据标签节点 提取数据内容
css选择器: 根据标签属性提取数据内容
哪一种方面用那种, 那是喜欢用那种
"""
# 正则表达式提取数据内容
"""
# 正则提取数据 re.findall() 调用模块里面的方法
# 正则 遇事不决 .*? 可以匹配任意字符(除了换行符\n以外) re.S
ip_list = re.findall('<td data-title="IP">(.*?)</td>', response.text, re.S)
port_list = re.findall('<td data-title="PORT">(.*?)</td>', response.text, re.S)
print(ip_list)
print(port_list)
"""
# css选择器:
"""
# css选择器提取数据 需要把获取下来html字符串数据(response.text) 进行转换
# 我不会css 或者 xpath 怎么办
# #list > table > tbody > tr > td:nth-child(1)
# //*[@id="list"]/table/tbody/tr/td[1]
selector = parsel.Selector(response.text) # 把html 字符串数据转成 selector 对象
ip_list = selector.css('#list tbody tr td:nth-child(1)::text').getall()
port_list = selector.css('#list tbody tr td:nth-child(2)::text').getall()
print(ip_list)
print(port_list)
"""
# xpath 提取数据
selector = parsel.Selector(response.text) # 把html 字符串数据转成 selector 对象
ip_list = selector.xpath('//*[@id="list"]/table/tbody/tr/td[1]/text()').getall()
port_list = selector.xpath('//*[@id="list"]/table/tbody/tr/td[2]/text()').getall()
# print(ip_list)
# print(port_list)
for ip, port in zip(ip_list, port_list):
# print(ip, port)
proxy = ip + ':' + port
proxies_dict = {
"http": "http://" + proxy,
"https": "http://" + proxy,
}
# print(proxies_dict)
lis.append(proxies_dict)
# 4.检测IP质量
try:
response = requests.get(url=url, proxies=proxies_dict, timeout=1)
if response.status_code == 200:
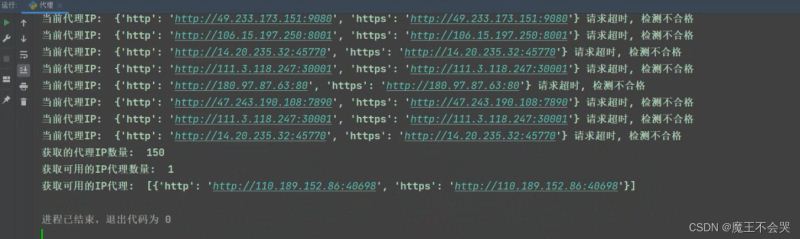
print('当前代理IP: ', proxies_dict, '可以使用')
lis_1.append(proxies_dict)
except:
print('当前代理IP: ', proxies_dict, '请求超时, 检测不合格')
print('获取的代理IP数量: ', len(lis))
print('获取可用的IP代理数量: ', len(lis_1))
print('获取可用的IP代理: ', lis_1)
dit = {
'http': 'http://110.189.152.86:40698',
'https': 'http://110.189.152.86:40698'
}
到此这篇关于一文教你Python如何创建属于自己的IP池的文章就介绍到这了,更多相关Python创建IP池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python简单构建可用IP代理池
以下为简单示例: import requests import re import telnetlib url='http://www.66ip.cn/nmtq.php?getnum=100000&isp=0&anonymoustype=4&start=&ports=&export=&ipaddress=&area=2&proxytype=0&api=66ip' header = {'User-agent':'xxxxxxxxxxx'
-
python实现ip代理池功能示例
本文实例讲述了python实现ip代理池功能.分享给大家供大家参考,具体如下: 爬取的代理源为西刺代理. 用xpath解析页面 用telnet来验证ip是否可用 把有效的ip写入到本地txt中.当然也可以写入到redis.mongodb中,也可以设置检测程序当代理池中的ip数不够(如:小于20个)时,启动该脚本来重新获取ip,本脚本的代码也要做相应的改变. # !/usr/bin/env python # -*- coding: utf-8 -*- # @Version : 1.0 # @Tim
-
用python构建IP代理池详解
目录 概述 提供免费代理的网站 代码 导包 网站页面的url ip地址 检测 整理 必要参数 总代码 总结 概述 用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉.对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问:而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题. 目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差
-
Python爬虫代理IP池实现方法
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来.不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务. 1.问题 代理IP从何而来? 刚自学爬虫的时候没有代理IP就去西刺.快代理之类有免费代理的网站去爬,还是有个别代理能用.当然,如果你有更好的代理接口也可以自己接入. 免费代理的采集也很简单,无非就是:访问页面页面 -> 正则/xpath提
-
Python利用selenium建立代理ip池访问网站的全过程
