Python 自动登录淘宝并保存登录信息的方法
前段时间时间为大家讲解了如何使用requests库模拟登录淘宝,而今天我们将对该功能进行丰富。所以我们把之前的那个版本定为1.0,而今天修改的版本定为2.0。版本的迭代意味着功能的升级,那今天的2.0版本较之前的1.0版本有哪些改进呢?我们一起来看看!
1.0版本实现步骤
我们先来回顾一下模拟登录淘宝的步骤吧,我们还是先看看淘宝登录的详细时序图:
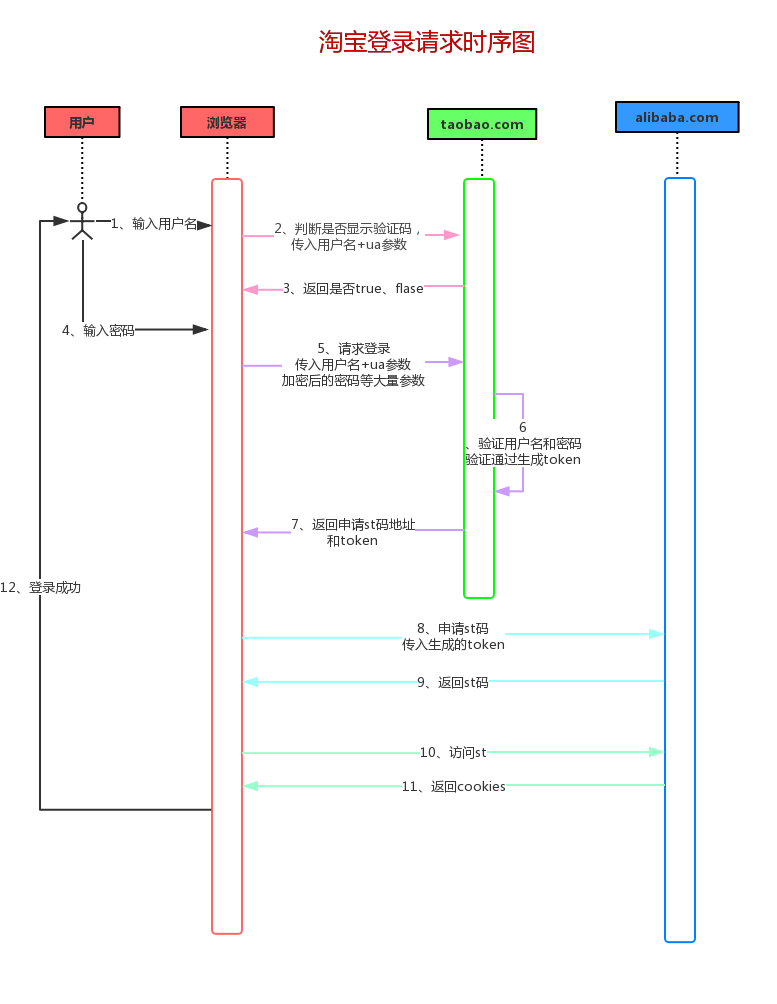
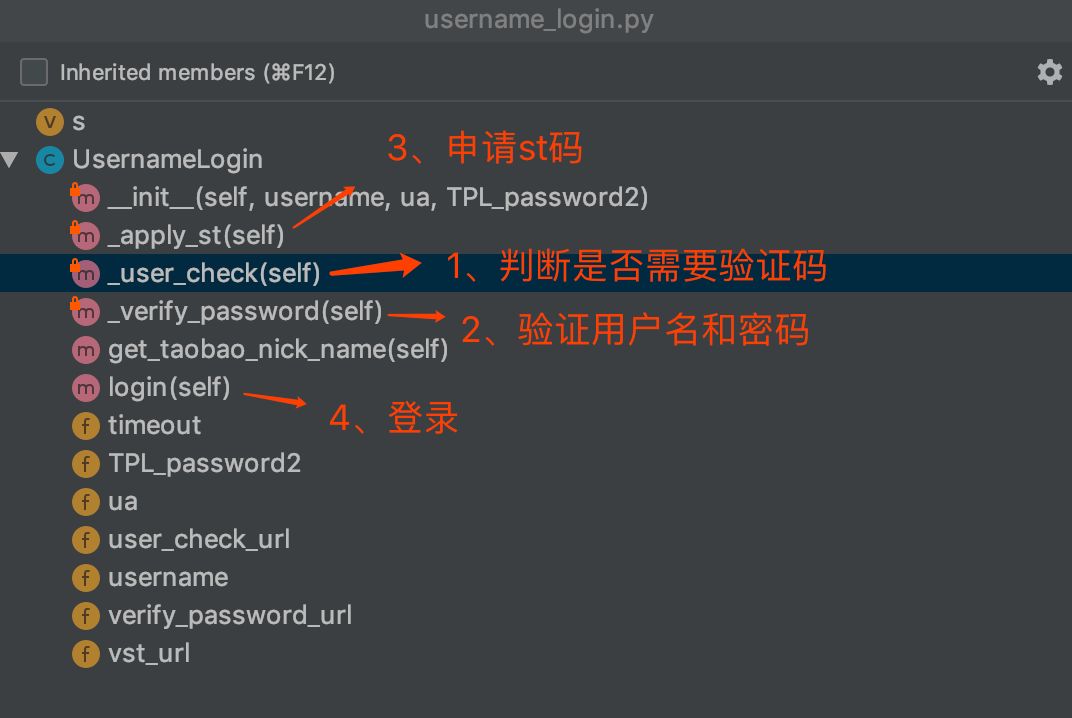
这是淘宝网登录的一个请求流程,而我们模拟登录也是根据这样的一个流程。但是在代码模拟登录的时候就不会分的这么细,我们根据封装的思想将整个登录流程封装在四个方法里面,可以看看下图。
