Python线性网络实现分类糖尿病病例
目录
- 1. 加载数据集
- 2. 搭建网络+优化器
- 3. 训练网络
- 4. 代码
1. 加载数据集
这次我们搭建一个小小的多层线性网络对糖尿病的病例进行分类
首先先导入需要的库文件

先来看看我们的数据集
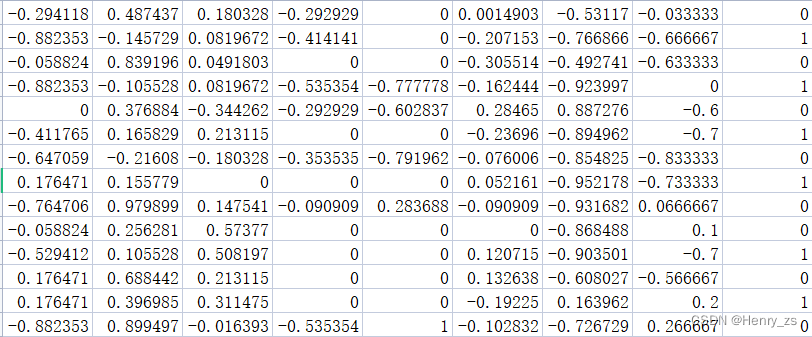
观察可以发现,前八列是我们的feature ,根据这八个特征可以判断出病人是否得了糖尿病。所以最后一列是1,0 的一个二分类问题
我们使用numpy 去导入数据集,delimiter 是定义分隔符,这里我们用逗号(,)分割

将前八列的特征放到我们的x_data里面,作为特征输入,最后一列放到y_data作为label
Tip :这里y_data 里面的 [-1] 中括号不可以省略,否则y_data会变成向量的形式
如果不习惯这种写法,可以用view改变一下形状就行
y_data = torch.from_numpy(xy[:,-1]).view(-1,1) #将y_data 的代码改成这样就可以了
下面是xy , x_data , y_data 打印出前两行的结果


2. 搭建网络+优化器
搭建网络的时候,要保证两层网络之间的维数能对应上
首先第一层的时候,因为前八列作为我们的x_data ,也就是说我们输入的特征是 8 维度的,那么由于 y = x * wT + b ,因为输入数据的x是(n * 8) 的,而我们定义的y维度是(n * 6) ,所以wT的维度应该是(8,6)
这里不需要知道啥时候转置,啥时候不转置之类的,只要满足线性的方程y = w*x+b,并且维度一致就行了。因为不管是转置,或者w和x谁在前,只是为了保证满足矩阵相乘而已
一个小的技巧就是:只需要看输入特征是多少,然后保证第一层第一个参数对应就行了,然后第一层第二个参数是想输出的维度。其次是第二层的第一个参数对应第一层第二个参数,以此类推....

我们采用的激活函数是ReLU , 由于是二元分类,最后一个网络的输出我们采用sigmoid输出
接下来,搭建实例化我们的网络,然后建立优化器
这里我们选择SGD随机梯度下降算法,学习率设置为0.01

