利用Python实现岗位的分析报告
目录
- 前言
- 一、本文目标
- 二、分析结果
- 1.引入库
- 2.页面结构
- 3.请求参数
- 4.构造请求 解析数据
- 4.获取所有数据
- 总结
前言
前两篇我们分别爬取了糗事百科和妹子图网站,学习了 Requests, Beautiful Soup 的基本使用。不过前两篇都是从静态 HTML 页面中来筛选出我们需要的信息。这一篇我们来学习下如何来获取 Ajax 请求返回的结果。
本篇以拉勾网为例来说明一下如何获取 Ajax 请求内容
一、本文目标
获取 Ajax 请求,解析 JSON 中所需字段
数据保存到 Excel 中
数据保存到 MySQL, 方便分析
二、分析结果
1.引入库
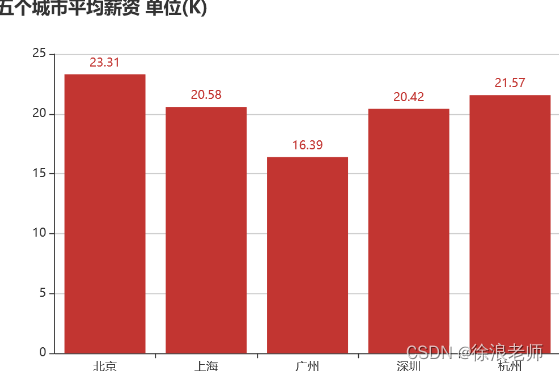
五个城市 Python 岗位平均薪资水平
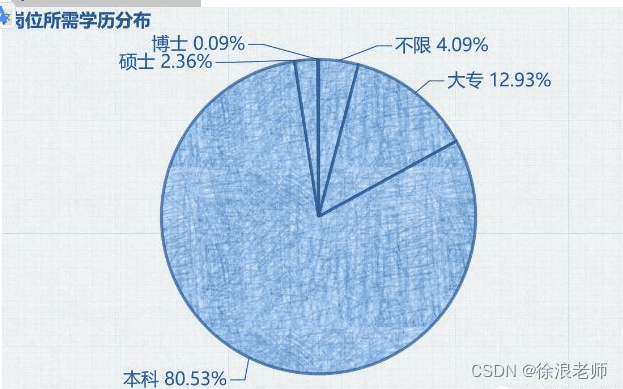
Python 岗位要求学历分布
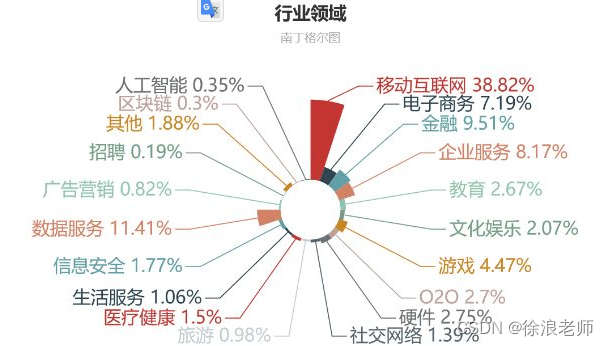
Python 行业领域分布
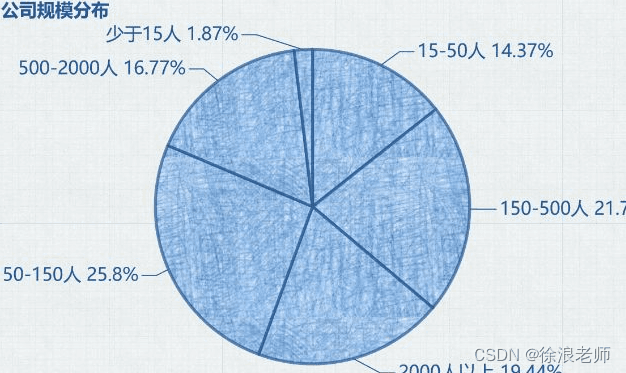
Python 公司规模分布:
2.页面结构
我们输入查询条件以 Python 为例,其他条件默认不选,点击查询,就能看到所有 Python 的岗位了,然后我们打开控制台,点击网络标签可以看到如下请求:
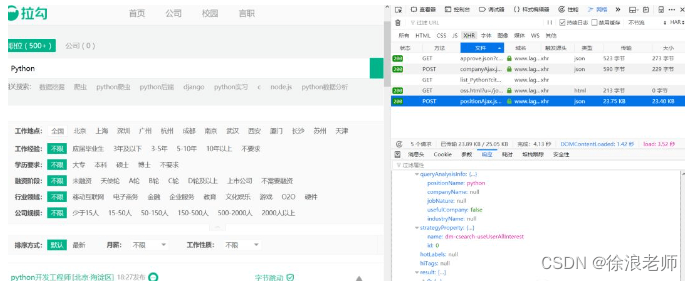
从响应结果来看,这个请求正是我们需要的内容。后面我们直接请求这个地址就好了。从图中可以看出 result 下面就是各个岗位信息。
到这里我们知道了从哪里请求数据,从哪里获取结果。但是 result 列表中只有第一页 15 条数据,其他页面数据怎么获取呢?