为了便于大家理解四步登录法,我又画了一个流程图给大家看看:
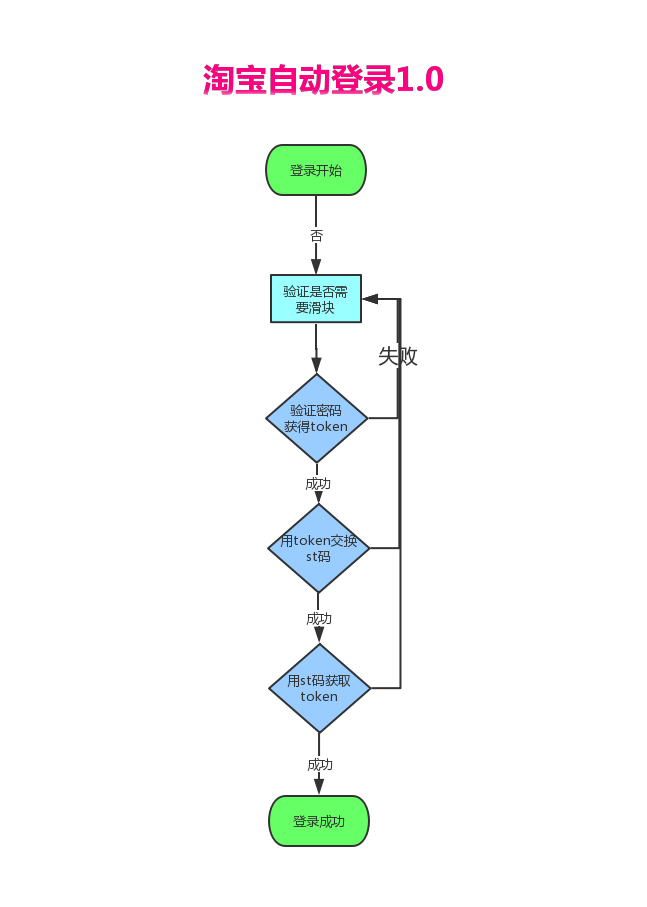
结合流程图,给大家简单 的 再讲解一遍这四步具体做了啥:
- 拿着用户名向淘宝(taobao.com)发起一个post的请求,判断是否出现滑块验证。
- 向淘宝(taobao.com)又发起一个post请求,验证用户名密码是否正确,如果正确则返回一个token。
- 拿着token去阿里巴巴(alibaba.com)交换st码。
- 获取st码之后,拿着st码获取cookies,登录成功。
在面试的时候也许面试官会问你是否爬取或自动登录过淘宝,流程是怎么的?大家就这个把这个四步登录法讲给面试官听 ,面试官不仅不会你的技术认可,也为认可你的逻辑思维缜密!
