一篇文章搞懂:词法作用域、动态作用域、回调函数及闭包
前言
把以前一直只限于知道,却不清晰理解的这几个概念完完整整地梳理了一番。内容参考自wiki页面,然后加上自己一些理解。
词法作用域和动态作用域
不管什么语言,我们总要学习作用域(或生命周期)的概念,比如常见的称呼:全局变量、包变量、模块变量、本地变量、局部变量等等。不管如何称呼这些作用域的范围,实现它们的目的都一样:
(1)为了避免名称冲突;
(2)为了限定变量的生命周期(本文以变量名说事,其它的名称在规则上是一样的)。
但是不同语言的作用域规则不一样,虽然学个简单的基础就足够应用,因为我们有编程规范:(1)尽量避免名称冲突;(2)加上类似于local的修饰符尽量缩小生效范围;(3)放进代码块,等等。但是真正去细心验证作用域的生效机制却并非易事(我学Python的时候,花了很长时间细细验证,学perl的时候又花了很长时间细细验证),但可以肯定的是,理解本文的词法作用域规则(Lexical scoping)和动态作用域规则(dynamic scoping),对学习任何语言的作用域规则都有很大帮助,这两个规则是各种语言都宏观通用的。
很简单的一段bash下的代码:
x=1
function g(){ echo "g: $x" ; x=2; }
function f(){ local x=3 ; g; echo "f: $x"; } # 输出2还是3
f # 输出1还是3?
echo $x # 输出1还是2?
对于bash来说,上面输出的分别是3(g函数中echo)、2(f函数中的echo)和1(最后一行echo)。但是同样语义的代码在其它语言下得到的结果可能就不一样(分别输出1、3和2,例如perl中将local替换为my)。
这牵扯到两种贯穿所有程序语言的作用域概念:词法作用域(类似于C语言中static)和动态作用域。词法作用域和"词法"这个词真的没什么关系,反而更应该称之为"文本段作用域"。要区别它们,只需要回答"函数out_func中嵌套的内层函数in_func能否看见out_func中的环境"。
对于上面的bash代码来说,假如这段代码是适用于所有语言的伪代码:
对于词法作用域的语言,执行f时会调用g,g将无法访问f文本段的变量,词法作用域认为g并不是f的一部分,而是跳出f的,因为g的定义文本段是在全局范围内的,所以它是全局文本段的一部分。如果函数g的定义文本段是在f内部,则g属于f文本段的一部分。
- 所以g不知道f文本段中
local x=3的设置,于是g的echo会输出全局变量x=1,然后设置x=2,因为它没有加上作用域修饰符,而g又是全局内的函数,所以x将修改全局作用域的x值,使得最后的echo输出2,而f中的echo则输出它自己文本段中的local x=3。所以整个流程输出1 3 2
对于动态作用域的语言,执行f时会调用g,g将可以访问f文本中的变量,动态作用域认为g是f文本段的一部分,是f中的嵌套函数。
- 所以g能看到
local x=3的设置,所以g的echo会输出3。g中设置x=2后,仅仅只是在f的内层嵌套函数中设置,所以x=2对g文本段和f文本段(因为g是f的一部分)都可见,但对f文本段外部不可见,所以f中的echo输出2,最后一行的echo输出1。所以整个流程输出3 2 1
总结来说:
- 词法作用域是关联在编译期间的,对于函数来说就是函数的定义文本段的位置决定这个函数所属的范围。
- 动态作用域是关联在程序执行期间的,对于函数来说就是函数执行的位置决定这个函数所属的范围。
由于bash实现的是动态作用域规则。所以,输出的是3 2 1。对于perl来说,my修饰符实现词法作用域规则,local修饰符实现动态作用域规则。
例如,使用my修饰符的perl程序:
#!/usr/bin/perl
$x=1;
sub g { print "g: $x\n"; $x=2; }
sub f { my $x=3; g(); print "f: $x\n"; } # 词法作用域
f();
print "$x\n";
执行结果:
