anaconda python3.8安装后降级
前言
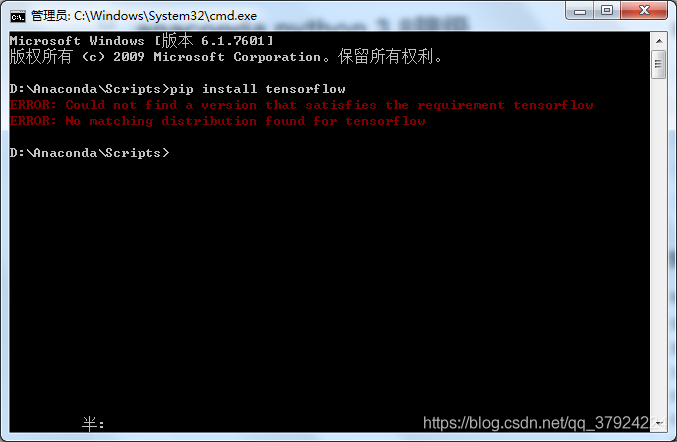
给新的环境安装pip install tensorflow,结果报错了。
跟着我分析解决一波。
报错原因
这个红字已经说的很清楚了。
ERROR: Could not find a version that satisfies the requirement tensorflow。
高情商:没有找到适合你目前的版本
低情商:你版本不对
于是,我看了下自己的python版本
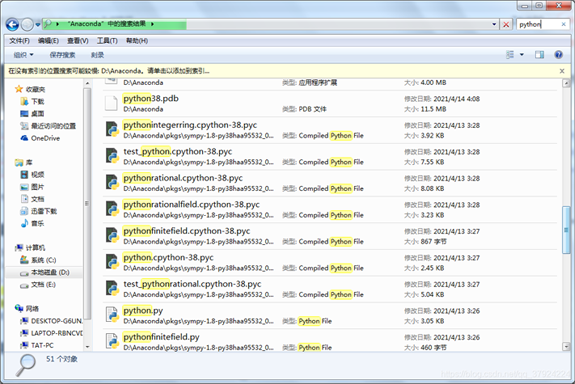
版本居然是3.8,而不是3.7。。。。
没法太新了,退回去吧
解决方法
在开始菜单里找到anaconda的文件夹,点击“Anaconda Promt”
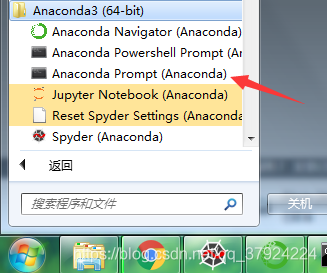
弹出了一个小黑框
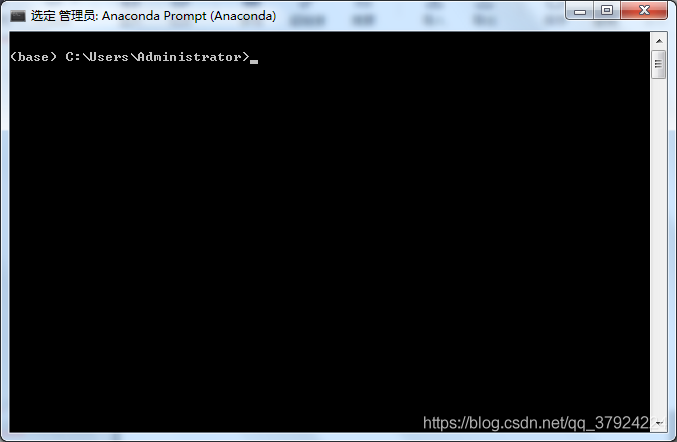
输入“conda install python=3.7”,回车
(将近10分钟的等待)
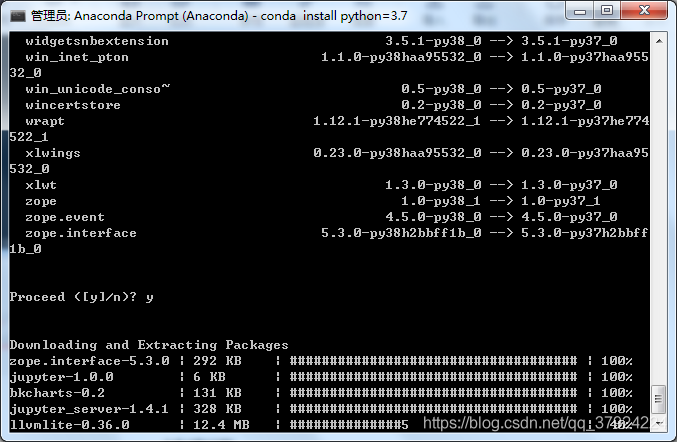
然后输入“y”
接着大概等了30分钟(漫长。。。)
等出现done。。。说明就好了
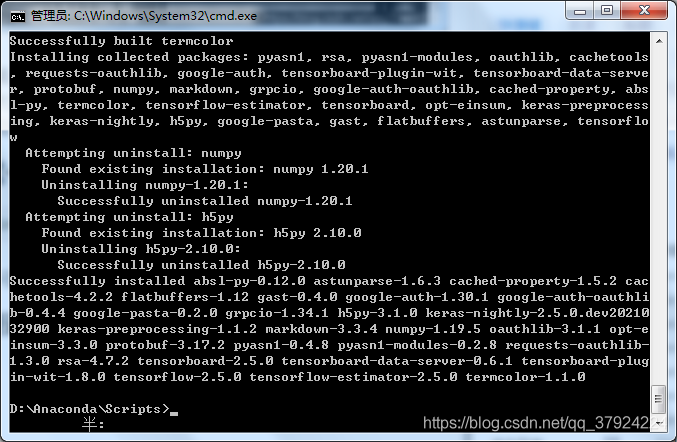
测试一下
pip install tensorflow
没得问题
结束语
到此这篇关于anaconda python3.8安装后降级的文章就介绍到这了,更多相关anaconda python3.8降级 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解python 降级到3.6终极解决方案
最近因为要安装Tensorflow,然后发现tensorflow居然不支持python3.7,于是怒而将其降级到3.6 以下是具体命令,mark一下 1.移除现有Python brew unlink python 2.安装3.6.5 brew install https://raw.githubusercontent.com/Homebrew/homebrew-core/f2a764ef944b1080be64bd88dca9a1d80130c558/Formula/python.rb 或者co
-

anaconda python3.8安装后降级
前言 给新的环境安装pip install tensorflow,结果报错了. 跟着我分析解决一波. 报错原因 这个红字已经说的很清楚了. ERROR: Could not find a version that satisfies the requirement tensorflow. 高情商:没有找到适合你目前的版本 低情商:你版本不对 于是,我看了下自己的python版本 版本居然是3.8,而不是3.7.... 没法太新了,退回去吧 解决方法 在开始菜单里找到anaconda的文件夹,点击
-
解决win7操作系统Python3.7.1安装后启动提示缺少.dll文件问题
错误提示图片 首先,我的操作系统是win7旗舰版,安装Python3.7.1之后启动时,提示如图错误,网上比较多的是两种处理方法: (1)安装Windows补丁程序 (2)安装VC redit.exe 第一种方案我这边下载了KB3118401.KB2999226,但是双击安装的时候安装不了:第二种方案大家都推荐的是安装v++2015,也安装成功了,但是安装后仍然报错. 然后看着网上的推荐时间都比较早,我这边考虑是不是安装2017版本的会解决问题,因为2017除了兼容2015之外还有其他的一些东西
-
安装python3.7编译器后如何正确安装opnecv的方法详解
1.测试python是否安装成功 在cmd界面中输入如下命令,如图所示: 一个是python命令 另一个是pip命令 记住不要在python环境下输入pip命令,否则出现如下情况,以免对后续安装opencv走弯路. 2.改变镜像源 如上述图所示,我所执行命令是在C:\Users\Administrator这个位置下进行的,于是我在C:\Users\Administrator\pip这个文件夹下新建一个pip.ini文件,在里面插入[global] index-url = https://pypi
-
Windows10下 python3.7 安装 facenet的教程