2.0版本新增功能
为什么要做2.0版本?因为我在做爬取淘宝商品的时候发现之前登录有一个很不方便的 地方:每次程序运行完后,登录的cookies就没了,也就是说下次又要重新登录。
而浏览器却可以保存cookies信息,所以我自然地想到了:将cookies序列化。
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。——百度百科
简单说序列化就是将对象持久性保存起来,因为原来对象是在内存中,程序运行完了就要释放内存,所有的对象、变量等都会被清除,而序列化则可以把他们保存到文件。即使程序关闭了,下次启动的时候可以读取文件到内存转回对象继续使用,而这个过程叫反序列化。
所以我们2.0的功能就是:将登录后的cookies保存到文件中,下次再登录先从cookies文件读取!也就是增加了一个保存cookies 的功能,我们再看看2.0的流程图。
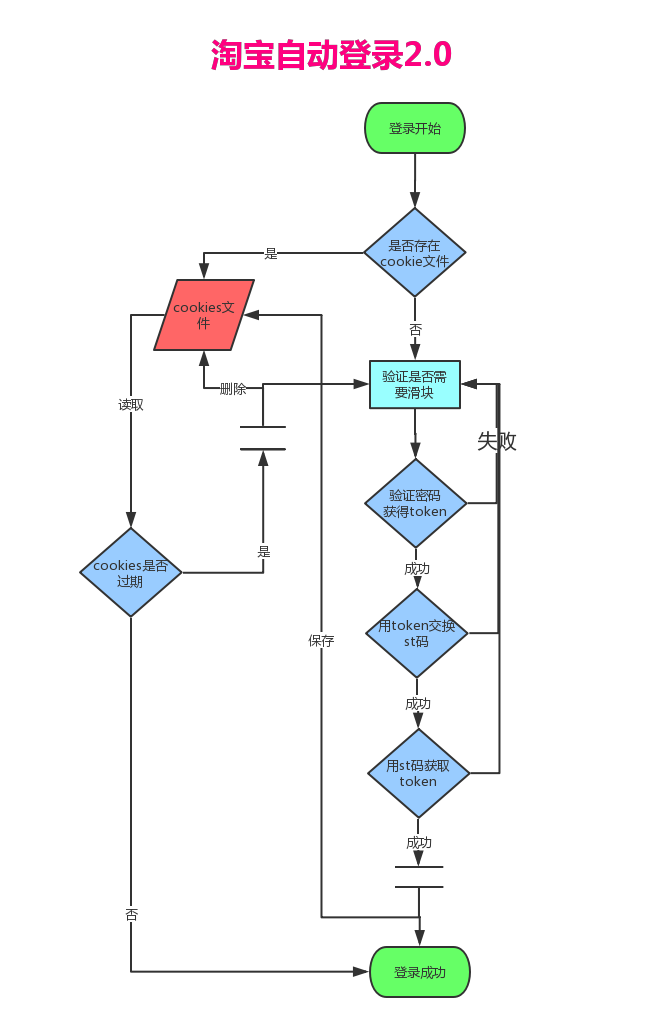
与1.0的流程图相比,其实就多了左边的cookies文件和cookies文件的校验,这也就是我们今天要讲的内容!
别看只是增加了一点点功能,却意义重大:因为这是一个 授人予渔的功能,你学会之后其他所有的登录都可以做序列化保存cookies,而且还可以做cookies池!
2.0版本新功能实现
根据上面的流程图,我们可以简单的分析量化一下增加的保存cookies这个共功能:
保存cookies:增加一个方法,当使用st码登录成功后,用来将cookies对象转化为文件
读取cookies:增加一个方法,用来读取cookies文件,将它转化为cookies对象
检查cookies:增加一个方法,用来判断cookies是否失效,如果失效则删除cookies文件,如果有效则直接登录成功!
