十分钟上手正则表达式 下篇
目录
- 一、正则表达式常用符号
- 1.1 问号【?】
- 1.2 加号【+】
- 1.3 花括号{}
- 1.4 管道符号【|】
- 1.5 小括号()
- 二、正则表达式实战示例
- 示例1:
- 示例2:

前面,我们就正则表达式一些常用的基本方法做了详细的介绍,本篇会讲解一些拓展性的知识,主要的就是常见的ERE模式符号以及shell脚本中常见的一些正则表达式例子。
快速学习正则表达式,不用死记硬背,示例让你通透(上篇)
一、正则表达式常用符号
本章示例着重于在gawk程序脚本中的较常见的ERE模式符号。
1.1 问号【?】
问号类似于星号,不过有点细微的不同。问号表明前面的字符可以出现 0 次或 1 次,但只限于 此。它不会匹配多次出现的字符。 示例展示:

脚本解说:
如果字符 e 并未在文本中出现,或者它只在文本中出现了 1 次,那么模式会匹配。
和星号一样,可以将问号和字符组一起使用。
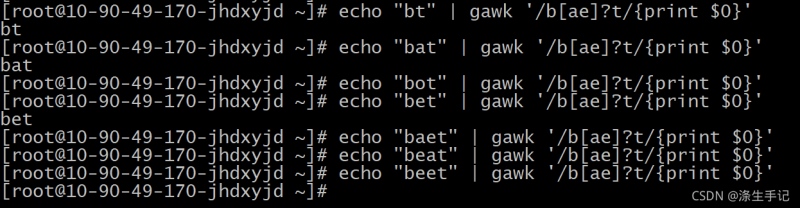
脚本解说:
如果字符组中的字符出现了 0 次或 1 次,模式匹配就成立。但如果两个字符都出现了,或者其中一个字符出现了2 次,模式匹配就不成立。
1.2 加号【+】
加号是类似于星号的另一个模式符号,但跟问号也有不同。加号表明前面的字符可以出现 1次或多次,但必须至少出现1 次。如果该字符没有出现,那么模式就不会匹配。

示例解说:
如果字符 e 没有出现,模式匹配就不成立。加号同样适用于字符组,与星号和问号的使用方式相同。
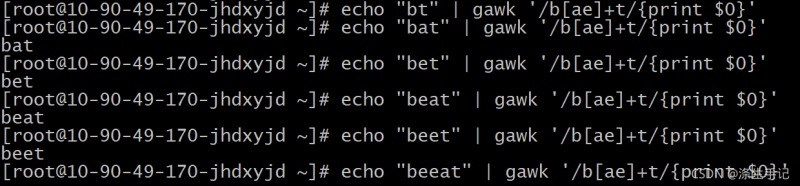
脚本解读:
如果字符组中定义的任一字符出现了,文本就会匹配指定的模式。
1.3 花括号{}
ERE 中的花括号允许为可重复的正则表达式指定一个上限。这通常称为 间隔 ( interval )。 可以用两种格式来指定区间。
- m:正则表达式准确出现m次。
- m, n:正则表达式至少出现m次,至多n次。
这个特性可以精确调整字符或字符集在模式中具体出现的次数。
重点说明:
默认情况下, gawk 程序不会识别正则表达式间隔。必须指定 gawk 程序的 --re- interval 命令行选项才能识别正则表达式间隔。
示例:

示例解读:
通过指定间隔为 1 ,限定了该字符在匹配模式的字符串中出现的次数。如果该字符出现多次, 模式匹配就不成立。
同样也可以指定上限和下限

示例解读:
字符 e 可以出现 1 次或 2 次,这样模式就能匹配;否则,模式无法匹配。
下面是字符组的示例:
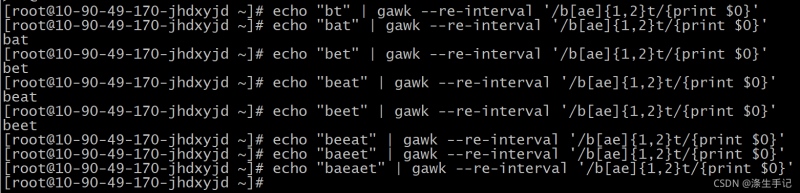
示例解读:
如果字母 a 或 e 在文本模式中只出现了 1~2 次,则正则表达式模式匹配;否则,模式匹配失败。
1.4 管道符号【|】
管道符号允许在检查数据流时,用逻辑 OR 方式指定正则表达式引擎要用的两个或多个模式。如果任何一个模式匹配了数据流文本,文本就通过测试。如果没有模式匹配,则数据流文本匹配失败。
使用格式:
expr1 |expr2|...
示例:

示例解读:
这个例子会在数据流中查找正则表达式 cat 或 dog 。正则表达式和管道符号之间不能有空格, 否则它们也会被认为是正则表达式模式的一部分。
管道符号两侧的正则表达式可以采用任何正则表达式模式(包括字符组)来定义文本。看下面示例:

示例解读:
这个例子会匹配数据流文本中的 cat 、 hat 或 dog 。
1.5 小括号()
正则表达式模式也可以用圆括号进行分组。当将正则表达式模式分组时,该组会被视为一个标准字符。可以像对普通字符一样给该组使用特殊字符。
示例:

示例解读:
结尾的 urday 分组以及问号,使得模式能够匹配完整的 Saturday 或缩写 Sat 。
将分组和管道符号一起使用来创建可能的模式匹配组是很常见的做法。如下示例:
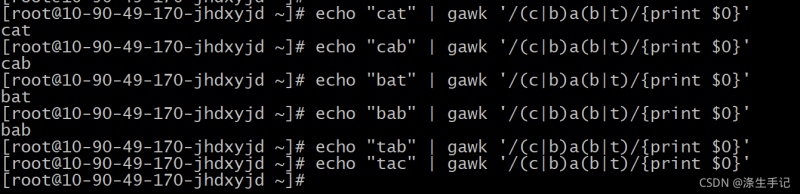
示例解读:
模式 (c|b)a(b|t) 会匹配第一组中字母的任意组合以及第二组中字母的任意组合。
二、正则表达式实战示例
示例1:
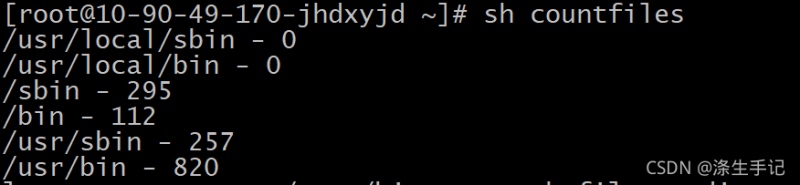
下面会有一个脚本,功能是对PATH环境变量中定义的目录里的可执行文件进行计数。
脚本内容如下:
#!/bin/bash # count number of files in your PATH mypath=$(echo $PATH | sed 's/:/ /g') #用空格来替换冒号,分割路径 count=0 for directory in $mypath do check=$(ls $directory) for item in $check do count=$[ $count + 1 ] done echo "$directory - $count" count=0 done
执行结果:
示例2:
正则表达式解析邮件地址
邮件地址的基本格式为:username@hostname
username值可用字母数字字符以及以下特殊字符:(点号、单破折线、 加号、 下划线)
在有效的邮件用户名中,这些字符可能以任意组合形式出现。邮件地址的hostname部分由一个或多个域名和一个服务器名组成。服务器名和域名也必须遵照严格的命名规则,只允许字母数字字符以及以下特殊字符:(点号、下划线)
服务器名和域名都用点分隔,先指定服务器名,紧接着指定子域名,最后是后面不带点号的
顶级域名。
顶级域名的数量在过去十分有限,正则表达式模式编写者会尝试将它们都加到验证模式中。
然而遗憾的是,随着互联网的发展,可用的顶级域名也增多了。这种方法已经不再可行。
从左侧开始构建这个正则表达式模式。
过滤用户名中表达式模式。
^([a-zA-Z0-9_\-\.\+]+)@
这个分组指定了用户名中允许的字符,加号表明必须有至少一个字符。下一个字符很明显是@。
hostname模式使用同样的方法来匹配服务器名和子域名:
([a-zA-Z0-9_\-\.]+)
顶级域名用的正则表达式模式:
\.([a-zA-Z]{2,5})$
整体组合模式:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$
封装到脚本中:
cat isemail.sh
#!/bin/bash
# script to filter out bad phone numbers
awk --re-interval '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})/{print $0}'
注意:在awk程序中使用正则表达式间隔时,必须使用--re-interval命令行选项。
示例测试脚本:
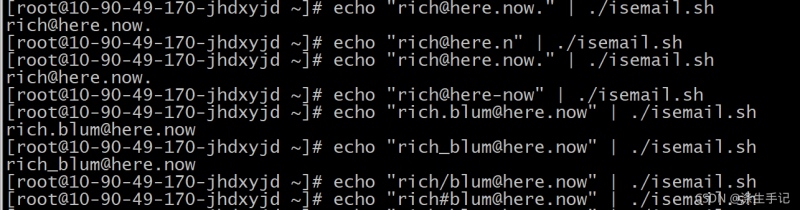
示例解读:
符合规则的邮件名会打印在屏幕,不符合的会被过滤掉,不会有内容输出。
到此这篇关于十分钟上手正则表达式 下篇的文章就介绍到这了,更多相关正则表达式 入门内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