[fairy@fairy:/perlapp]$ perl scope2.pl
g: 1
f: 3
2
使用local修饰符的perl程序:
#!/usr/bin/perl
$x=1;
sub g { print "g: $x\n"; $x=2; }
sub f { local $x=3; g(); print "f: $x\n"; } # 动态作用域
f();
print "$x\n";
执行结果:
[fairy@fairy:/perlapp]$ perl scope2.pl
g: 3
f: 2
1
有些语言只支持一种作用域规则,特别是那些比较现代化的语言,而有些语言支持两种作用域规则(正如perl语言,my实现词法变量作用域规则,local实现动态作用域规则)。相对来说,词法作用域规则比较好控制整个流程,还能借此实现更丰富的功能(如最典型的"闭包"以及高阶函数),而动态作用域由于让变量生命周期"没有任何深度"(回想一下shell脚本对函数和作用域的控制,非常傻瓜化),比较少应用上,甚至有些语言根本不支持动态作用域。
闭包和回调函数
理解闭包、回调函数不可不知的术语
1.引用(reference):数据对象和它们的名称
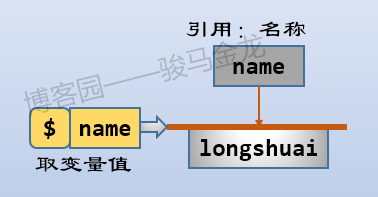
前文所说的可见、不可见、变量是否存在等概念,都是针对变量名(或其它名称,如函数名、列表名、hash名)而言的,和变量的值无关。名称和值的关系是引用(或指向)关系,赋值的行为就是将值所在的数据对象的引用(指针)交给名称,让名称指向这个内存中的这个数据值对象。如下图:
2.一级函数(first-class functions)和高阶函数(high-order functions)
有些语言认为函数就是一种类型,称之为函数类型,就像变量一样。这种类型的语言可以:
将函数赋值给某个变量,那么这个变量就是这个函数体的另一个引用,就像是第二个函数名称一样。通过这个函数引用变量,可以找到函数体,然后调用执行。
- 例如perl中
$ref_func=\&myfunc表示将函数myfunc的引用赋值给$ref_func,那么$ref_func也指向这个函数。
将函数作为另一个函数的参数。例如两个函数名为myfunc和func1,那么myfunc(func1)就将func1作为myfunc的参数。
- 这种行为一般用于myfunc函数中对满足某些逻辑的东西执行func1函数。
- 举个简单的例子,unix下的find命令,将find看作是一个函数,它用于查找指定路径下符合条件的文件名,将
-print、-exec {}\;选项实现的功能看作是其它的函数(请无视它是否真的是函数),这些选项对应的函数是find函数的参数,每当find函数找到符合条件的文件名时,就执行-print函数输出这个文件名
函数的返回值也可以是另一个函数。例如myfunc函数的定义语句为function myfunc(){ ...return func1 }。
其实,实现上面三种功能的函数称之为一级函数或高阶函数,其中高阶函数至少要实现上面的2和3。一级函数和高阶函数并没有区分的必要,但如果一定要区分,那么:
- 一级函数更像是一种术语概念,它将函数当作一种值看待,可以将其赋值出去、作为参数传递出去以及作为返回值,对于计算机程序语言而言,它更多的是用来描述某种语言是否支持一级函数;
- 高阶函数是一种函数类型,就像回调函数一样,当某个函数符合高阶函数的特性,就可以将其称之为这是一个高阶函数。
3.自由变量(free variable)和约束变量(bound variable)
这是一组数学界的术语。
在计算机程序语言中,自由变量是指函数中的一种特殊变量,这种变量既不在本函数中定义,也不是本函数的参数。换句话说,可能是外层函数中定义的但却在内层函数中使用的,所以自由变量常常和"非本地变量"(non-local variable,熟悉Python的人肯定知道)互用。例如:
function func1(x){
var z;
function func2(y){
return x+y+z # x和z既不是func2内部定义的,也不是func2的参数,所以x和z都是自由变量