根据以上三步,我们就可以开始撸代码了
1.保存cookies
保存cookies其实就叫序列化,我们先来看看代码:
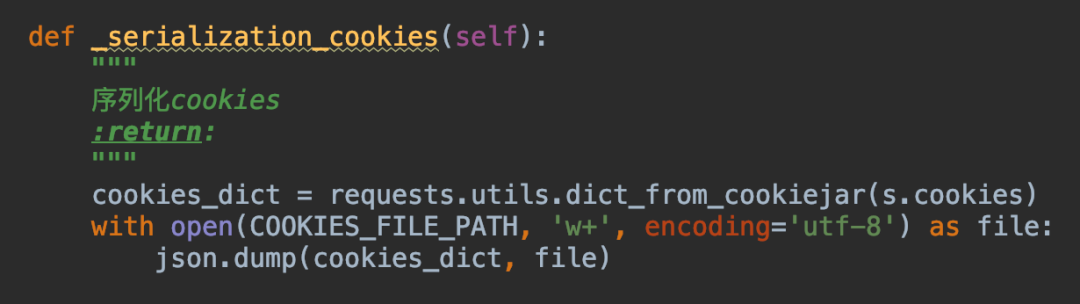
我们先获取cookies,然后再转为dict对象,最后将dict转化为JSON对象保存起来!
2.读取cookies
读取cookies就是将文件转转化为cookies对象,这一步叫反序列化,直接上代码:
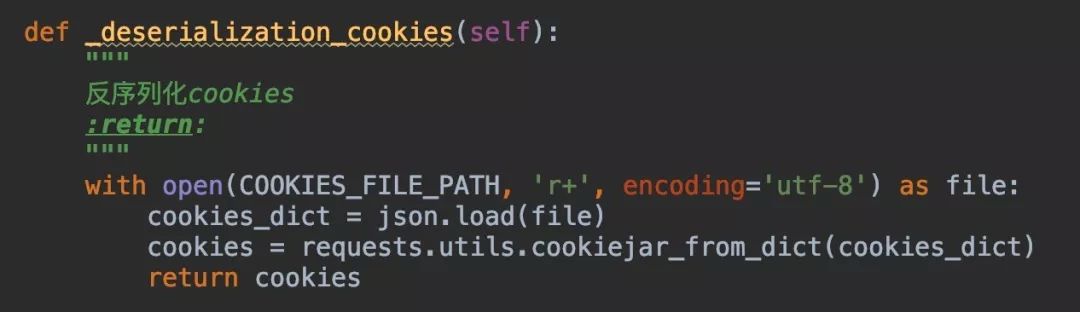
其实反序列化就是与序列化的步骤相反,先将文件转化为dict对象,然后再转化为cookies对象,最后赋值给Session对象!