正则表达式分组与引用的使用
目录 0.写在前面 1.分组与编号 2.不保存子组 3.分组引用 4.查找与替换 查找 替换 5.在文本编辑器中使用 查找 替换 6.写在最后 0.写在前面 今天我们来讲下正则中的分组与引用,其实在第一篇文章中,我们在实战环节就已经用到分组这个功能了,回顾下 IPv4 地址的正则表达式: 复制代码 代码如下: ^([1-9][0-9]?|1[0-9][0-9]|2[0-4][0-9]|25[0-5])(\.(0|[1-9][0-9]?|1[0-9][0-9]|2[0-4][0-9]|25[0-5
-
正则表达式常见的4种匹配模式小结
目录 0.写在前面 1.不区分大小写模式 2.点号通配模式 3.多行匹配模式 4.注释模式 5.写在最后 0.写在前面 今天一起来学习下正则中的匹配模式,所谓的匹配模式,就是指正则中的一些 改变元字符匹配行为 的方式,比如匹配时不区分英文字母的大小写. 还记得我们在第二篇文章中学过的贪婪模式.非贪婪模式和独占模式吗,这些模式会改变正则中量词的匹配行为,今天来看一些和量词无关的匹配模式,一共有4种,分别是不区分大小写模式.点号通配模式.多行匹配模式.注释模式. 1.不区分大小写模式 顾名思义,不区
-
正则表达式那些让人头晕的元字符
目录 0.写在前面 1.特殊单字符 2.空白符 3.范围 4.量词 5.实战 1.如何表达一个两位数字的范围 2.如何表达一个三位数字的范围 3.组合 6.写在最后 0.写在前面 在开发中,正则表达式常用于邮箱.手机号的校验,文本的批量查找.替换等操作. 大部分同学,在拿到需求的时候,第一件事一定是打开浏览器,搜索:邮箱 正则表达式 怎么写,然后Ctrl C + V,测试几个条件没问题,就提交了,出了问题也不知道怎么修改,只能再求救热心网友. 本篇文章,主要带大家了解一下,正则表达式的基本用法,
-
十分钟上手正则表达式 上篇
目录 一.正则表达式的定义: 二.正则表达式的类型 三.定义 BRE 模式 3.1 纯文本 3.2 特殊字符 3.3 锚字符 3.3.1 锁定在行首 3.3.2 锁定在行尾 3.3.3 组合锚点 3.4 点号字符 3.5 字符组 3.6 排除型字符组 3.7 区间 3.8 特殊的字符组 3.9 星号[*] 一.正则表达式的定义: 正则表达式是你所定义的 模式模板 ( pattern template ), Linux 工具可以用它来过滤文本. Linux工具(比如sed 编辑器或 gawk 程序
-
正则表达式之分组的回溯引用问题
正则表达式简介 正则表达式,又称规则表达式.(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念.正则表达式通常被用来检索.替换那些符合某个模式(规则)的文本. 许多程序设计语言都支持利用正则表达式进行字符串操作.例如,在Perl中就内建了一个功能强大的正则表达式引擎.正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的.正则表达式通常缩写成"regex",单数有regexp.regex,复数有r
-
正则表达式量词与贪婪的使用详解
目录 0.写在前面 1.量词 2.贪婪模式前传 2.1 使用 a+ 进行匹配 2.2 使用 a* 进行匹配 3.贪婪模式 4.非贪婪模式 5.独占模式 5.1 贪婪匹配过程 5.2 非贪婪匹配过程 5.3 独占匹配过程 6.写在最后 0.写在前面 在上一篇文章中,我们学习了正则的一些基础元字符,相信大家都已经忘却的差不多了,可以点击上面的链接再温习下. 今天我们一起来学习下正则中量词的三种匹配模式,贪婪模式.非贪婪模式.独占模式,这些模式会改变正则中量词的匹配行为,是每次贪婪的匹配到更多呢,还是
-
十分钟上手正则表达式 下篇
目录 一.正则表达式常用符号 1.1 问号[?] 1.2 加号[+] 1.3 花括号{} 1.4 管道符号[|] 1.5 小括号() 二.正则表达式实战示例 示例1: 示例2: 前面,我们就正则表达式一些常用的基本方法做了详细的介绍,本篇会讲解一些拓展性的知识,主要的就是常见的ERE模式符号以及shell脚本中常见的一些正则表达式例子. 快速学习正则表达式,不用死记硬背,示例让你通透(上篇) 一.正则表达式常用符号 本章示例着重于在gawk程序脚本中的较常见的ERE模式符号. 1.1 问号[?]
-
Java十分钟入门多线程下篇
目录 1.线程池: 2.创建线程池: 1.newCacheThreadPool: 2.newSingleThreadExecutor: 3.newFixedThreadPool(inta): 4.newScheduledTreadPool: 3.线程池创建自定义线程: 4.Runnable和Callable的区别: 5.线程池总结: 1.线程池: 什么是线程池? 咱们也不看长篇大论,通俗的来讲,线程池就是装线程的容器,当需要用的时候去池里面取出来,不用的时候放回去或者销毁.这样一个线程就可以反复
-
十分钟带你快速上手Vue3过渡动画
目录 写在前面 Vue的transition组件 过渡demo class的命名规则 使用animation 过渡模式 appear属性 animate.css库的使用 使用动画序列 使用自定义过渡class 写在最后 写在前面 在实际开发中,为了增加用户体验,经常会使用到过渡动画,而过渡动画在CSS中是通过transition和animation实现的.而在Vue中,Vue本身中内置了一些组件和API可以帮助我们方便的实现过渡动画效果:接下来我们就学习一下. Vue的transition组件
-
Java十分钟精通集合的使用与原理下篇
List集合: ArrayList: 底层是数组结构,储存有序并且可以重复的对象 package SetTest; import java.util.ArrayList; import java.util.Collections; import java.util.List; public class ArrayListTest { public static void main(String[] args) { //创建ArrayList的对象 List<Integer> list = ne
-
Spring Security十分钟入门教程
目录 写在前面 目标 开始 不引入Spring Security访问接口 引入Spring Security访问接口 退出登录 后记 写在前面 我们在学习技术的过程中,学习的渠道大概有以下几种:看书,视频,博客.我们会发现,一种技术开始流行的时候,各种形式的讲述也就出现了.那么,出书,录视频,写博客的人,在他们之前,是没有什么现成的东西让他们学习的,他们是怎么上手的呢?换句话说,怎么才能有效的快速的上手一门技术呢? 这篇文章,我们一起从零开始学习SpringSecurity,技术点不重要,重要的
-
Python编程django实现同一个ip十分钟内只能注册一次
很多小伙伴都会有这样的问题,说一个ip地址十分钟内之内注册一次,用来防止用户来重复注册带来不必要的麻烦 逻辑: 取ip,在数据库找ip是否存在,存在判断当前时间和ip上次访问时间之差,小于600不能注册,到登录界面,大于600可以注册,设计一个数据库来存储这个ip地址和访问时间, class Ip(models.Model): ip=models.CharField(max_length=20) time=models.DateTimeField() class Meta: verbose_na
-
django实现登录时候输入密码错误5次锁定用户十分钟
在学习django的时候,想要实现登录失败后,进行用户锁定,切记录锁定时间,在网上找了很多资料,但是都感觉不是那么靠谱,于是乎,我开始了我的设计,其实我一开始想要借助redis呢,但是想要先开发一个简单的,后续在拆分后,然后在去进行拆分, 这样也是很接近我们在真实的开发中所遇到问题. 我的思路是: 输入账号密码>是否已经登录>提示已经登录 输入账号密码>错误次数少于6次>校验密码>登录成功,记录登录时间,错误次数清空,记录登录状态 输入账号密码>错误大于六次>提示
-
django实现同一个ip十分钟内只能注册一次的实例
很多小伙伴都会有这样的问题,说一个ip地址十分钟内之内注册一次,用来防止用户来重复注册带来不必要的麻烦 逻辑: 取ip,在数据库找ip是否存在,存在判断当前时间和ip上次访问时间之差,小于600不能注册,到登录界面,大于600可以注册, 设计一个数据库来存储这个ip地址和访问时间, class Ip(models.Model): ip=models.CharField(max_length=20) time=models.DateTimeField() class Meta: verbose_n
-
javascript 小时:分钟的正则表达式
复制代码 代码如下: /** * 小时:分钟的正则表达式检查<br> * <br> * @param pInput 要检查的字符串 * @return boolean 返回检查结果 */ public static boolean isUrl (String pInput) { if(pInput == null){ return false; } String regEx = " ^([0-1]{1}\d|2[0-3]):([0-5]\d)$"; Patter