前提 1.python环境及tensorflow安装成功 2.Anaconda安装好 ,Anaconda安装步骤 安装步骤 1.下载facenet,https://github.com/davidsandberg/facenet.git 2.下载好后解压安装包. 3.在自己电脑对应的Anaconda3\Lib\site-packages目录下,新建facenet文件夹 4.将下载的facenet文件夹下的src文件夹下的所有文件拷贝到新建的文件夹中. 5.最后,在Anaconda Prompt内
-
python3 mmh3安装及使用方法
mmh3安装方法 哈希方法主要有MD.SHA.Murmur.CityHash.MAC等几种方法.mmh3全程murmurhash3,是一种非加密的哈希算法,常用于hadoop等分布式存储情境中,在anaconda中安装使用命令 pip install mmh3 问题1 报错如下: Microsoft Visual C++ 14.0 is required 显示缺少C++ 14的库文件,选择登录网站 https://visualstudio.microsoft.com/downloads/ 下载
-
Window10+Python3.5安装opencv的教程推荐
1.确定Python版本,电脑64位或者32位 打开cmd(window键+R,输入cmd就出现),在命令行输入:打开cmd(window键+R,输入cmd就出现),在命令行输入:python Python 3.5.2 |Anaconda 4.2.0 (64-bit)| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", &quo
-
win7下 python3.6 安装opencv 和 opencv-contrib-python解决 cv2.xfeatures2d.SIFT_create() 的问题
1.Anaconda 安装python3.6 conda create -n match python=3.6 Python版本默认安装是 3.6.9 2.安装opencv 执行完毕后,安装opencv-python pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple some-package opencv-python 的版本为4.1.1.26 3.安装opencv-contrib-python pip i
-
Python和Anaconda和Pycharm安装教程图文详解
Anaconda 是一个基于 Python 的数据处理和科学计算平台,它已经内置了许多非常有用的第三方库,装上Anaconda,就相当于把 Python 和一些如 Numpy.Pandas.Scrip.Matplotlib 等常用的库自动安装好了,使得安装比常规 Python 安装要容易.如果选择安装Python的话,那么还需要 pip install 一个一个安装各种库,安装起来比较痛苦,还需要考虑兼容性,非如此的话,就要去Python官网(https://www.python.org/dow
-
win10下Python3.6安装、配置以及pip安装包教程
0.目录 1.前言 2.安装python 3.使用pip下载.安装包 3.1 安装Scrapy 3.2 安装PyQt 3.3 同时安装多个包 3.4 pip的常用命令 1.前言 之前在电脑上安装了python3.6.2(目前是最新版),可以看到,是2017-07-17才出的.因此,我发现有三个重要的包:Scrapy.PyQt和TensorFlow都还没有适配python3.6.2版本.无奈之下,只能卸载python3.6.2,安装稍微老一点的python3.6.1.另附Windows下pytho
-
Python3.6安装及引入Requests库的实现方法
本博客可能没有那么规范,环境之类的配置.只是让你直接开始编程写python. 至于各种配置网络上有多种方法. 本文仅代表我的观点的一种方法. 电脑环境:win10 64位 第一步:下载python. 网址:https://www.python.org/downloads/windows/ 点击并打开,我下载的是最新Python3.6.0版本. 打开后界面如下,根据你的电脑和你的条件选择你需要的版本. x86适合32位操作系统:x86-64适合64位操作系统. web-based installe