3.检查cookies
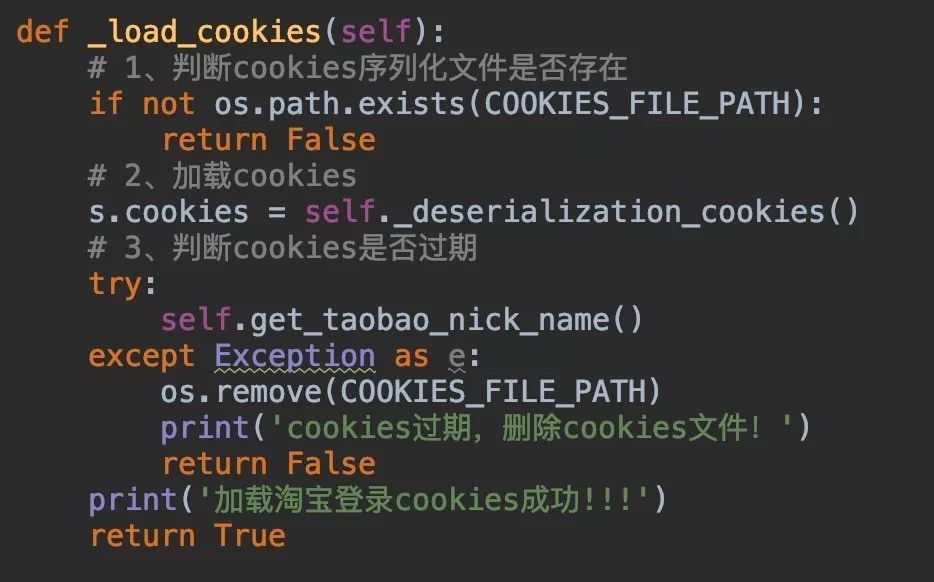
这一步我们需要先判断cookies文件是否存在,如果存在则读取cookies,之后再访问淘宝主页看看是否能成功,如果失败则说明cookies已过期,我们就删除cookies文件。
重构代码
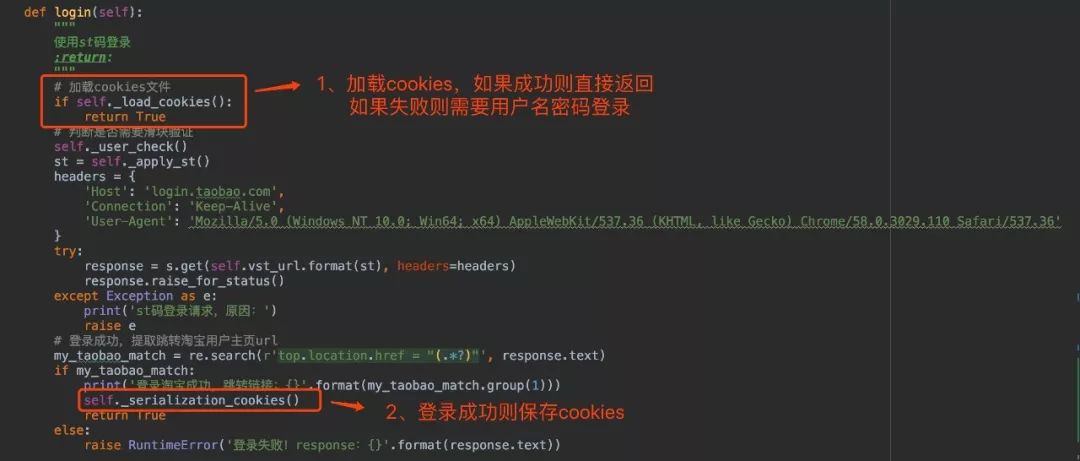
功能点实现之后我们看看怎么重构代码,根据流程图,我们需要在方法开头增加加载cookies的功能,再最后登录成功的时候增加保存cookies的方法,所以改动只有两处!
功能测试
在我们实际开发工作中 ,测试是一项非常重要的步骤。一般开发都需要先自测,如果不自测就直接提测的话,测试测出Bug你不仅会被怼被鄙视有些公司还会影响你的KPI。
我们来说说序列化cookies功能自测的流程吧:
首先我们登录,看看登录成功会不会将cookies保存为文件,这一步是测试序列化;
然后我们再登录一次,根据打印信息,看看是不是直接读取cookies文件登录的,这一步测试反序列化;
