Python爬虫使用脚本登录Github并查看信息
前言分析目标网站的登录方式
目标地址: https://github.com/login
登录方式做出分析:
第一,用form表单方式提交信息,
第二,有csrf_token,
第三 ,是以post请求发送用户名和密码时,需要第一次get请求的cookie
第四,登录成功以后,请求其他页面是只需要带第一次登录成功以后返回的cookie就可以。
以get发送的请求获取我们想要的token和cookie

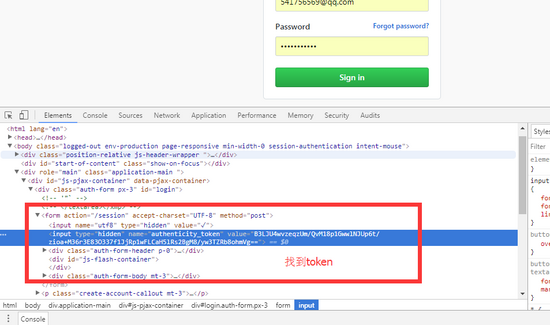
代码:
import requests
from bs4 import BeautifulSoup
r1 = requests.get('https://github.com/login')
soup = BeautifulSoup(r1.text,features='lxml') #生成soup 对象
s1 = soup.find(name='input',attrs={'name':'authenticity_token'}).get('value')
#查到我们要的token
r1_cookies = r1.cookies.get_dict() # 下次提交用户名时用的cookie
# print(r1_cookies)
# print(s1)
#结果::
{'logged_in': 'no', '_gh_sess': 'VDFWa2hJWjFMb1hpRUFLRDVhUmc3MXg1Tk02TDhsUnhDMERuNGpyT2Y4STlQZ2xCV1lCZEFhK21wdFR1bkpGYUV0WEJzcDEydWFzcm93
aVc4Nk91Q2JicmtRV0NIQ0lRSWM4aFhrSVFYbCtCczBwdnhVN0YySVJJNUFpQnhyTzNuRkJwNDJZUWxUcEk2M2JkM3VSMDdXVHNOY1htQkthckJQZDJyUVR2RzBNUkU3VnltRVF2U
m1admU3c3YzSGlyVnVZVm0ycnA1eUhET1JRVWNLN0pSbndKWjljMGttNG5URWJ1eU8rQjZXNEMxVEthcGVObDFBY2gvc2ZzWXcvWWZab29wQWJyU0l6cmZscWhBQUlzYTA3dTRtb
3l1S0hDYytHY2V1SUhEWlZvVlZoSWZpTzBjNmlidFF2dzI2bWgtLTJON1lqbm5jWUtSYmtiVEM1clJPakE9PQ%3D%3D--897dbc36c123940c8eae5d86f276dead8318fd6c'}
pRz0wapEbu5shksGCeSN0FijWoU9ALw8EPUsXlqgcw1Ezirl0VbSKvkTYqIe8VhxhPH2H/uzGaV6XX+yjTGoVA==
获取这两个值就可以,进行下一步发送登录请求:
第二步post方式提交用户名密码
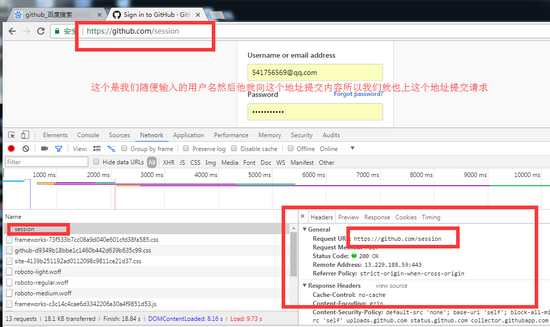
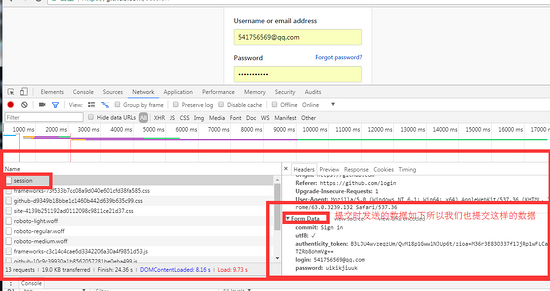
代码::
这个代码接着上面的get请求,只是post请求的部分,
r2 = requests.post(
'https://github.com/session',
data ={
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':s1,
'login':'541756569@qq.com',
'password':'用户名密码' # 填上正确的用户名即可
},
cookies = r1.cookies.get_dict(), # 这里需要第一次的cookie
)
print(r2.cookies.get_dict()) # 这个是成功以后的cookie
成功以后就返回登录页面的信息。
基于post登录成功后查看个人详情页。
这里只需要带着登录成功以后的cookie 就可以
#完整代码
import requests
from bs4 import BeautifulSoup
r1 = requests.get('https://github.com/login')
soup = BeautifulSoup(r1.text,features='lxml')
s1 = soup.find(name='input',attrs={'name':'authenticity_token'}).get('value')
r1_cookies = r1.cookies.get_dict()
print(r1_cookies)
print(s1)
r2 = requests.post(
'https://github.com/session',
data ={
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':s1,
'login':'541756569@qq.com',
'password':'密码'
},
cookies = r1.cookies.get_dict(),
)
查看个人详情页
print(r2.cookies.get_dict())
r3 = requests.get(
'https://github.com/13131052183/product', #查看个人的详情页
cookies = r2.cookies.get_dict()
)
print(r3.text)
总结
以上所述是小编给大家介绍的Python爬虫使用脚本登录Github并查看信息,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看.爬虫用的是python3.3开发的,主要用到了urllib.request和BeautifulSoup模块. urllib模块提供了从万维网中获取数据的高层接口,当我们用urlopen()打开一个URL时,就相当于我们用Python内建的open()打开一个文件.但不同的是,前者接收一个URL作为参数,并且没有办法对打开的文件流进行seek操作(从底层的角度看,因为实际上操作的是socket,所以理所当然地没办法进行seek操作),而后
-

基于Python实现ComicReaper漫画自动爬取脚本过程解析
这篇文章主要介绍了基于Python实现ComicReaper漫画自动爬取脚本过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 讲真的, 手机看漫画翻页总是会手残碰到页面上的广告好吧... 要是能只需要指定一本漫画的主页URL就能给我返回整本漫画就好了... 这促使我产生了使用Python 3来实现, 做一个 ComicReaper(漫画收割者) 的想法! 本文所用漫画链接 : http://www.manhuadb.com/manhua/
-
python编写网页爬虫脚本并实现APScheduler调度
前段时间自学了python,作为新手就想着自己写个东西能练习一下,了解到python编写爬虫脚本非常方便,且最近又学习了MongoDB相关的知识,万事具备只欠东风. 程序的需求是这样的,爬虫爬的页面是京东的电子书网站页面,每天会更新一些免费的电子书,爬虫会把每天更新的免费的书名以第一时间通过邮件发给我,通知我去下载. 一.编写思路: 1.爬虫脚本获取当日免费书籍信息 2.把获取到的书籍信息与数据库中的已有信息作比较,如果书籍存在不做任何操作,书籍不存在,执行插入数据库的操作,把数据的信息存入Mo
-
python实现爬虫下载漫画示例
复制代码 代码如下: #!/usr/bin/python3.2import os,socketimport urllibimport urllib.request,threading,timeimport re,sysglobal manhuaweb,weburl,floder,chapterbegin,currentthreadnum,threadcount,mutex,mutex2 weburl=''floder=''chapterbegin=0currentthreadnum=0threa
-
python爬虫_实现校园网自动重连脚本的教程
一.背景 最近学校校园网不知道是什么情况,总出现掉线的情况.每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录.系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网.每次掉线后,再打开任意网页就是这个页面. 二.实现代码 #-*- coding:utf-8 -*- __author__ = 'pf' import time import requests class Login: #初始化 def __init__(self): #检测间隔时间,单位
-
Linux部署python爬虫脚本,并设置定时任务的方法
去年因项目需要,用python写了个爬虫.因爬到的数据需要存到生产环境的PG数据库.所以需要将脚本部署到CentOS服务器,并设置定时任务,自动启动脚本. 实施步骤如下: 1.安装pip(操作系统自带了python2.6可以直接用,但是没有pip) # 下载pip安装包 wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=834b2904f92d46aaa333267fb1c922bb" --
-
python脚本爬取字体文件的实现方法
前言 大家应该都有所体会,为了提高验证码的识别准确率,我们当然要首先得到足够多的测试数据.验证码下载下来容易,但是需要人脑手工识别着实让人受不了,于是我就想了个折衷的办法--自己造验证码. 为了保证多样性,首先当然需要不同的字模了,直接用类似ttf格式的字体文件即可,网上有很多ttf格式的字体包供我们下载.当然,我不会傻到手动下载解压缩,果断要写个爬虫了. 实现方法 网站一:fontsquirrel.com 这个网站的字体可以免费下载,但是有很多下载点都是外链连接到其他网站的,这部分得忽略掉.
-
Python爬虫使用脚本登录Github并查看信息
前言分析目标网站的登录方式 目标地址: https://github.com/login 登录方式做出分析: 第一,用form表单方式提交信息, 第二,有csrf_token, 第三 ,是以post请求发送用户名和密码时,需要第一次get请求的cookie 第四,登录成功以后,请求其他页面是只需要带第一次登录成功以后返回的cookie就可以. 以get发送的请求获取我们想要的token和cookie 代码: import requests from bs4 import BeautifulSou
-
Python爬虫实现自动登录、签到功能的代码
更新 2016/8/9:最近发现目标网站已经屏蔽了这个登录签到的接口(PS:不过我还是用这个方式赚到了将近一万点积分·····) 前几天女朋友跟我说,她在一个素材网站上下载东西,积分总是不够用,积分是怎么来的呢,是每天登录网站签到获得的,当然也能购买,她不想去买,因为偶尔才会用一次,但是每到用的时候就发现积分不够,又记不得每天去签到,所以就有了这个纠结的事情.怎么办呢,想办法呗,于是我就用python写了个小爬虫,每天去自动帮她签到挣积分.废话不多说,下面就讲讲代码. 我这里用的是python3
-
python爬虫使用cookie登录详解
前言: 什么是cookie? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面,这样就达到了我们的目的. 一.Urllib库简介 Urllib是python内置的HTTP请求库,官方地址:https://docs.python.org/3/library/urllib.ht
-
python爬虫-模拟微博登录功能
微博模拟登录 这是本次爬取的网址:https://weibo.com/ 一.请求分析 找到登录的位置,填写用户名密码进行登录操作 看看这次请求响应的数据是什么 这是响应得到的数据,保存下来 exectime: 8 nonce: "HW9VSX" pcid: "gz-4ede4c6269a09f5b7a6490f790b4aa944eec" pubkey: "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D24
-
Python爬虫实现验证码登录代码实例
很多网站为了避免被恶意访问,需要设置验证码登录,避免非人类的访问,Python爬虫实现验证码登录的原理则是先到登录页面将生成的验证码保存下来,然后人为输入后,包装后再POST给服务器,实现验证,这里还涉及到了Cookie,其实Cookie保存在本地主机上,避免用户重复输入用户名和密码,在连接服务器的时候将访问连接和Cookie组装起来POST给服务器. 这里涉及到了两次向服务器POST,一次是Cookie,这里还自行设计想要Cookie的内容,由于是要登录,Cookie中存放的则是用户名和密码.
-
python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
-
Python爬虫实战演练之采集拉钩网招聘信息数据
目录 本文要点: 环境介绍 本次目标 爬虫块使用 内置模块: 第三方模块: 代码实现步骤: (爬虫代码基本步骤) 开始代码 导入模块 发送请求 解析数据 加翻页 保存数据 运行代码,得到数据 本文要点: 爬虫的基本流程 requests模块的使用 保存csv 可视化分析展示 环境介绍 python 3.8 pycharm 2021专业版 激活码 Jupyter Notebook pycharm 是编辑器 >> 用来写代码的 (更方便写代码, 写代码更加舒适) python 是解释器 >&
-
python爬虫之自动登录与验证码识别
在用爬虫爬取网站数据时,有些站点的一些关键数据的获取需要使用账号登录,这里可以使用requests发送登录请求,并用Session对象来自动处理相关Cookie. 另外在登录时,有些网站有时会要求输入验证码,比较简单的验证码可以直接用pytesser来识别,复杂的验证码可以依据相应的特征自己采集数据训练分类器. 以CSDN网站的登录为例,这里用Python的requests库与pytesser库写了一个登录函数.如果需要输入验证码,函数会首先下载验证码到本地,然后用pytesser识别验证码后登
-
python爬虫库scrapy简单使用实例详解
最近因为项目需求,需要写个爬虫爬取一些题库.在这之前爬虫我都是用node或者php写的.一直听说python写爬虫有一手,便入手了python的爬虫框架scrapy. 下面简单的介绍一下scrapy的目录结构与使用: 首先我们得安装scrapy框架 pip install scrapy 接着使用scrapy命令创建一个爬虫项目: scrapy startproject questions 相关文件简介: scrapy.cfg: 项目的配置文件 questions/: 该项目的python模块.之
-
python爬虫开发之selenium模块详细使用方法与实例全解
python爬虫模块selenium简介 selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题. 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 一.声明浏览器对象 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入 from selenium import webdriver #webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里