目录 一.使用selenium前? 1.安装selenium 2.安装浏览器驱动 3.配置环境 二.使用selenium 1.引入库 2.完整代码 总结 一.使用selenium前? 1.安装selenium pip install Selenium 2.安装浏览器驱动 Chrome驱动文件下载:点击下载 3.配置环境 1.将下载文件放进C:\Program Files (x86)\Google\Chrome\Application下就可以 2.然后配置下系统变量:我的电脑–>属性–>系统设置
-
一文教你Python如何创建属于自己的IP池
目录 开发环境 模块使用 如果安装python第三方模块 如何配置pycharm里面的python解释器 pycharm如何安装插件 代理ip结构 思路 一. 数据来源分析 二. 代码实现步骤 代码 开发环境 Python 3.8 Pycharm 模块使用 requests >>> pip install requests parsel >>> pip install parsel 如果安装python第三方模块 win + R 输入 cmd 点击确定, 输入安装命令
-
Python列表创建与销毁及缓存池机制
目录 列表的创建 列表的销毁 小结 列表的创建 创建列表,Python底层只提供了唯一一个Python/C API,也就是PyList_New.这个函数接收一个size参数,允许我们在创建一个PyListObject对象时指定底层的PyObject *数组的长度. PyObject * PyList_New(Py_ssize_t size) { //声明一个PyListObject *对象 PyListObject *op; #ifdef SHOW_ALLOC_COUNT static int
-
Python批量创建迅雷任务及创建多个文件
其实不是真的创建了批量任务,而是用python创建一个文本文件,每行一个要下载的链接,然后打开迅雷,复制文本文件的内容,迅雷监测到剪切板变化,弹出下载全部链接的对话框~~ 实际情况是这样的,因为用python分析网页非常,比如下载某页中的全部pdf链接 from __future__ import unicode_literals from bs import BeautifulSoup import requests import codecs r = requests.get('you ur
-
Python中创建字典的几种方法总结(推荐)
1.传统的文字表达式: >>> d={'name':'Allen','age':21,'gender':'male'} >>> d {'age': 21, 'name': 'Allen', 'gender': 'male'} 如果你可以事先拼出整个字典,这种方式是很方便的. 2.动态分配键值: >>> d={} >>> d['name']='Allen' >>> d['age']=21 >>> d[
-
Python从零开始创建区块链
作者认为最快的学习区块链的方式是自己创建一个,本文就跟随作者用Python来创建一个区块链. 对数字货币的崛起感到新奇的我们,并且想知道其背后的技术--区块链是怎样实现的. 但是完全搞懂区块链并非易事,我喜欢在实践中学习,通过写代码来学习技术会掌握得更牢固.通过构建一个区块链可以加深对区块链的理解. 准备工作 本文要求读者对Python有基本的理解,能读写基本的Python,并且需要对HTTP请求有基本的了解. 我们知道区块链是由区块的记录构成的不可变.有序的链结构,记录可以是交易.文件或任何你
-
python实现创建新列表和新字典,并使元素及键值对全部变成小写
如下所示: lists = ['tom','Jack','luCy','lily','jErry','anna'] dics = {'jack':'python','Lucy':'jaVa','jeRry':'rUby','lily':'c#',} new_lists = [] for i in lists: new_lists.append(i.lower()) print(new_lists) new_dics = {} for i,j in dics.items(): new_dics[i
-
python批量创建指定名称的文件夹
本文实例为大家分享了python批量创建指定名称的文件夹具体代码,供大家参考,具体内容如下 继删除多余文件之后,做了一些数据处理,需要重新保存数据,但文件夹的名称又不能改 所以只能创建新的文件夹,换个路径用之前的文件夹名 import os import glob #txt文件生成一次就好,或者用os.walk遍历需要的文件夹名称路径 def mk_text(txt_path): folders = glob.glob(txt_path + '/*_1') writeText = open('F
-
python 实现创建文件夹和创建日志文件的方法
一.实现创建文件夹和日志 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author: nulige import os import datetime #获取系统时间 log_path_suffix = datetime.datetime.now().strftime('%Y-%m-%d ') #创建文件夹 folder_name = '\log' root_directory = 'D:\python\disk_monitor' try: os
-
python 模拟创建seafile 目录操作示例
本文实例讲述了python 模拟创建seafile 目录操作.分享给大家供大家参考,具体如下: # !/usr/bin/env python # -*- coding: utf-8 -*- import urllib2 import urllib import cookielib import json import httplib import re import requests import StringIO import time import sys import json impor
-
对Python中创建进程的两种方式以及进程池详解
在Python中创建进程有两种方式,第一种是: from multiprocessing import Process import time def test(): while True: print('---test---') time.sleep(1) if __name__ == '__main__': p=Process(target=test) p.start() while True: print('---main---') time.sleep(1) 上面这段代码是在window