}
return func1
}
自由变量和约束变量对应。所谓约束变量,是指这个变量之前是自由变量,但之后会对它进行赋值,将自由变量绑定到一个值上之后,这个变量就成为约束变量或者称为绑定变量。
例如:
function func1(x){
var m=20 # 对func2来说,这是自由变量,对其赋值,所以m变成了bound variable
var z
function func2(y){
z=10 # 对自由变量z赋值,z变成bound variable
return m+x+y+z # m、x和z都是自由变量
}
return func1
}
ref_func=func1(3) # 对x赋值,x变成bound variable
回调函数
回调函数一开始是C里面的概念,它表示的是一个函数:
- 可以访问另一个函数
- 当这个函数执行完了,会执行另一个函数
也就是说,将一个函数(B)作为参数传递给另一个函数(A),但A执行完后,再自动调用B。所以这种回调函数的概念也称为"call after"。
但是现在回调函数已经足够通用化了。通用化的回调函数定义为:将函数B作为另一个函数A的参数,执行到函数A中某个地方的时候去调用B。和原来的概念相比,不再是函数A结束后再调用,而是我们自己定义在哪个地方调用。
例如,Perl中的File::Find模块中的find函数,通过这个函数加上回调函数,可以实现和unix find命令相同的功能。例如,搜索某个目录下的文件,然后print输出这个文件名,即find /path xxx -print。
#!/usr/bin/perl
use File::Find;
sub print_path { # 定义一个函数,用于输出路径名称
print "$File::Find::name\n";
}
$callback = \&print_path; # 创建一个函数引用,名为$callback,所以perl是一种支持一级函数的语言
find( $callback,"/tmp" ); # 查找/tmp下的文件,每查找到一个文件,就执行一次$callback函数
这里传递给find函数的$callback就是一个回调函数。几个关键点:
$callback作为参数传递给另一个find()函数(所以find()函数是一个高阶函数)- 在find()函数中,每查找到一个文件,就调用一次这个
$callback函数。当然,如果find是我们自己写的程序,就可以由我们自己定义在什么地方去调用$callback $callback不是我们主动调用的,而是由find()函数在某些情况下(每查找到一个文件)去调用的
回调就像对函数进行填空答题一样,根据我们填入的内容去复用填入的函数从而实现某一方面的细节,而普通函数则是定义了就只能机械式地复用函数本身。
之所以称为回调函数,是因为这个函数并非由我们主观地、直接地去调用,而是将函数作为一个参数,通过被调用者间接去调用这个函数参数。本质上,回调函数和一般的函数没有什么区别,可能只是因为我们定义一个函数,却从来没有直接调用它,这一点感觉上有点奇怪,所以有人称之为"回调函数",用来统称这种间接的调用关系。
回调函数可以被多线程异步执行。
彻底搞懂闭包
计算机中的闭包概念是从数学世界引入的,在计算机程序语言中,它也称为词法闭包、函数闭包。
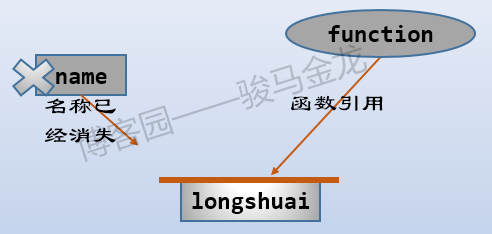
闭包简单的、通用的定义是指:函数引用一个词法变量,在函数或语句块结束后(变量的名称消失),词法变量仍然对引用它的函数有效。在下一节还有关于闭包更严格的定义(来自wiki)。
看一个python示例:函数f中嵌套了函数g,并返回函数g
def f(x): def g(y): return x + y return g # 返回一个闭包:有名称的函数(高阶函数的特性) # 将执行函数时返回的闭包函数赋值给变量(高阶函数的特性) a = f(1) # 调用存储在变量中闭包函数 print (a(5)) # 无需将闭包存储进临时变量,直接一次性调用闭包函数 print( f(1)(5) ) # f(1)是闭包函数,因为没有将其赋值给变量,所以f(1)称为"匿名闭包"