最后我们测试当cookies过期之后,会不会删除cookies文件,然后使用用户名密码登录,最后保存新的cookies文件。
1.测试正常登录
第一次登录是没有cookies文件的,所以正常使用用户名和密码登录,登录成功后保存cookies文件。
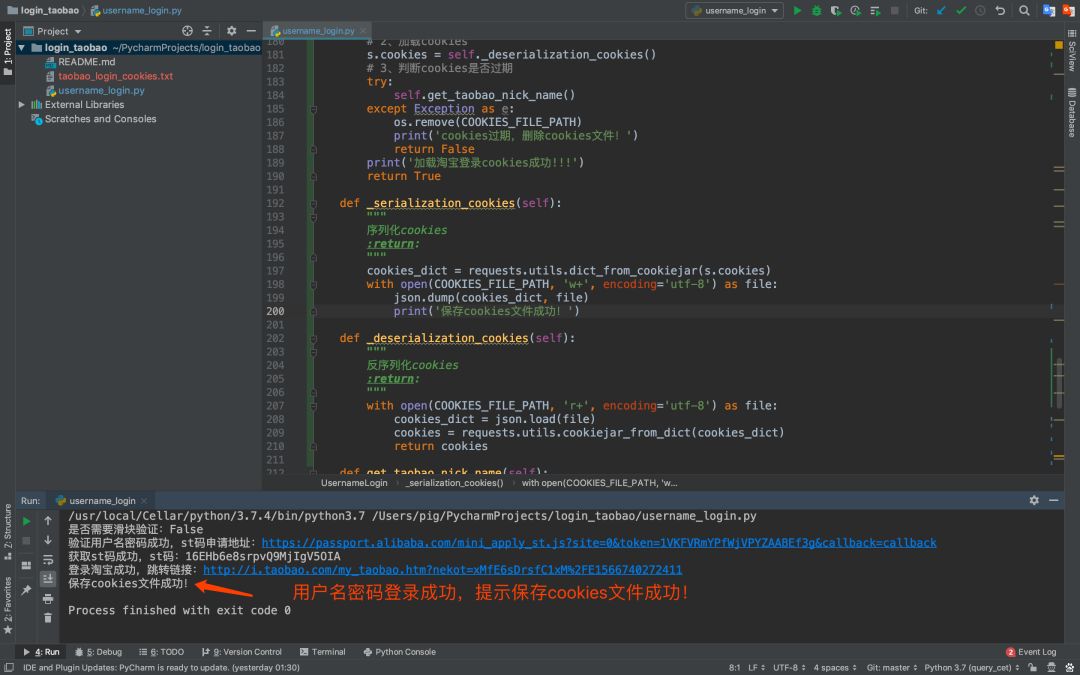
2.测试加载cookies登录
在正常登录之后,保存了cookeis文件,这里我们要测试是否能成功加载文件中的cookies:
3.测试cookies过期
大家都知道cookies都会有一个过期时间,而经过测试淘宝登录的过期时间大概为60分钟!cookies过期之后我们需要重新登录然后重新保存cookeis文件。
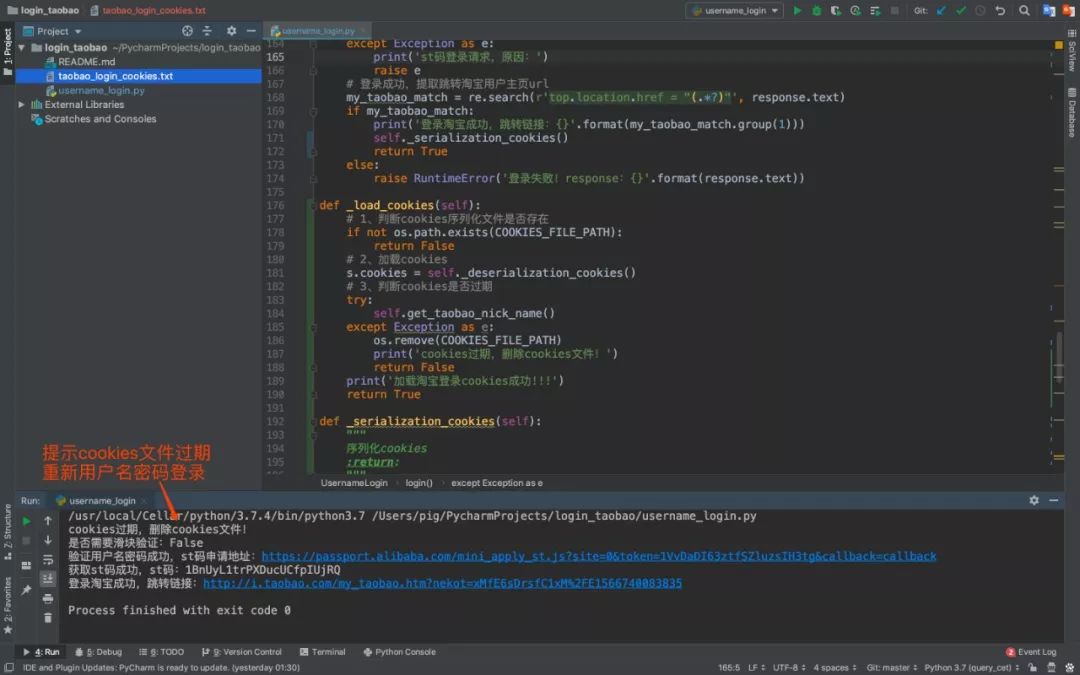
至此所有的功能点 已经自测完毕,这时候就可以提测给测试人员,而测试人员测试通过之后,便可以上预发环境测试,预发测试通过之后才是正式环境!
