详解基于Jupyter notebooks采用sklearn库实现多元回归方程编程
一、导入excel文件和相关库
import pandas;
import matplotlib;
from pandas.tools.plotting import scatter_matrix;
data = pandas.read_csv("D:\\面积距离车站.csv",engine='python',encoding='utf-8')
显示文件大小
data.shape
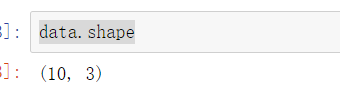
data
二.绘制多个变量两两之间的散点图:scatter_matrix()方法
#绘制多个变量两两之间的散点图:scatter_matrix()方法
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
scatter_matrix(
data[["area","distance", "money"]],
figsize=(10, 10), diagonal='kde'
) #diagonal参数表示变量与变量本身之间的绘图方式,kde代表直方图
#求相关系数矩阵
data[["area", "distance", "money"]].corr()
x = data[["area", "distance"]]
y = data[["money"]]
三、导入sklearn
from sklearn.linear_model import LinearRegression
#建模
lrModel = LinearRegression()
#训练模型
lrModel.fit(x, y)
#评分
R2=lrModel.score(x, y)
print("R的平方:",R2)
#预测
lrModel.predict([[10, 110],[20, 110]])
#查看参数
lrModel.coef_
#查看截距
lrModel.intercept_
结果如下:
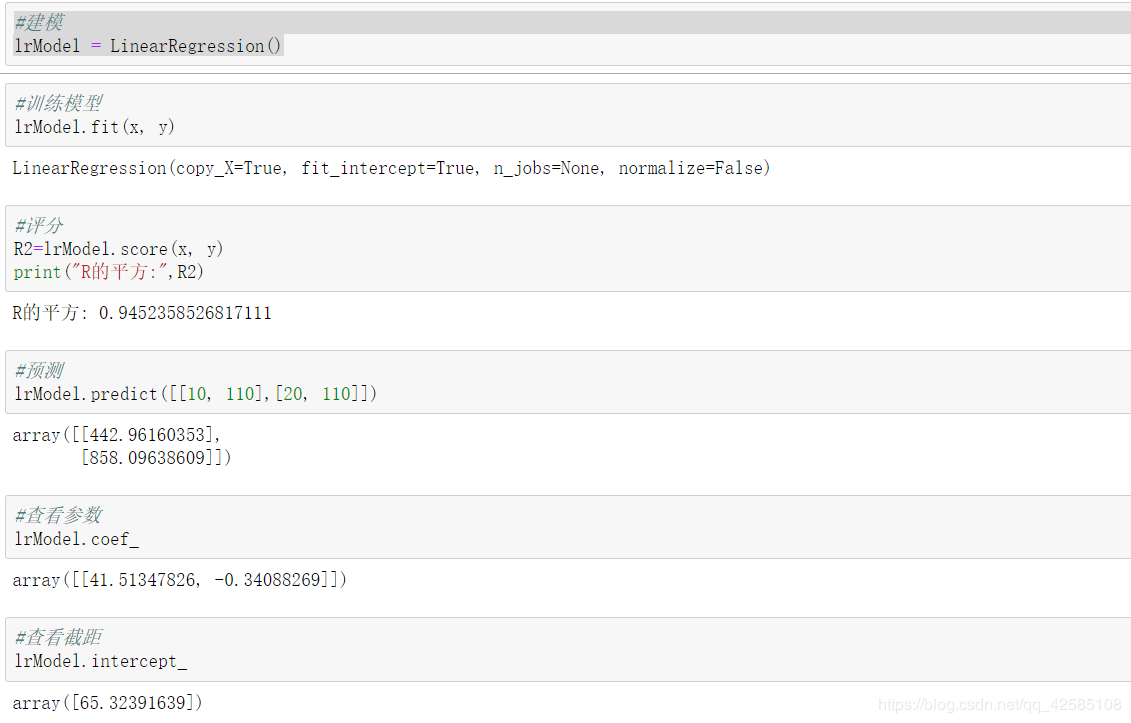
回归方程为:y=41.51x1-0.34x2+65.32
四、python全部代码
import pandas;
import matplotlib;
from pandas.tools.plotting import scatter_matrix;
data.shape
#绘制多个变量两两之间的散点图:scatter_matrix()方法
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
scatter_matrix(
data[["area","distance", "money"]],
figsize=(10, 10), diagonal='kde'
) #diagonal参数表示变量与变量本身之间的绘图方式,kde代表直方图
#求相关系数矩阵
data[["area", "distance", "money"]].corr()
x = data[["area", "distance"]]
y = data[["money"]]
from sklearn.linear_model import LinearRegression
#建模
lrModel = LinearRegression()
#训练模型
lrModel.fit(x, y)
#评分
R2=lrModel.score(x, y)
print("R的平方:",R2)
#预测
lrModel.predict([[10, 110],[20, 110]])
#查看参数
lrModel.coef_
#查看截距
lrModel.intercept_
到此这篇关于详解基于Jupyter notebooks采用sklearn库实现多元回归方程编程的文章就介绍到这了,更多相关Jupyter notebooks sklearn多元回归方程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用sklearn实现的各种回归算法示例
