使用selenium模拟动态登录百度页面的实现
目标:模拟手动登录百度页面的过程,打开chrome浏览器,输入百度网址,进入百度网页,点击登录,输入账号和密码,进入登录页面。
代码演示过程:
from selenium import webdriver import time # 1.打开浏览器 driver = webdriver.Chrome() # 2.设置地址 url = "https://www.baidu.com/" # 3.访问网址 driver.get(url)
访问到百度页面后,需要模拟点击“登录”按钮。找到“登录”按钮的元素如下所示:

根据id = ‘u1’和class=’lb’找到“登录”按钮
# 4.分析网页,找到登录元素
# login = driver.find_elements_by_id('u1').find_elements_by_class_name('lb')[0] #方法一
#
login = driver.find_elements_by_css_selector('div[id=u1] a[class=lb]')[0] #方法二
#5.点击登录按钮
login.click()
*注意点击登录按钮以后,要稍微等待一会。 点击登录以后,界面如下:
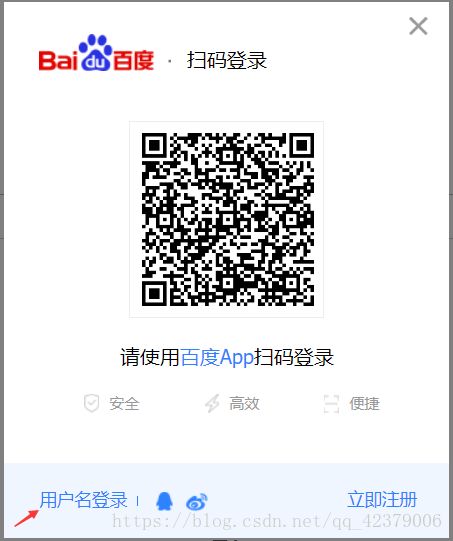
接下来需要模拟点击“用户名登录”按钮,找到“用户名登录”按钮的元素如下所示:

根据p标签下的class=”tang-pass-footerBarULogin pass-link”找到用户名登录,注意这个class里有两个同级类名,中间有个空格,在css选择器里写的时候就只需要写一个类名就行,否则中间有空格,如果写成’p.tang-pass-footerBarULogin pass-link’,就表示p标签下的类名为tang-pass-footerBarULogin的下一个类名为pass-link的类。
#点击之后要加等待时间
time.sleep(2)
#6.找到登录界面的 用户名登录
#选择p标签下的class,<p class="tang-pass-footerBarULogin pass-link">
usernamelogin = driver.find_elements_by_css_selector('p.tang-pass-footerBarULogin')[0]
#7.点击它,进入账号密码输入界面
usernamelogin.click()
点击“用户名登录”后,进入输入账号和密码界面。 找到账号输入框的元素如下所示:

找到密码输入框的元素如下所示:

找到登录输入框的元素如下所示:

#点击之后要加等待时间
time.sleep(2)
#8.找到 输入 用户名 和密码框,并且设置内容
#<input id="TANGRAM__PSP_10__userName">
username = driver.find_element_by_id('TANGRAM__PSP_10__userName')
#输入账号名
username.send_keys('xxxxx')
time.sleep(1)
#<input id="TANGRAM__PSP_10__password">
password = driver.find_element_by_id('TANGRAM__PSP_10__password')
#输入密码
password.send_keys('xxxxxx')
time.sleep(1)
#<input id="TANGRAM__PSP_10__submit">
submit = driver.find_element_by_id('TANGRAM__PSP_10__submit')
submit.click()
到此这篇关于使用selenium模拟动态登录百度页面的实现的文章就介绍到这了,更多相关selenium模拟动态登录百度页面内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何使用selenium和requests组合实现登录页面
这篇文章主要介绍了如何使用selenium和requests组合实现登录页面,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.在这里selenium的作用 (1)模拟的登录. (2)获取登录成功之后的cookies 代码 def start_login(self): chrome_options = Options() # 禁止图片加载,禁止推送通知 prefs = { "profile.default_content_setting_val
-
Selenium 模拟浏览器动态加载页面的实现方法
相信爬取大公司的数据时,常常会遇到页面信息动态加载的问题, 如果仅仅使用content = urllib2.urlopen(URL).read(),估计信息是获取不全的,这时候就需要模拟浏览器加载页面的过程, selenium提供了方便的方法,我也是菜鸟,试了很多种方式,下面提供觉得最靠谱的(已经证明对于爬取新浪微博的topic.twitter under topic完全没问题). 至于下面的browser变量是什么,看前面的几篇文章. 首先是请求对应的URL: right_URL = URL.
-
使用selenium模拟登录解决滑块验证问题的实现
本次主要是使用selenium模拟登录网页端的TX新闻,本来最开始是模拟请求的,但是某一天突然发现,部分账号需要经过滑块验证才能正常登录,如果还是模拟请求,需要的参数太多了,找的心累.不过好在TX的滑块验证是他们自己开发的,没有极验那么复杂,当然相反的,想要模拟就得自己去一点点探索了,毕竟对极验滑块的破解,网上已经可以找到现成的代码来用了.下面说一下模拟的实现过程和我遇见的问题. 1.登录入口 我是通过点击打开链接来当做登录入口的 部分代码实现: driver = webdriver.Chrom
-
python3.7+selenium模拟淘宝登录功能的实现
在使用selenium去获取淘宝商品信息时会遇到登录界面 这个登录界面处理的难度在于滑动验证的实现,有的人使用微博登录,避免了滑动验证,那可不可以使用密码登录呢?答案是可以的 实现思路 首先导入需要的库 from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.web
-
scrapy结合selenium解析动态页面的实现
1. 问题 虽然scrapy能够完美且快速的抓取静态页面,但是在现实中,目前绝大多数网站的页面都是动态页面,动态页面中的部分内容是浏览器运行页面中的JavaScript脚本动态生成的,爬取相对困难: 比如你信心满满的写好了一个爬虫,写好了目标内容的选择器,一跑起来发现根本找不到这个元素,当时肯定一万个黑人问号 于是你在浏览器里打开F12,一顿操作,发现原来这你妹的是ajax加载的,不然就是硬编码在js代码里的,blabla的- 然后你得去调ajax的接口,然后解析json啊,转成python字
-

