Python之ascii转中文的实现
看代码吧~
name = r"\u6697\u88d4\u5251\u9b54"
print(name.encode('ascii').decode('unicode_escape'))
或
print(name.encode().decode('unicode_escape'))
补充:python 汉字与ASCII互相转换
一、代码段
#python ASCII转汉字 name = r"\u5f20\u5357\u74dc" print(name.encode(‘ascii').decode(‘unicode_escape')) #python 汉字转ASCII name1=“张南瓜” print(name1.encode(‘unicode_escape').decode(‘ascii'))
二、运行结果:
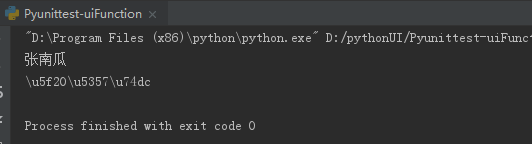
利用的是python中的encode()和decode()函数,具体的原理和细节我还没有弄清楚,记录下
补充:python Unicode /ASCII转utf-8( 中文)
decode(‘unicode-escape')
例如:
str='\u5927\u592b' str.encode(‘utf-8').decode(‘unicode-escape')
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python3的unicode编码转换成中文的问题及解决方案
这篇文章主要介绍了Python3的unicode编码转换成中文的问题及解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 从别的地方搬过来的,担心以后不容易搜索到,就收集过来. 我当时面临的问题是要从C++发json代码出来,用python写了个server,然后返回给C++程序,结果收到的是: httpSvrDataCbUser: {"tranNO": "0808ad498670dc996", "d
-
python中ASCII码和字符的转换方法
将ASCII字符转换为对应的数值即'a'-->65,使用ord函数,ord('a') 反之,使用chr函数,将数值转换为对应的ASCII字符,chr(65) 可以同时使用这两个函数: 例1.大小写字母转换: str=input('输入大写字母:') chr(ord(str)+32)) #先将字符通过ord函数转换成ASCII码,然后+32从大写变成小写(小变大-32),再通过chr函数转换成字符 例2.字符型数字和int型数字转换: print( chr(ord('1')+3))#现将字符1转换
-
Python字符和字符值(ASCII或Unicode码值)转换方法
目的 将一个字符转化为相应的ASCII或Unicode码,或相反的操作. 方法 对于ASCII码(0~255范围) 复制代码 代码如下: >>> print ord('A') 65 >>> print chr(65) A 对于Unicode字符,注意仅接收长度为1的Unicode字符 复制代码 代码如下: >>> print ord(u'\u54c8') 21704 >>> print unichr(21704) 哈 >>
-
python实现unicode转中文及转换默认编码的方法
本文实例讲述了python实现unicode转中文及转换默认编码的方法.分享给大家供大家参考,具体如下: 一.在爬虫抓取网页信息时常需要将类似"\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8"转换为中文,实际上这是unicode的中文编码.可用以下方法转换: 1. >>> s = u'\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8' >>> print s 人生苦短,
-

Python之ascii转中文的实现
看代码吧~ name = r"\u6697\u88d4\u5251\u9b54" print(name.encode('ascii').decode('unicode_escape')) 或 print(name.encode().decode('unicode_escape')) 补充:python 汉字与ASCII互相转换 一.代码段 #python ASCII转汉字 name = r"\u5f20\u5357\u74dc" print(name.encode(
-
解决Linux系统中python matplotlib画图的中文显示问题
最近想学习一些python数据分析的内容,就弄了个爬虫爬取了一些数据,并打算用Anaconda一套的工具(pandas, numpy, scipy, matplotlib, jupyter)等进行一些初步的数据挖掘和分析. 在使用matplotlib画图时,横坐标为中文,但是画出的条形图横坐标总是显示"框框",就去查资料解决.感觉这应该是个比较常见的问题,网上的中文资料也确实很多,但是没有任何一个彻底解决了我遇到的问题.零零碎碎用了快3个小时的时间,才终于搞定.特此分享,希望能帮到有同
-
基于Linux系统中python matplotlib画图的中文显示问题的解决方法
最近想学习一些python数据分析的内容,就弄了个爬虫爬取了一些数据,并打算用Anaconda一套的工具(pandas, numpy, scipy, matplotlib, jupyter)等进行一些初步的数据挖掘和分析. 在使用matplotlib画图时,横坐标为中文,但是画出的条形图横坐标总是显示"框框",就去查资料解决.感觉这应该是个比较常见的问题,网上的中文资料也确实很多,但是没有任何一个彻底解决了我遇到的问题.零零碎碎用了快3个小时的时间,才终于搞定.特此分享,希望能帮到有同
-
Python实现针对含中文字符串的截取功能示例
本文实例讲述了Python实现针对含中文字符串的截取功能.分享给大家供大家参考,具体如下: 对于含多字节的字符串,进行截断的时候,要判断截断处是几字节字符,不能将多字节从中分割,避免截断后乱码 下面给出utf8和gb18030上的实现, 用任何一种都可以,可以先进行转码,用encode, decode; 方法1:对utf8: def subString(string,length): if length >= len(string): return string result = '' i =
-
Python实现简单截取中文字符串的方法
本文实例讲述了Python实现简单截取中文字符串的方法.分享给大家供大家参考.具体如下: web应用难免会截取字符串的需求,Python中截取英文很容易: >>> s = 'abce' >>> s[0:3] 'abc' 但是截取utf-8的中文机会截取一半导致一些不是乱码的乱码.其实utf8截取很简单,这里记下来作为备忘 #-*- coding:utf8 -*- s = u'中文截取' s.decode('utf8')[0:3].encode('utf8') # 结果u
-
Python实现matplotlib显示中文的方法详解
本文实例讲述了Python实现matplotlib显示中文的方法.分享给大家供大家参考,具体如下: [注意] 可能与本文主题无关,不过我还是想指出来:使用matplotlib库时,下面两种导入方式是等价的(我指的是等效,当然这个说法可以商榷:) import matplotlib.pyplot as plt import pylab as plt [效果图] [方式一]FontProperties import matplotlib.pyplot as plt from matplotlib.f
-
一条命令解决mac版本python IDLE不能输入中文问题
安装完Python通常自动就有了一个简易的集成环境IDLE,但在mac上,无法在IDLE中使用中文. 通常故障有两种情况: 1.在IDLE中,中文输入法根本无法工作,不会弹出输入框,所有的输入都被当做英文对待. 这种情况是由于IDLE使用了Tkinter 图形库,Tkinter使用的依赖库Tcl/Tk,在macOS中已经有了一个较低的内置版本,这造成了中文无法输入的问题,解决办法可以重新安装使用高版本Tcl/Tk编译的python,在Homebrew下只需要一条命令: brew reinstal
-
python 提取key 为中文的json 串方法
示例: # -*- coding:utf-8 -*- import json strtest = {"中故宫":"好地方","天涯":"北京"} print strtest #####{'\xe4\xb8\xad\xe6\x95\x85\xe5\xae\xab': '\xe5\xa5\xbd\xe5\x9c\xb0\xe6\x96\xb9', '\xe5\xa4\xa9\xe6\xb6\xaf': '\xe5\x8c\x97\