本文实例讲述了Python使用sklearn实现的各种回归算法.分享给大家供大家参考,具体如下: 使用sklearn做各种回归 基本回归:线性.决策树.SVM.KNN 集成方法:随机森林.Adaboost.GradientBoosting.Bagging.ExtraTrees 1. 数据准备 为了实验用,我自己写了一个二元函数,y=0.5*np.sin(x1)+ 0.5*np.cos(x2)+0.1*x1+3.其中x1的取值范围是0~50,x2的取值范围是-10~10,x1和x2的训练集一共有5
-
sklearn+python:线性回归案例
使用一阶线性方程预测波士顿房价 载入的数据是随sklearn一起发布的,来自boston 1993年之前收集的506个房屋的数据和价格.load_boston()用于载入数据. from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import time from sklearn.linear_model import LinearRegression bosto
-
python sklearn库实现简单逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Reduction).分类(Classfication).聚类(Clustering)等方法.当我们面临机器学习问题时,便可根据下图来选择相应的方法. Sklearn具有以下特点: 简单高效的数据挖掘和数据分析工具 让每个人能够在复杂环境中重复使用 建立NumPy.Scipy.MatPlotLib之上 代
-
详解基于Jupyter notebooks采用sklearn库实现多元回归方程编程
一.导入excel文件和相关库 import pandas; import matplotlib; from pandas.tools.plotting import scatter_matrix; data = pandas.read_csv("D:\\面积距离车站.csv",engine='python',encoding='utf-8') 显示文件大小 data.shape data 二.绘制多个变量两两之间的散点图:scatter_matrix()方法 #绘制多个变量两两之间的
-

详解基于pycharm的requests库使用教程
目录 requests库安装和导入 requests库的get请求 requests库的post请求 requests库的代理 requests库的cookie 自动识别验证码 requests库安装和导入 第一步:cmd打开命令行,使用如下命令安装requests库. pip install requests 由于我的安装过了,所以如下: 如果提示你pip版本需要更新,按照提示的指令输入即可更新. 第二步:cmd使用如下命令,验证requests库安装完成. pip list 第三步:在pyc
-
mysql数据库详解(基于ubuntu 14.0.4 LTS 64位)
1.mysql数据库的组成与相关概念 首先明白,mysql是关系型数据库,和非关系型数据库中最大的不同就是表的概念不一样. +整个mysql环境可以理解成一个最大的数据库:A +用mysql创建的数据库B是属于A的,是数据的仓库,相当于系统中的文件夹 +数据表C:是存放数据的具体场所,相当于系统中的文件,一个数据库B中包含若干个数据表C(注意此处的数据库B和A不一样) +记录D:数据表中的一行称为一个记录,因此,我们在创建数据表时,一定要创建一个id列,用于标识"这是第几条记录",id
-
详解基于Mybatis-plus多租户实现方案
