pandas归一化与反归一化操作实现
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
if __name__ == '__main__':
"""
原数据
"""
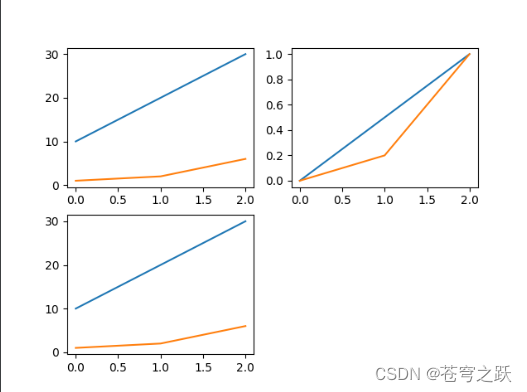
df = pd.DataFrame({'A': [10, 20, 30], 'B': [1, 2, 6]})
# 图表
plt.plot(df)
plt.show()
"""
归一化
"""
# 最小值
minimum = df.min()
# 最大值
maximum = df.max()
df_zero_one = (df - minimum) / (maximum - minimum)
# 图表
plt.plot(df_zero_one)
plt.show()
"""
反归一化
"""
df_un_zero_one = (maximum - minimum) * df_zero_one + minimum
# 图表
plt.plot(df_un_zero_one)
plt.show()
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
if __name__ == '__main__':
"""
原数据
"""
df = pd.DataFrame({'A': [10, 20, 30], 'B': [1, 2, 6]})
# 图表
subplot_1 = plt.subplot(2, 2, 1)
subplot_1.plot(df)
"""
归一化
"""
# 最小值
minimum = df.min()
# 最大值
maximum = df.max()
df_zero_one = (df - minimum) / (maximum - minimum)
# 图表
subplot_2 = plt.subplot(2, 2, 2)
subplot_2.plot(df_zero_one)
"""
反归一化
"""
df_un_zero_one = (maximum - minimum) * df_zero_one + minimum
# 图表
subplot_3 = plt.subplot(2, 2, 3)
subplot_3.plot(df_un_zero_one)
plt.show()
到此这篇关于pandas归一化与反归一化操作实现的文章就介绍到这了,更多相关pandas归一化与反归一化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas 数据归一化以及行删除例程的方法
如下所示: #coding:utf8 import pandas as pd import numpy as np from pandas import Series,DataFrame # 如果有id列,则需先删除id列再进行对应操作,最后再补上 # 统计的时候不需要用到id列,删除的时候需要考虑 # delete row def row_del(df, num_percent, label_len = 0): #print list(df.count(axis=1)) col_num = l
-
pandas归一化与反归一化操作实现
import numpy as np import pandas as pd import matplotlib.pylab as plt if __name__ == '__main__': """ 原数据 """ df = pd.DataFrame({'A': [10, 20, 30], 'B': [1, 2, 6]}) # 图表 plt.plot(df) plt.show() """ 归一化 "&qu
-
pytorch 归一化与反归一化实例
ToTensor中就有转到0-1之间了. # -*- coding:utf-8 -*- import time import torch from torchvision import transforms import cv2 transform_val_list = [ # transforms.Resize(size=(160, 160), interpolation=3), # Image.BICUBIC transforms.ToTensor(), transforms.Normali
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Python连接HDFS实现文件上传下载及Pandas转换文本文件到CSV操作
1. 目标 通过hadoop hive或spark等数据计算框架完成数据清洗后的数据在HDFS上 爬虫和机器学习在Python中容易实现 在Linux环境下编写Python没有pyCharm便利 需要建立Python与HDFS的读写通道 2. 实现 安装Python模块pyhdfs 版本:Python3.6, hadoop 2.9 读文件代码如下 from pyhdfs import HdfsClient client=HdfsClient(hosts='ghym:50070')#hdfs地址
-

Pandas对CSV文件读写操作详解
目录 什么是 CSV 文件 CSV 库解析 CSV 文件 读取 CSV 文件 CSV reader 参数 CSV 文件的写入 使用 pandas 库解析 CSV 文件 pandas 读取 CSV 文件 pandas 写入 CSV 文件 什么是 CSV 文件 CSV 文件(逗号分隔值文件)是一种纯文本文件,它使用特定的结构来排列表格数据.因为它是一个纯文本文件,所以只能包含实际的文本数据,换句话说就是可打印的 ASCII 或 Unicode 字符. 通常,CSV 文件的结构由其名称给出,使用逗号分
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
Python+pandas编写命令行脚本操作excel的tips详情
目录 一.python logging日志模块简单封装 二.pandas编写命令行脚本操作excel的小tips 1.tips 1.1使用说明格式 1.2接收操作目录方法 1.3检测并读取目录下的excel,并限制当前目录只能放一个excel 1.4备份excel 1.5报错暂停,并显示异常信息 1.6判断excel是否包含某列,不包含就新建 1.7进度展示与阶段保存 一.python logging日志模块简单封装 项目根目录创建 utils/logUtil.py import logging
-
Pandas读存JSON数据操作示例详解
目录 引言 读取json数据 模拟数据 参数orident orident="split" orient="records" orient="index" orient="columns" orient="values" to_json 引言 本文介绍的如何使用Pandas来读取各种json格式的数据,以及对json数据的保存 读取json数据 使用的是pd.read_json函数,见官网:pandas.p
-
pandas数据筛选和csv操作的实现方法
1. 数据筛选 a b c 0 0 2 4 1 6 8 10 2 12 14 16 3 18 20 22 4 24 26 28 5 30 32 34 6 36 38 40 7 42 44 46 8 48 50 52 9 54 56 58 (1)单条件筛选 df[df['a']>30] # 如果想筛选a列的取值大于30的记录,但是之显示满足条件的b,c列的值可以这么写 df[['b','c']][df['a']>30] # 使用isin函数根据特定值筛选记录.筛选a值等于30或者54的记录 df
-
pandas || df.dropna() 缺失值删除操作
df.dropna()函数用于删除dataframe数据中的缺失数据,即 删除NaN数据. 官方函数说明: DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values. See the User Guide for more on which values are considered missing, and how to work with missing