3. 训练网络
训练网络的过程较为简单,大概的过程为
1. 计算预测值
2. 计算损失函数
3. 反向传播,之前要进行梯度清零
4. 梯度更新
5. 重复这个过程,epoch 为所有样本计算一次的周期,这次让epoch 迭代1000次
4. 代码
import torch.nn as nn # 神经网络库
import matplotlib.pyplot as plt # 绘图
import torch # 张量
from torch import optim # 优化器库
import numpy as np # 数据处理
xy = np.loadtxt('./diabetes.csv.gz',delimiter=',',dtype=np.float32) # 加载数据集
x_data = torch.from_numpy(xy[:,:-1]) # 所有行,除了最后一列的元素
y_data = torch.from_numpy(xy[:,-1]).view(-1,1) # -1也能拿出来是向量,但是[-1]会保证拿出来的是个矩阵
epoch_list =[]
loss_list = []
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = nn.Linear(8,6)
self.linear2 = nn.Linear(6,3)
self.linear3 = nn.Linear(3,1)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU()
def forward(self,x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(),lr =0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data) # 计算损失
if epoch % 100 ==0: # 每隔100次打印一下
print(epoch,loss.item())
#back propagation
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 梯度更新
epoch_list.append(epoch)
loss_list.append(loss.item())
plt.plot(epoch_list,loss_list)
plt.show()
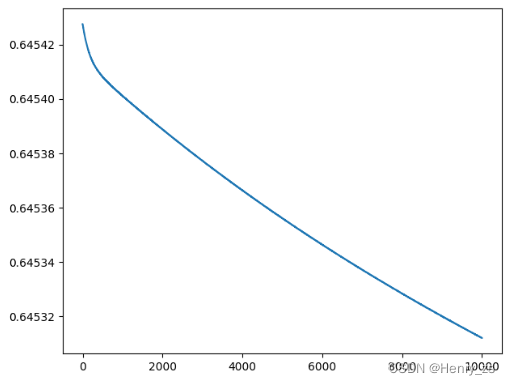
输出结果为:

到此这篇关于Python线性网络实现分类糖尿病病例的文章就介绍到这了,更多相关Python线性网络内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python构建简单线性回归模型
目录 线性回归模型 1.加载数据 2.划分训练集和测试集 3.训练模型 4.预测数据 5.画图展示线性拟合情况 6.预测数据测试 评估模型精度 1.计算回归模型精度 模型持久化 前言: 本文介绍如何构建简单线性回归模型及计算其准确率,最后介绍如何持久化模型. 线性回归模型 线性回归表示发现函数使用线性组合表示输入变量.简单线性回归很容易理解,使用了基本的回归技术,一旦理解了这些基本概念,可以更好地学习其他类型的回归模型. 回归用于发现输入变量和输出变量之间的关系,一般变量为实数.我们的目标是估计
-
Python线性表种的单链表详解
目录 1. 线性表简介 2. 数组 3. 单向链表 设计链表的实现 链表与顺序表的对比 1. 线性表简介 线性表是一种线性结构,它是由零个或多个数据元素构成的有限序列.线性表的特征是在一个序列中,除了头尾元素,每个元素都有且只有一个直接前驱,有且只有一个直接后继,而序列头元素没有直接前驱,序列尾元素没有直接后继. 数据结构中常见的线性结构有数组.单链表.双链表.循环链表等.线性表中的元素为某种相同的抽象数据类型.可以是C语言的内置类型或结构体,也可以是C++自定义类型. 2. 数组 数组在实际的
-
Python实现多元线性回归的梯度下降法
目录 1. 读取数据 2.定义代价函数 3. 梯度下降 4.可视化展示 1. 读取数据 首先要做的就是读取数据,请自行准备一组适合做多元回归的数据即可.这里以data.csv为例,这里做的是二元回归.导入相关库,及相关代码如下. import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D data = np.loadtxt("data.csv", delimiter
-
Python线性网络实现分类糖尿病病例
目录 1. 加载数据集 2. 搭建网络+优化器 3. 训练网络 4. 代码 1. 加载数据集 这次我们搭建一个小小的多层线性网络对糖尿病的病例进行分类 首先先导入需要的库文件 先来看看我们的数据集 观察可以发现,前八列是我们的feature ,根据这八个特征可以判断出病人是否得了糖尿病.所以最后一列是1,0 的一个二分类问题 我们使用numpy 去导入数据集,delimiter 是定义分隔符,这里我们用逗号(,)分割 将前八列的特征放到我们的x_data里面,作为特征输入,最后一列放到y_dat
-
关于python字符串方法分类详解
python字符串方法分类,字符串是经常可以看到的一个数据储存类型,我们要进行字符的数理,就需要用各种的方法,这里有许多方法,我给大家介绍比较常见的重要的方法,比如填充.删减.变形.分切.替代和查找. 打开sublime text 3编辑器,新建一个PY文件. test = "hey" test_new = test.center(10, "$") print(test_new) 填充类的有center()这个方法,可以指定字符,然后往两边填充,第一个参数是总的字符
-
原生python实现knn分类算法
一.题目要求 用原生Python实现knn分类算法. 二.题目分析 数据来源:鸢尾花数据集(见附录Iris.txt) 数据集包含150个数据集,分为3类,分别是:Iris Setosa(山鸢尾).Iris Versicolour(杂色鸢尾)和Iris Virginica(维吉尼亚鸢尾).每类有50个数据,每个数据包含四个属性,分别是:Sepal.Length(花萼长度).Sepal.Width(花萼宽度).Petal.Length(花瓣长度)和Petal.Width(花瓣宽度). 将得到的数据集
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
python实现二分类的卡方分箱示例
解决的问题: 1.实现了二分类的卡方分箱: 2.实现了最大分组限定停止条件,和最小阈值限定停止条件: 问题,还不太清楚,后续补充. 1.自由度k,如何来确定,卡方阈值的自由度为 分箱数-1,显著性水平可以取10%,5%或1% 算法扩展: 1.卡方分箱除了用阈值来做约束条件,还可以进一步的加入分箱数约束,以及最小箱占比,坏人率约束等. 2.需要实现更多分类的卡方分箱算法: 具体代码如下: # -*- coding: utf-8 -*- """ Created on Wed No
-
python实现logistic分类算法代码
最近在看吴恩达的机器学习课程,自己用python实现了其中的logistic算法,并用梯度下降获取最优值. logistic分类是一个二分类问题,而我们的线性回归函数 的取值在负无穷到正无穷之间,对于分类问题而言,我们希望假设函数的取值在0~1之间,因此logistic函数的假设函数需要改造一下 由上面的公式可以看出,0 < h(x) < 1,这样,我们可以以1/2为分界线 cost function可以这样定义 其中,m是样本的数量,初始时θ可以随机给定一个初始值,算出一个初始的J(θ)值,
-
python实现二分类和多分类的ROC曲线教程
基本概念 precision:预测为对的当中,原本为对的比例(越大越好,1为理想状态) recall:原本为对的当中,预测为对的比例(越大越好,1为理想状态) F-measure:F度量是对准确率和召回率做一个权衡(越大越好,1为理想状态,此时precision为1,recall为1) accuracy:预测对的(包括原本是对预测为对,原本是错的预测为错两种情形)占整个的比例(越大越好,1为理想状态) fp rate:原本是错的预测为对的比例(越小越好,0为理想状态) tp rate:原本是对的
-
python神经网络AlexNet分类模型训练猫狗数据集
目录 什么是AlexNet模型 训练前准备 1.数据集处理 2.创建Keras的AlexNet模型 开始训练 1.训练的主函数 2.Keras数据生成器 3.主训练函数全部代码 训练结果 最近在做实验室的工作,要用到分类模型,老板一星期催20次,我也是无语了,上有对策下有政策,在下先找个猫猫狗狗的数据集练练手,快乐极了 什么是AlexNet模型 AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的.也是在那年之后,更多的更深的神经网络
-
python实现决策树分类算法代码示例
目录 前置信息 1.决策树 2.样本数据 策树分类算法 1.构建数据集 2.数据集信息熵 3.信息增益 4.构造决策树 5.实例化构造决策树 6.测试样本分类 后置信息:绘制决策树代码 总结 前置信息 1.决策树 决策树是一种十分常用的分类算法,属于监督学习:也就是给出一批样本,每个样本都有一组属性和一个分类结果.算法通过学习这些样本,得到一个决策树,这个决策树能够对新的数据给出合适的分类 2.样本数据 假设现有用户14名,其个人属性及是否购买某一产品的数据如下: 编号 年龄 收入范围 工作性质
-
使用Python处理KNN分类算法的实现代码
目录 KNN分类算法的介绍 测试数据 Python代码实现 结果分析 简介: 我们在这世上,选择什么就成为什么,人生的丰富多彩,得靠自己成就.你此刻的付出,决定了你未来成为什么样的人,当你改变不了世界,你还可以改变自己. KNN分类算法的介绍 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本“距离”最近的前K个样本