3.请求参数
我们点击参数选项卡,如下:
发现提交了三个表单数据,很明显看出来 kd 就是我们搜索的关键词,pn 就是当前页码。first 默认就行了,不用管它。剩下的事情就是构造请求,来下载 30 个页面的数据了。
4.构造请求 解析数据
构造请求很简单,我们还是用 requests 库来搞定。首先我们构造出表单数据
data = {'first': 'true', 'pn': page, 'kd': lang_name}
之后用 requests 来请求url地址,解析得到的 JSON 数据就算大功告成了。由于拉勾对爬虫限制比较严格,我们需要把浏览器中 headers 字段全部加上,而且把爬虫间隔调大一点,我后面设置的为 10-20s,然后就能正常获取数据了。
import requests
def get_json(url, page, lang_name):
headers = {
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Content-Length': '23',
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
data = {'first': 'false', 'pn': page, 'kd': lang_name}
json = requests.post(url, data, headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i.get('companyShortName', '无'))
info.append(i.get('companyFullName', '无'))
info.append(i.get('industryField', '无'))
info.append(i.get('companySize', '无'))
info.append(i.get('salary', '无'))
info.append(i.get('city', '无'))
info.append(i.get('education', '无'))
info_list.append(info)
return info_list
4.获取所有数据
了解了如何解析数据,剩下的就是连续请求所有页面了,我们构造一个函数来请求所有 30 页的数据。
def main():
lang_name = 'python'
wb = Workbook()
conn = get_conn()
for i in ['北京', '上海', '广州', '深圳', '杭州']:
page = 1
ws1 = wb.active
ws1.title = lang_name
url = 'https://www.lagou.com/jobs/positionAjax.json?city={}&needAddtionalResult=false'.format(i)
while page < 31:
info = get_json(url, page, lang_name)
page += 1
import time
a = random.randint(10, 20)
time.sleep(a)
for row in info:
insert(conn, tuple(row))
ws1.append(row)
conn.close()
wb.save('{}职位信息.xlsx'.format(lang_name))
if __name__ == '__main__':
main()
总结
如果对数据库不熟悉的同学,直接注释掉 main 函数中的三行数据库代码就行了,我在注释中有说明是哪三行。
到此这篇关于利用Python实现岗位的分析报告的文章就介绍到这了,更多相关Python岗位分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据可视化自制职位分析生成岗位分析数据报表
目录 前言 1. 核心功能设计 可视化展示岗位表格数据 分析岗位薪资情况 分析岗位公司情况 数据分析导出 2. GUI设计与实现 3. 功能实现 3.1 职位数据爬虫 3.2 数据预处理 3.3 岗位数据展示 3.4 薪资图表可视化 3.5 岗位公司情况统计 3.6 预览保存 前言 为什么要进行职位分析?职位分析是人力资源开发和管理的基础与核心,是企业人力资源规划.招聘.培训.薪酬制定.绩效评估.考核激励等各项人力资源管理工作的依据.其次我们可以根据不同岗位的职位分析,可视化展示各岗位的数据分析
-
Python爬取智联招聘数据分析师岗位相关信息的方法
进入智联招聘官网,在搜索界面输入'数据分析师',界面跳转,按F12查看网页源码,点击network 选中XHR,然后刷新网页 可以看到一些Ajax请求, 找到画红线的XHR文件,点击可以看到网页的一些信息 在Header中有Request URL,我们需要通过找寻Request URL的特点来构造这个请求网址, 点击Preview,可以看到我们所需要的信息就存在result中,这信息基本是json格式,有些是列表: 下面我们通过Python爬虫来爬取上面的信息: 代码如下: import req
-
Python数据分析之Python和Selenium爬取BOSS直聘岗位
一.数据爬取的代码 #encoding='utf-8' from selenium import webdriver import time import re import pandas as pd import os def close_windows(): #如果有登录弹窗,就关闭 try: time.sleep(0.5) if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("c
-
利用Python半自动化生成Nessus报告的方法
0x01 前言 Nessus是一个功能强大而又易于使用的远程安全扫描器,Nessus对个人用户是免费的,只需要在官方网站上填邮箱,立马就能收到注册号了,对应商业用户是收费的.当然,个人用户是有16个IP限制,通过企业邮箱可以体验免费7天的Nessus专业版,IP无限制. Nessus激活码获取地址:https://www.tenable.com/products/nessus/activation-code 0x02 Nessus使用 登录后通过New Scan创建扫描任务,扫描完成后,我们即可
-
利用Python自制网页并实现一键自动生成探索性数据分析报告
目录 前言 上传文件以及变量的筛选 前言 今天小编带领大家用Python自制一个自动生成探索性数据分析报告这样的一个工具,大家只需要在浏览器中输入url便可以轻松的访问,如下所示: 第一步 首先我们导入所要用到的模块,设置网页的标题.工具栏以及logo的导入,代码如下: from st_aggrid import AgGrid import streamlit as st import pandas as pd import pandas_profiling from streamlit_pan
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
利用python调用摄像头的实例分析
这篇文章主要介绍了python调用摄像头的示例代码,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下 一.打开摄像头 import cv2 import numpy as np def video_demo(): capture = cv2.VideoCapture(0)#0为电脑内置摄像头 while(True): ret, frame = capture.read()#摄像头读取,ret为是否成功打开摄像头,true,false. frame为视频的每一帧图像 frame = c
-
如何利用Python实现简单C++程序范围分析
目录 1.实验说明 2.项目使用 3.算法原理 3.1构建CFG 3.2构建ConstraintGraph 3.3构建E-SSAConstraintGraph 3.4三步法 3.4.1Widen 3.4.2FutureResolution& Narrow 4.实验结果 5.总结 1. 实验说明 问题要求:针对静态单赋值(SSA)形式的函数中间代码输入,输出函数返回值的范围 实现思路: 基本根据 2013年在CGO会议上提出的“三步法”范围分析法加以实现[3],求得各个变量的范围 算法优势:空间复
-
利用Python分析一下最近的股票市场
目录 一.数据获取 二.合并数据 三.绘制股票每日百分比变化 四.箱线图 五.计算月化夏普比率 六.结论 一.数据获取 数据获取范围为2022年一月一日到2022年2月25日,获取的数据为俄罗斯黄金,白银,石油,银行,天然气: # 导入模块 import numpy as np import pandas as pd import yfinance as yf # GC=F黄金,SI=F白银,ROSN.ME俄罗斯石油,SBER.ME俄罗斯银行,天然气 tickerSymbols = ['GC=F
-
利用Python对中国500强排行榜数据进行可视化分析
目录 一.前言 二.数据采集 1.开始爬取 获取企业列表 获取企业对应url 获取每一个企业相关数据 2.保存到Excel 三.可视化分析 1.省份分布 导入相关可视化库 统计数据 地图可视化 2.营业收入年增率 3.营业收入年减率 4.利润年增率 5.利润年减率 6.排名上升最快20家企业 7.排名下降最快20家企业 8.资产区间分布 9.市值区间分布 10.营业收入区间分布 11.利润区间分布 12.中国500强企业-排名前10营业收入.利润.资产.市值.股东权益 四.总结 一.前言 今天来
-
利用python实现简单的情感分析实例教程
目录 1 数据导入及预处理 1.1 数据导入 1.2 数据描述 1.3 数据预处理 2 情感分析 2.1 情感分 2.2 情感分直方图 2.3 词云图 2.4 关键词提取 3 积极评论与消极评论 3.1 积极评论与消极评论占比 3.2 消极评论分析 总结 python实现简单的情感分析 1 数据导入及预处理 1.1 数据导入 # 数据导入 import pandas as pd data = pd.read_csv('../data/京东评论数据.csv') data.head() 1.2 数据
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
利用Python实现自动生成图文并茂的数据分析
目录 前言 1.一行命令,安装这个库 2.核心代码模块导入 ①提前导入相关内容,并且注册字体 ②注册字体 ③生成报告 前言 reportlab是Python的一个标准库,可以画图.画表格.编辑文字,最后可以输出PDF格式.它的逻辑和编辑一个word文档或者PPT很像.有两种方法: 建立一个空白文档,然后在上面写文字.画图等: 建立一个空白list,以填充表格的形式插入各种文本框.图片等,最后生成PDF文档. 因为需要产生一份给用户看的报告,里面需要插入图片.表格等,所以采用的是第二种方法. 1.