Python编程使用Selenium模拟淘宝登录实现过程
目录 一.利用xpath进行(全程使用) 二.代码部分与图片内容 一.利用xpath进行(全程使用) driver.find_element_by_xpath() 二.代码部分与图片内容 打开淘宝网站,点击登录,输入账号密码,进入网站,搜索框中输入电脑,然后点击搜索 #导入selenium from selenium import webdriver #导入等待时间 import time #使用火狐浏览器进行访问 driver = webdriver.Firefox() #访问淘宝网站 dri
-
C#使用ImitateLogin模拟登录百度
在之前的文章中,我已经介绍过一个社交网站模拟登录的类库:imitate-login ,这是一个通过c#的HttpWebRequest来模拟网站登录的库,之前实现了微博网页版和微博Wap版:现在,模拟百度登录的部分也已经完成.由于个人时间的限制,加上目前有多个项目在同时进行,因此更新频率会根据项目关注度来决定(Star & fork). 这个类库的使用方法非常简单,仅对外提供一个方法: LoginResult Login(1: string userName, 2: string password
-
Python如何基于selenium实现自动登录博客园
这篇文章主要介绍了Python如何基于selenium实现自动登录博客园,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 需要做的准备: 本文章是使用Chrome,所以需要Chormedriver.exe,具体的下载过程可以百度查到 Selenium是一种自动化测试工具,能模拟浏览器的行为,所以今天我就模拟一下浏览器登陆博客园的行为. 首先,分析问题,登陆博客园需要做些什么: 1.打开浏览器 2.输入博客园主页的网址 3.点击登陆按钮,等待页面跳
-
Python 基于Selenium实现动态网页信息的爬取
目录 一.Selenium介绍与配置 1.Selenium简介 2. Selenium+Python环境配置 二.网页自动化测试 1.启动浏览器并打开百度搜索 2.定位元素 三.爬取动态网页的名人名言 1. 网页数据分析 2. 翻页分析 3.爬取数据的存储 4. 爬取数据 四.爬取京东网站书籍信息 五.总结 一.Selenium介绍与配置 1.Selenium简介 Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具.Selenium测试直接运行在浏览器中,可以
-
浅谈python爬虫使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动态加载的图片该怎么爬取到. 分析 他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来. headers = { 'User-Agent':'Mozilla/5.0 (Win
-
Python+Selenium使用Page Object实现页面自动化测试
Page Object模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class,其中包含页面中需要测试的元素(按钮,输入框,标题 等),这样在Selenium测试页面中可以通过调用页面类来获取页面元素,这样巧妙的避免了当页面元素id或者位置变化时,需要改测试页面代码的情况. 当页面元素id变化时,只需要更改测试页Class中页面的属性即可. Page Object模式是一种自动化测试设计模式,将页面定位和业务操作分开,分离测试对象(元素对象)和测试脚本(用例脚本),提高