上面的a是一个闭包,它是函数g()的一个实例。f()的参数x可以被g访问,在f()返回g函数后,f()就退出了,随之消失的是变量名x(注意是变量名称x,变量的值在这里还不一定会消失)。当将闭包f(1)赋值给a后,原来x指向的数据对象(即数值1)仍被a指向的闭包函数引用着,所以x对应的值1在x消失后仍保存在内存中,只有当名为a的闭包被消除后,原来x指向的数值1才会消失。
闭包特性1:对于返回的每个闭包g()来说,不同的g()引用不同的x对应的数据对象。换句话说,变量x对应的数据对象对每个闭包来说都是相互独立的
例如下面得到两个闭包,这两个闭包中持有的自由变量虽然都引用相等的数值1,但两个数值是不同数据对象,这两个闭包也是相互独立的:
a=f(1) b=f(1)
闭包特性2:对于某个闭包函数来说,只要这不是一个匿名闭包,那么闭包函数可以一直访问x对应的数据对象,即使名称x已经消失
但是
a=f(1) # 有名称的闭包a,将一直引用数值对象1 a(3) # 调用闭包函数a,将返回1+3=4,其中1是被a引用着的对象,即使a(3)执行完了也不放开 a(3) # 再次调用函数a,将返回4,其中1和上面一条语句的1是同一个数据对象 f(1)(3) # 调用匿名的闭包函数,数据对象1在f(1)(3)执行完就消失 f(1)(3) # 调用匿名的闭包函数,和上面的匿名闭包是相互独立的
最重要的特性就在于上面执行的两次a(3):将词法变量的生命周期延长,但却足够安全。
看下面perl程序中的闭包函数,可以更直观地看到结果。
sub how_many { # 定义函数
my $count=2; # 词法变量$count
return sub {print ++$count,"\n"}; # 返回一个匿名函数,这是一个匿名闭包
}
$ref=how_many(); # 将闭包赋值给变量$ref
how_many()->(); # (1)调用匿名闭包:输出3
how_many()->(); # (2)调用匿名闭包:输出3
$ref->(); # (3)调用命名闭包:输出3
$ref->(); # (4)再次调用命名闭包:输出4
上面将闭包赋值给$ref,通过$ref去调用这个闭包,则即使how_many中的$count在how_many()执行完就消失了,但$ref指向的闭包函数仍然在引用这个变量,所以多次调用$ref会不断修改$count的值,所以上面(3)和(4)先输出3,然后输出改变后的4。而上面(1)和(2)的输出都是3,因为两个how_many()函数返回的是独立的匿名闭包,在语句执行完后数据对象3就消失了。
闭包更严格的定义
注意,严格定义的闭包和前面通俗定义的闭包结果上是不一样的,通俗意义上的闭包并不一定符合严格意义上的闭包。
关于闭包更严格的定义,是一段谁都看不懂的说明(来自wiki)。如下,几个关键词我加粗显示了,因为重要。
闭包是一种在支持一级函的编程语言中能够将词法作用域中的变量名称进行绑定的技术。在操作上,闭包是一种用于保存函数和环境的记录。这个环境记录了一些关联性的映射,将函数的每个自由变量与创建闭包时所绑定名称的值或引用相关联。通过闭包,就算是在作用域外部调用函数,也允许函数通过闭包拷贝他们的值或通过引用的方式去访问那些已经被捕获的变量。
我知道这段话谁都看不懂,所以简而言之一下:一个函数实例和一个环境结合起来就是闭包。这个所谓的环境,决定了这个函数的特殊性,决定了闭包的特性。
还是上面的python示例:函数f中嵌套了函数g,并返回函数g
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数
# 将执行函数时返回的闭包函数赋值给变量
a = f(1)