现在很多公司发布策略都是:小功能都在白天发布了,而比较大的改版还是会安排在深夜,用户少的时候!
总结
今天我们学习了如何保存登录信息,下期我将会教大家如何爬取淘宝商品信息并做数据分析,还是挺有意思的,期待吧!
看到很多同学会在学习群里交流一些以前写的案例,感觉自己做的这些教程有意义,看到大家在学习,我心里超开心。
源码:https://github.com/pig6/login_taobao
以上所述是小编给大家介绍的使用Python 自动登录淘宝并保存登录信息的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

Python使用Scrapy保存控制台信息到文本解析
在Windows平台下,如果想运行爬虫的话,就需要在cmd中输入: scrapy crawl spider_name 这时,爬虫就能启动,并在控制台(cmd)中打印一些信息,如下图所示: 但是,cmd中默认只能显示几屏的信息,其他的信息就无法看到. 如果我们想查看爬虫在运行过程中的调试信息或错误信息的话,会很不方便. 此时,我们就可以将控制台的信息写入的一个文本文件中去,方便我们查看. 命令如下: D:\>scrapy crawl spder_name -s LOG_FILE=scrapy.lo
-
Python抓取聚划算商品分析页面获取商品信息并以XML格式保存到本地
本文实例为大家分享了Android九宫格图片展示的具体代码,供大家参考,具体内容如下 #!/user/bin/python # -*- coding: gbk -*- #Spider.py import urllib2 import httplib import StringIO import gzip import re import chardet import sys import os import datetime from xml.dom.minidom import Documen
-
python实现二维码扫码自动登录淘宝
一个小项目自动登录淘宝联盟抓取数据,由于之前在Github上看过类似用Python写的代码因此选择用Python来写,第一次用Python正式写程序还是被其"简单"所震撼,当然用的时候还是对其(2.7版)编码.迁移环境等问题所困扰,还好后来都解决了. 言归正传,抓取淘宝联盟的数据首先要解决的就是登录的问题,之前一般会碰到验证码的困扰,现在支持二维码扫码登录反而简单了,以下是登录的Python代码,主要是获取二维码打印,然后不断的检查扫码状态,如果过期了重新请求二维码(主要看逻辑,由于有
-
Python3爬虫学习之将爬取的信息保存到本地的方法详解
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法.分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于我们对数据的分析利用,也不利于保存,所以现在就来看一下如何将爬取的数据存储到本地硬盘. 1 对.txt文件的操作 读写文件是最常见的操作之一,python3 内置了读写文件的函数:open open(file, mode='r', buffering=-1, encoding=None, errors=None,
-
Python 自动登录淘宝并保存登录信息的方法
前段时间时间为大家讲解了如何使用requests库模拟登录淘宝,而今天我们将对该功能进行丰富.所以我们把之前的那个版本定为1.0,而今天修改的版本定为2.0.版本的迭代意味着功能的升级,那今天的2.0版本较之前的1.0版本有哪些改进呢?我们一起来看看! 1.0版本实现步骤 我们先来回顾一下模拟登录淘宝的步骤吧,我们还是先看看淘宝登录的详细时序图: 这是淘宝网登录的一个请求流程,而我们模拟登录也是根据这样的一个流程.但是在代码模拟登录的时候就不会分的这么细,我们根据封装的思想将整个登录流程封装在四
-
Python抓取淘宝下拉框关键词的方法
本文实例讲述了Python抓取淘宝下拉框关键词的方法.分享给大家供大家参考.具体如下: import urllib2,re for key in open('key.txt'): do = "http://suggest.taobao.com/sug?code=utf-8&q=%s" % key.rstrip() _re = re.findall('\[\"(.*?)\",\".*?\"\]',urllib2.urlopen(do).re