一.引言 小编先解释一下什么叫多租户,什么场景下使用多租户. 多租户是一种软件架构技术,在多用户的环境下,共有同一套系统,并且要注意数据之间的隔离性. 举个实际例子:小编曾经开发过一套支付宝程序,这套程序应用在不同的小程序上,当使用者访问不同,并且进入相对应的小程序页面,小程序则会把用户相关数据传输到小编这里.在传输的时候需要带上小程序标识(租户ID),以便小编将数据进行隔离. 当不同的租户使用同一套程序,这里就需要考虑一个数据隔离的情况. 数据隔离有三种方案: 1.独立数据库:简单来说就是一个
-
详解基于python的图像Gabor变换及特征提取
1.前言 在深度学习出来之前,图像识别领域北有"Gabor帮主",南有"SIFT慕容小哥".目前,深度学习技术可以利用CNN网络和大数据样本搞事情,从而取替"Gabor帮主"和"SIFT慕容小哥"的江湖地位.但,在没有大数据和算力支撑的"乡村小镇"地带,或是对付"刁民小辈","Gabor帮主"可以大显身手,具有不可撼动的地位.IT武林中,有基于C++和OpenCV,或
-
详解基于Facecognition+Opencv快速搭建人脸识别及跟踪应用
人脸识别技术已经相当成熟,面对满大街的人脸识别应用,像单位门禁.刷脸打卡.App解锁.刷脸支付.口罩检测........ 作为一个图像处理的爱好者,怎能放过人脸识别这一环呢!调研开搞,发现了超实用的Facecognition!现在和大家分享下~~ Facecognition人脸识别原理大体可分为: 1.通过hog算子定位人脸,也可以用cnn模型,但本文没试过: 2.Dlib有专门的函数和模型,实现人脸68个特征点的定位.通过图像的几何变换(仿射.旋转.缩放),使各个特征点对齐(将眼睛.嘴等部位移
-
详解基于深度学习的两种信源信道联合编码
概述 经典端对端无线通信系统如下图所示: 信源 xx使用信源编码,去除冗余得到比特流 ss. 对 ss进行信道编码(如 Turbo.LDPC 等)得到 yy,增加相应的校验位来抵抗信道噪声. 对比特流 yy进行调制(如 BPSK.16QAM 等)得到 zz,并经物理信道发送. 接收端对经信道后的符号 \bar{z}zˉ 进行解调.解码操作得到 \bar{x}xˉ. 根据定义信道方式不同,基于深度学习的信源信道联合编码(Deep JSCC)可以分为两类. 第一类,受无编码传输的启发,将信源编码.信
-
详解基于redis实现的四种常见的限流策略
目录 一.引言 二.固定时间窗口算法 三.滑动时间窗口算法 四.漏桶算法 五.令牌桶算法 一.引言 在web开发中功能是基石,除了功能以外运维和防护就是重头菜了.因为在网站运行期间可能会因为突然的访问量导致业务异常.也有可能遭受别人恶意攻击 所以我们的接口需要对流量进行限制.俗称的QPS也是对流量的一种描述 针对限流现在大多应该是令牌桶算法,因为它能保证更多的吞吐量.除了令牌桶算法还有他的前身漏桶算法和简单的计数算法 下面我们来看看这四种算法 二.固定时间窗口算法 固定时间窗口算法也可以叫做简单
-
详解C++11中的线程库
目录 一.线程库的介绍 1.1. 使用时的注意点 1.2. 线程函数参数 1.3. join与detach 二.原子性操作库 2.1. atomic 2.2. 锁 三.使用lambda表达式创建多个线程 四.条件变量 一.线程库的介绍 在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差.C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念.要使用标
-
详解Java对象转换神器MapStruct库的使用
目录 前言 MapStruct简介 MapStruct入门 1. 引入依赖 2. 需要转换的对象 3. 创建转换器 4. 验证 5. 自动生成的实现类 MapStruct进阶 场景1:属性名称不同.(基本)类型不同 场景2:统一映射不同类型 场景3:固定值.忽略某个属性.时间转字符串格式 场景4:为某个属性指定转换方法 场景5:多个参数合并为一个对象 场景6:已有目标对象,将源对象属性覆盖到目标对象 场景7:源对象两个属性合并为一个属性 小结 前言 在我们日常开发的程序中,为了各层之间解耦,一般