上面的a是一个闭包,它是函数g()的一个实例。f()的参数x可以被g访问,对于g()来说,这个x不是g()内部定义的,也不是g()的参数,所以这个x对于g来说是一个自由变量(free variable)。虽然g()中持有了自由变量,但是g()函数自身不是闭包函数,只有在g持有的自由变量x和传递给f()函数的x的值(即f(1)中的1)进行绑定的时候,才会从g()创建一个闭包函数,这表示闭包函数开始引用这个自由变量,并且这个闭包一直持有这个变量的引用,即使f()已经执行完毕了。然后在f()中return这个闭包函数,因为这个闭包函数绑定了(引用)自由变量x,这就是闭包函数所在的环境。
环境对闭包来说非常重要,是区别普通函数和闭包的关键。如果返回的每个闭包不是独立持有属于自己的自由变量,而是所有闭包都持有完全相同的自由变量,那么闭包虽然仍可称为闭包,但和普通函数却没有区别了。例如:
def f(x):
x=3
def g(y):
return x + y
return g
a = f(1)
b = f(3)
在上面的示例中,x虽然是自由变量,但却在g()的定义之前就绑定了值(前文介绍过,它称为bound variable),使得闭包a和闭包b持有的不再是自由变量,而是值对象完全相同的绑定变量,其值对象为3,a和b这个时候其实没有任何区别(虽然它们是不同对象)。换句话说,有了闭包a就完全没有必要再定义另一个功能上完全相同的闭包b。
在函数复用性的角度上来说,这里的a和普通函数没有任何区别,都只是简单地复用了函数体。而真正严格意义上的闭包,除了复用函数体,还复用它所在的环境。
但是这样一种情况,对于通俗定义的闭包来说,返回的g()也是一个闭包,但在严格定义的闭包中,这已经不算是闭包。
再看一个示例:将自由变量x放在g()函数定义文本段的后面。
def f(y): return x+y x=1 def g(z): x=3 return f(z) print(g(1)) # 输出2,而不是4
首先要说明的是,python在没有给任何作用域修饰符的时候实现的词法作用域规则,所以上面return f(z)中的f()看见的是全局变量x(因为f()定义在全局文本段中),而不是g()中的x=3。
回到闭包问题上。上面f()持有一个自由变量x,这个f(z)的文本定义段是在全局文本段中,它绑定的自由变量x是全局变量(声明并初始化为空或0),但是这个变量之后赋值为1了。对于g()中返回的每个f()所在的环境来说,它持有的自由变量x一开始都是不确定的,但是后来都确定为1了。这种情况也不能称之为闭包,因为闭包是在f()对自由变量进行绑定时创建的,而这个时候x已经是固定的值对象了。
回调函数、闭包和匿名函数
回调函数、闭包和匿名函数其实没有必然的关系,但因为很多书上都将匿名函数和回调函数、闭包放在一起解释,让人误以为回调函数、闭包需要通过匿名函数实现。实际上,匿名函数只是一个有函数定义文本段,却没有名称的函数,而闭包则是一个函数的实例加上一个环境(严格意义上的定义)。
对于闭包和匿名函数来说,仍然以python为例:
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数
def h(x):
return lambda y: x + y # 返回一个闭包:匿名函数
# 将执行函数时返回的闭包函数赋值给变量
a = f(1)
b = h(1)
# 调用存储在变量中闭包函数
print (a(5))
print (b(5))
对于回调函数和匿名函数来说,仍然以perl的find函数为例:
#!/usr/bin/perl
use File::Find;
$callback = sub {
print "$File::Find::name\n";
}; # 创建一个匿名函数以及它的引用
find( $callback,"/tmp" ); # 查找/tmp下的文件,每查找到一个文件,就执行一次$callback函数
匿名函数让闭包的实现更简洁,所以很多时候返回的闭包函数就是一个匿名函数实例。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
perl 模式匹配参数详解
一.简介 模式指在字符串中寻找的特定序列的字符,由反斜线包含:/def/即模式def.其用法如结合函数split将字符串用某模式分成多个单词:@array = split(/ /, $line);二.匹配操作符 =~.!~ =~检验匹配是否成功:$result = $var =~ /abc/;若在该字符串中找到了该模式,则返回非零值,即true,不匹配则返回0,即false.!~则相反. 这两个操作符适于条件控制中,如: if ($question =~ /please/) {
-
perl操作符详细说明
一.算术操作符 :+(加).-(减).*(乘)./(除).**(乘幂).%(取余).-(单目负) (1)乘幂的基数不能为负,如 (-5) ** 2.5 # error: (2)乘幂结果不能超出计算机表示的限制,如10 ** 999999 # error (3)取余的操作数如不是整数,四舍五入成整数后运算:运算符右侧不能为零 (4)单目负可用于变量: - $y ; # 等效于 $y * -1二.整数比较操作符 Table 3.1. 整数比较操作符 操作符 描述 < 小于 > 大于 ==
-
perl 基本语法介绍
一.数据类型(Data type): Perl 的数据类型大致分为四种:Scalar(变量).Scalar Array(数组).Hash Array(散列).References(指针),看起来虽少但用起来却绰绰有余.尤其在写Perl程序时可以不必事先宣告变量,这一点对刚学程序语言的人甚为方便,不过为了以后程序除错和维护方便,我建议你还是养成事先声明变量的习惯比较好. 1 Scalar(纯量变量): 纯量变量是Perl里最基本的一种数据型态,它可以代表一个字符.字符串.整数.甚至浮点数,而Per
-

一篇文章搞懂Go语言中的Context
目录 0 前置知识sync.WaitGroup 1 简介 2 context.Context引入 3 context包的其他常用函数 3.1 context.Background和context.TODO 3.2 context.WithCancel和 3.3 context.WithTimeout 3.4 context.WithDeadline 3.5 context.WithValue 4 实例:请求浏览器超时 5 Context包都在哪些地方使用 6 小结 0 前置知识sync.Wait
-
一篇文章搞懂JavaScript正则表达式之方法
咱们来看看JavaScript中都有哪些操作正则的方法. RegExp RegExp 是正则表达式的构造函数. 使用构造函数创建正则表达式有多种写法: new RegExp('abc'); // /abc/ new RegExp('abc', 'gi'); // /abc/gi new RegExp(/abc/gi); // /abc/gi new RegExp(/abc/m, 'gi'); // /abc/gi 它接受两个参数:第一个参数是匹配模式,可以是字符串也可以是正则表达式:第二个参数是
-
一篇文章搞懂python的转义字符及用法
什么是转义字符 转义字符是一个计算机专业词汇.在计算机当中,我们可以写出123 ,也可以写出字母abcd,但有些字符我们无法手动书写,比如我们需要对字符进行换行处理,但不能写出来换行符,当然我们也看不见换行符.像这种情况,我们需要在字符中使用特殊字符时,就需要用到转义字符,在python里用反斜杠\转义字符. 在交互式解释器中,输出的字符串用引号引起来,特殊字符用反斜杠\转义.虽然可能和输入看上去不太一样,但是两个字符串是相等的. 在python里,转义字符\可以转义很多字符,比如\n表示换行,
-
一篇文章搞懂Python反斜杠的相关问题
大家在开发Python的过程中,一定会遇到很多反斜杠的问题,很多人被反斜杠的数量搞得头大. 首先我们写一段非常简单的Python代码,它的作用是把一个字段先转换为JSON格式的字符串,然后把这个字符串再转换为JSON格式的字符串: import json info = {'name': 'kingname', 'address': '杭州', 'salary': 99999} info_json = json.dumps(info) # 第一次转换以后,打印出来 print(info_json)
-
一篇文章搞懂Python Unittest测试方法的执行顺序
目录 Unittest 回到主题 源码初窥 回到问题的本质 1. 以字典序的方式编写test方法 2. 回归本质,从根本解决问题 总结 Unittest unittest大家应该都不陌生.它作为一款博主在5-6年前最常用的单元测试框架,现在正被pytest,nose慢慢蚕食. 渐渐地,看到大家更多的讨论的内容从unittest+HTMLTestRunner变为pytest+allure2等后起之秀. 不禁感慨,终究是自己落伍了,跟不上时代的大潮了. 回到主题 感慨完了,回到正文.虽然unitte
-
一篇文章搞懂MySQL加锁机制
目录 前言 锁的分类 乐观锁和悲观锁 共享锁(S锁)和排他锁(X锁) 按加锁粒度区分 全局锁 表级锁(表锁和MDL锁) 意向锁 行锁 间隙锁 next-key lock(临键锁) 加锁规则 死锁和死锁检测 总结 前言 在数据库中设计锁的目的是为了处理并发问题,在并发对资源进行访问时,数据库要合理控制对资源的访问规则. 而锁就是用来实现这些访问规则的一个数据结构. 在对数据并发操作时,没有锁可能会引起数据的不一致,导致更新丢失. 锁的分类 乐观锁和悲观锁 乐观锁: 对于出现更新丢失的可能性比较乐观
-
一篇文章搞懂Vue3中如何使用ref获取元素节点
目录 前言 1.回顾 Vue2 中的 ref 2.Vue3 中 ref 访问元素 3.v-for 中使用 ref 4.ref 绑定函数 5.组件上使用 ref 总结 前言 虽然在 Vue 中不提倡我们直接操作 DOM,毕竟 Vue 的理念是以数据驱动视图.但是在实际情况中,我们有很多需求都是需要直接操作 DOM 节点的,这个时候 Vue 提供了一种方式让我们可以获取 DOM 节点:ref 属性.ref 属性是 Vue2 和 Vue3 中都有的,但是使用方式却不大一样,这也导致了很多从 Vue2
-
一篇文章搞懂:词法作用域、动态作用域、回调函数及闭包
前言 把以前一直只限于知道,却不清晰理解的这几个概念完完整整地梳理了一番.内容参考自wiki页面,然后加上自己一些理解. 词法作用域和动态作用域 不管什么语言,我们总要学习作用域(或生命周期)的概念,比如常见的称呼:全局变量.包变量.模块变量.本地变量.局部变量等等.不管如何称呼这些作用域的范围,实现它们的目的都一样: (1)为了避免名称冲突; (2)为了限定变量的生命周期(本文以变量名说事,其它的名称在规则上是一样的). 但是不同语言的作用域规则不一样,虽然学个简单的基础就足够应用,因为我们有
-
一篇文章搞懂Python的类与对象名称空间
代码块的分类 python中分几种代码块类型,它们都有自己的作用域,或者说名称空间: 文件或模块整体是一个代码块,名称空间为全局范围 函数代码块,名称空间为函数自身范围,是本地作用域,在全局范围的内层 函数内部可嵌套函数,嵌套函数有更内一层的名称空间 类代码块,名称空间为类自身 类中可定义函数,类中的函数有自己的名称空间,在类的内层 类的实例对象有自己的名称空间,和类的名称空间独立 类可继承父类,可以链接至父类名称空间 正是这一层层隔离又连接的名称空间将变量.类.对象.函数等等都组织起来,使得它
-
一篇文章搞懂python混乱的切换操作与优雅的推导式
前言 因为工作中不怎么使用python,所以对python的了解不够,只是在使用的时候才去学,在之前的几个例子中几乎没使用什么python的特有语法,本着完成任务优先的原则也没有深入,但是在阅读别人的代码的时候发现有些特有语法不是很熟悉,搞不清代码的真正意思,今天就搞清楚切片和推导式的使用,OK.我们开始吧 记忆点:正向的时候第一个是0,负向的时候第一个是-1,可以把列表当做一个换,正向的是1 ,负向的 是-1,0 是中间点 1.混乱的切片操作 一个完整的切片表达式包含两个":",用于