-
详解如何用Python模拟登录淘宝
目录 一.淘宝登录流程 二.模拟登录实现 1.判断是否需要验证码 2.验证用户名密码 3.申请st码 4.使用st码登录 5.获取淘宝昵称 三.总结 1.代码结构 2.存在问题 看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy.pyppeteer.selenium等库来模拟登录,但是目前我们还没有讲到这些库,只讲了requests库,那我们今天就来使用requests库模拟登录淘宝! 讲模拟登录淘宝之前,我们来回顾一下之前用requests库模拟登录豆瓣和新浪微博的过程:这一类模拟
-
python使用sessions模拟登录淘宝的方式
之前想爬取一些淘宝的数据,后来发现需要登录,找了很多的资料,有个使用request的sessions加上cookie来登录的,cookie的获取在登录后使用开发者工具可以找到.不过这个登录后获得的网页的代码是静态的,获取动态网页还得另寻他法,一般需要的数据可以在网页的源码中得到,但是你知道的,有些动态加载的就不是那么简单了,而且我发现这样获得的源码中,有些想要获取的数据的格式是经过改动的,比如我要某个商品的具体链接,发现并不能直接使用. 总体而言,这是一次失败的尝试,不过倒是了解到使用sessi
-
selenium跳过webdriver检测并模拟登录淘宝
简介 模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网站的升级,采取该策略比较难实现了.因为你使用get/post方式进行爬取数据,会提示需要登录,而登录又是一大难题,需要滑动验证码验证.当你想使用IP代理池进行跳过检验时,发现登录时需要手机短信验证码验证,由此可以知道旧的全自动爬取数据对于大型网站比较困难了. selenium是一款优秀的WEB自动化测试工具,所以现在采用selenium进行半自动化爬取数据,支持模
-
Python 脚本实现淘宝准点秒杀功能
准备软件 下载地址 : https://download.csdn.net/download/tangcv/11968538 pycharm文件太大,不好上传 ,直接去官网下载:https://www.jetbrains.com/pycharm/download/#section=windows 配置环境 1.安装python 双击 然后跟着感觉走, 创建一个专门的文件夹用来放python环境 安装好 2..安装pycharm 1.首先去Pycharm官网,或者直接输入网址:http://www
-
用Python selenium实现淘宝抢单机器人
一.痛点 各大电商在一些特定的日子都会开启促销活动,如618.双十一等,有时还得盯着时间抢限量发售的商品,但你的成功率高吗?是否经常会遇到App一直加载,刷新后发现商品被一扫而光了?事实是,很多和你竞争抢购商品的对手比你的手更快更准,因为他们很多都是能精准执行命令的机器人. 气不气?没关系这篇文章将手把手教你零基础建设一个自己的机器人,帮你在设定好的时间自动下单,再也不用为抢不到心爱的宝贝烦恼了! 二.准备工作 在建设机器人之前,请确保你准备好了如下工具: 一台电脑:不需要多快多新,能用就行 C
-
Python 爬取淘宝商品信息栏目的实现
一.相关知识点 1.1.Selenium Selenium是一个强大的开源Web功能测试工具系列,可进行读入测试套件.执行测试和记录测试结果,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等操作,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件. 1.2.ActionChains Actionchains是selenium里面专门处理鼠标相关的操作如:鼠标移动,鼠标按钮操作,按键和
-
Python使用Selenium爬取淘宝异步加载的数据方法
淘宝的页面很复杂,如果使用分析ajax或者js的方式,很麻烦 抓取淘宝'美食'上面的所有食品信息 spider.py #encoding:utf8 import re from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui