Python爬虫实战JS逆向AES逆向加密爬取
目录
- 爬取目标
- 工具使用
- 项目思路解析
- 简易源码分享
爬取目标
网址:监管平台

工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,AES,json
涉及AES对称加密问题 需要 安装node.js环境
使用npm install 安装 crypto-js
项目思路解析
确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的?

突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第一个页面, 我真是太聪明了
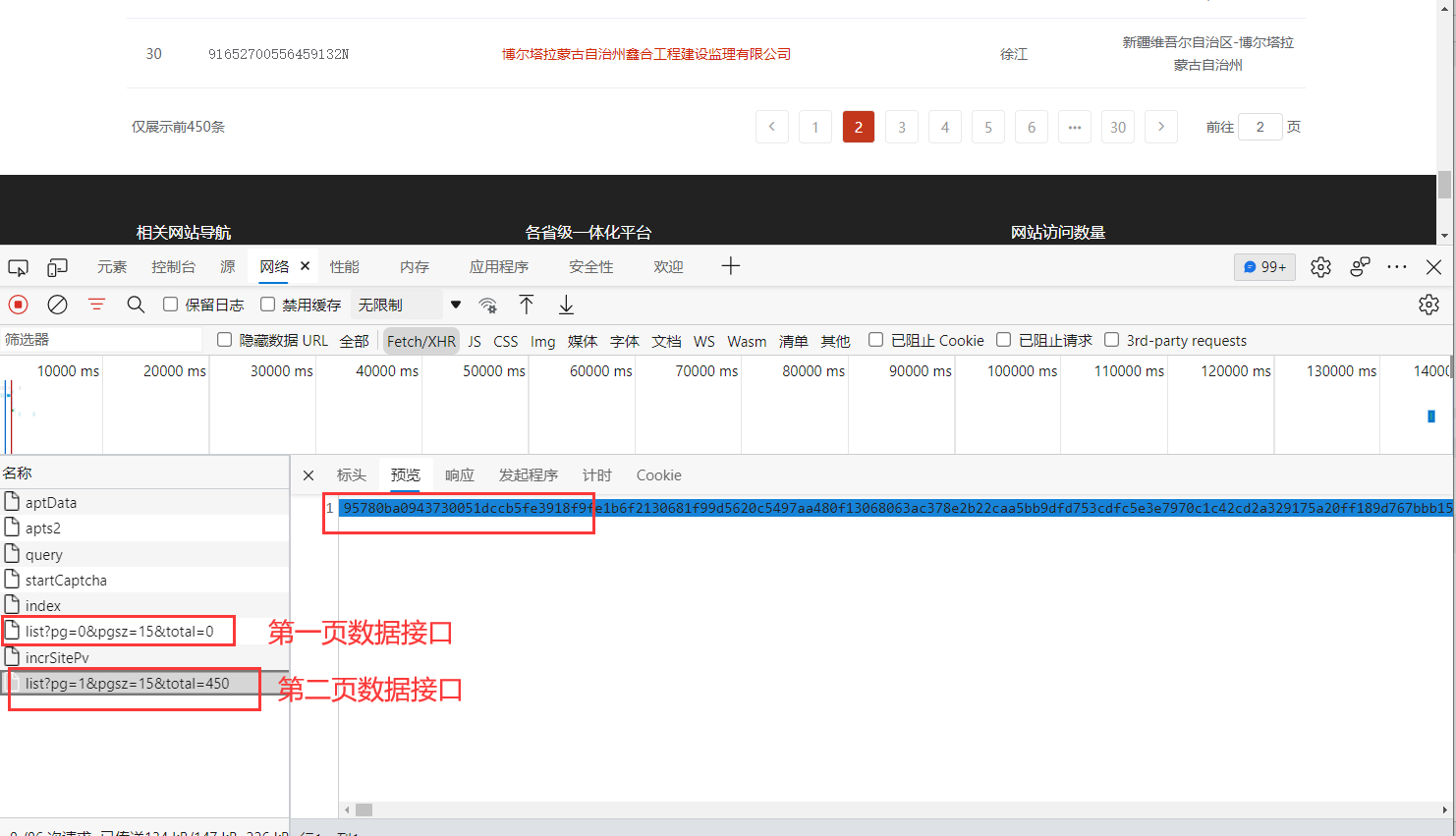
数据找到了 现在开始寻找加密 但是突然发现没有 加密的关键字? 那我们通过url 下手试试 在All里面全局 搜索 query/comp/list(url后面的参数)

找到这个接口 鼠标右键 可以在源代码查看他
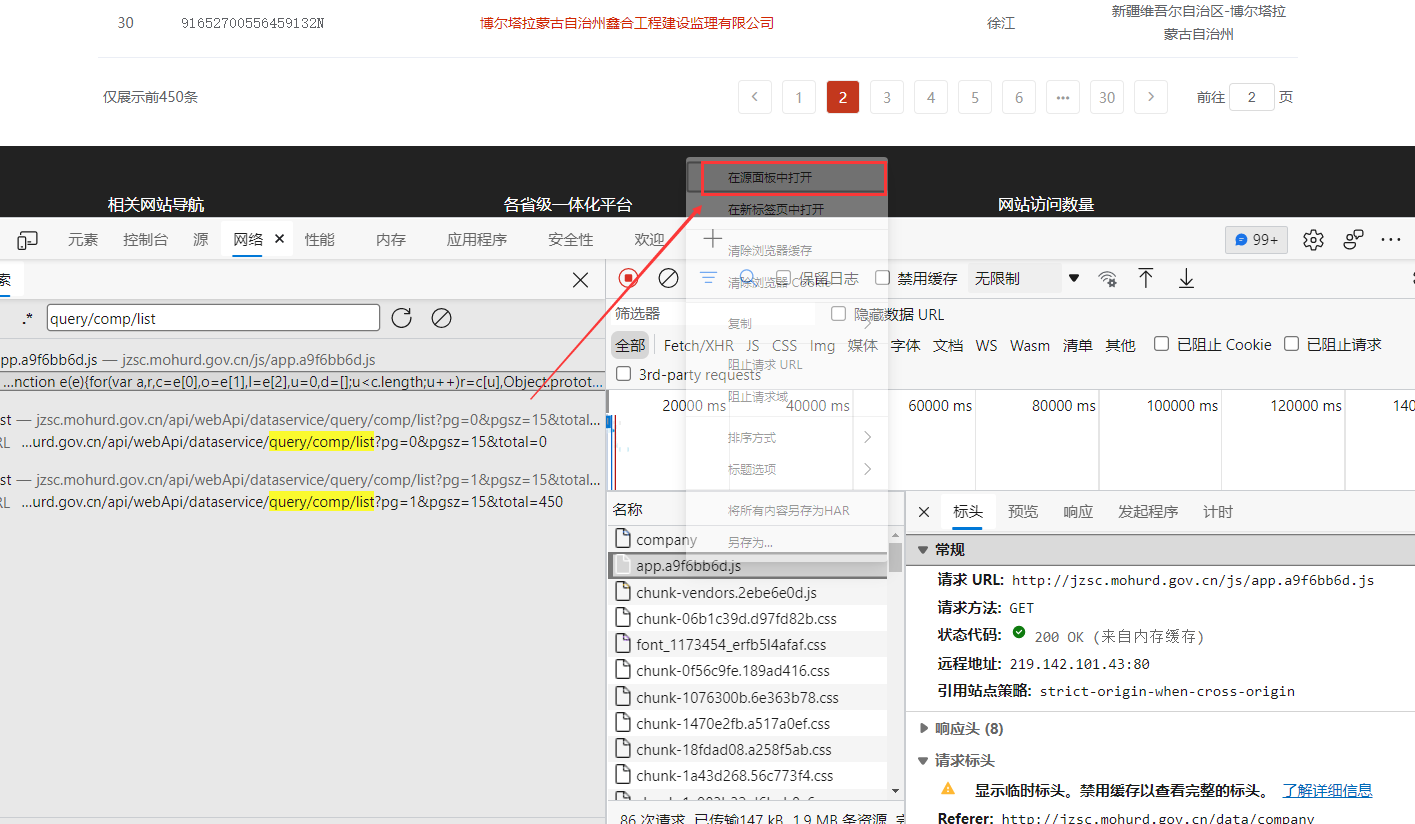

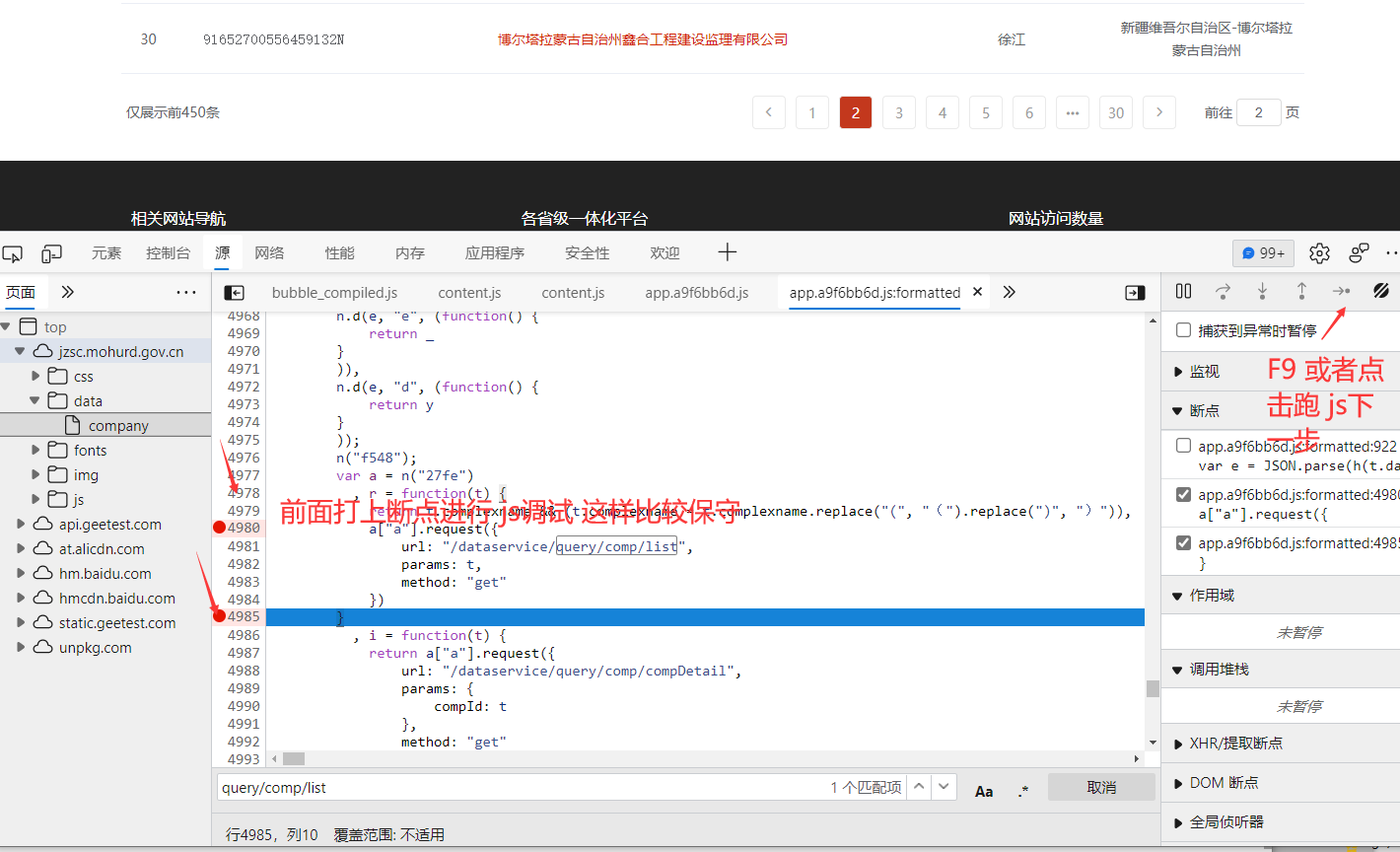
慢慢调试 中间调试太多了 我就不一一截图出来了 跑到这里 发现data 里面的参数 和我们看到的加密一致
h(t.data) 加密位置

进去h里面 (鼠标光标放到 h上面 会显示他的 js地址 如果没有显示 就是证明你还没有执行到这里 需要在前面打上断点 刷新页面调试)

发现这个采用AES加密算法 使用模型CBC模式 采用填充方式为 Pkcs7
AES.decrypt() # 参数说明 秘钥 模式 偏移值
f = 'jo8j9wGw%6HbxfFn' # 秘钥
m = '0123456789ABCDEF' # 偏移值
证明数据推导正确 在 return r.toString() 打上断点
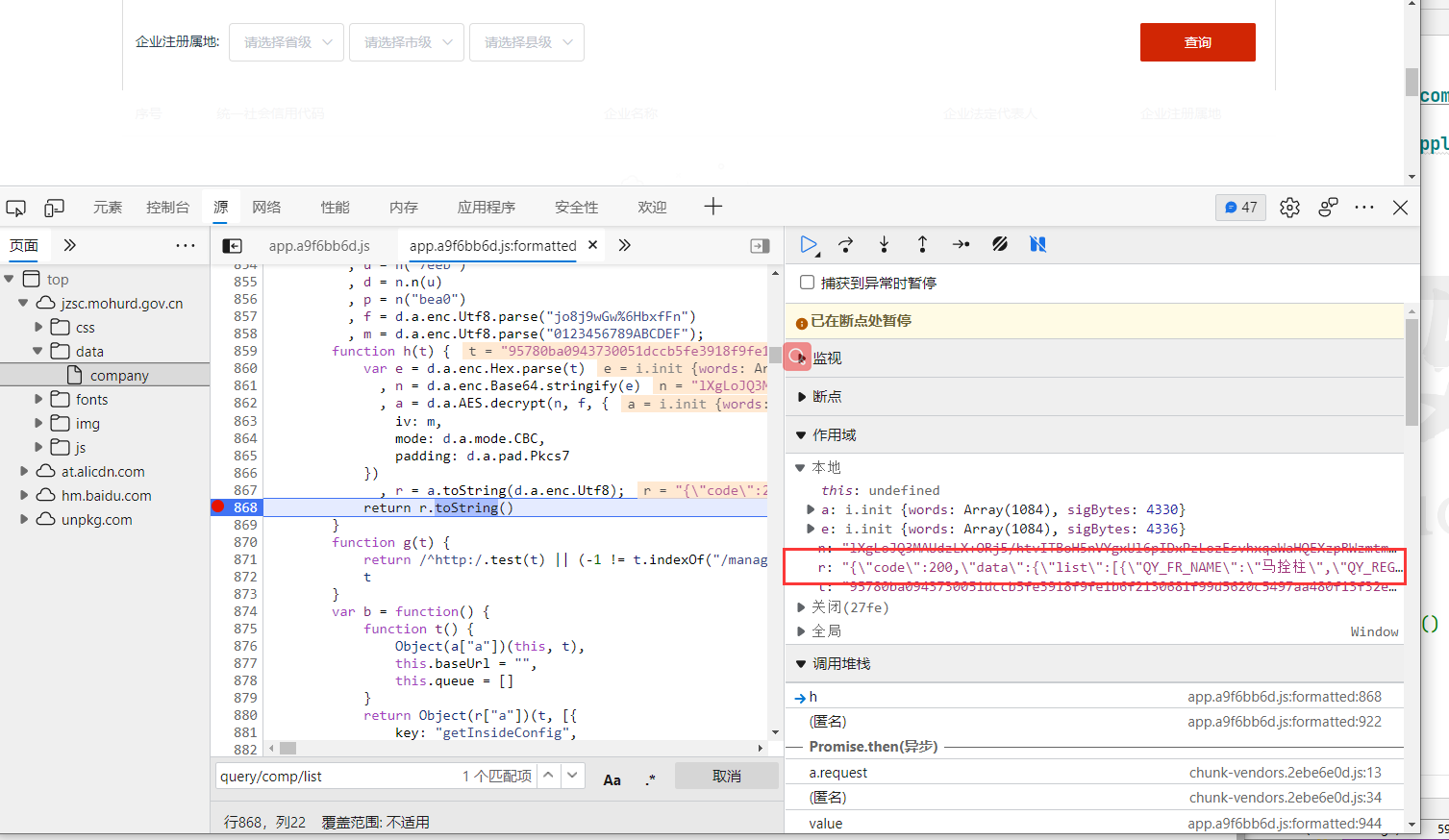
r里面数据正常返回
简易源码分享
import requests
from Crypto.Cipher import AES
import json
url = 'http://jzsc.mohurd.gov.cn/api/webApi/dataservice/query/comp/list?pg=2&pgsz=15&total=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.38'
}
response = requests.get(url, headers=headers).text
f = 'jo8j9wGw%6HbxfFn' # 秘钥
m = '0123456789ABCDEF' # 偏移值
# 转码 utf-8? 字节 16进制
m = bytes(m, encoding='utf-8')
f = bytes(f, encoding='utf-8')
# 创建一个AES算法 秘钥 模式 偏移值
cipher = AES.new(f, AES.MODE_CBC, m)
# 解密
decrypt_content = cipher.decrypt(bytes.fromhex(response))
result = str(decrypt_content, encoding='utf-8')
# OKCS7 填充
length = len(result) # 字符串长度
unpadding = ord(result[length - 1]) # 得到最后一个字符串的ASCII
result = result[0:length - unpadding]
result = json.loads(result)['data']['list'] # dupms json.dumps() dict 格式 json的
# {"键":"值"}
for i in result:
print(i)
以上就是Python爬虫实战JS逆向AES逆向加密爬取的详细内容,更多关于Python爬取JS逆向AES逆向加密的资料请关注我们其它相关文章!
相关推荐
-
使用Python进行AES加密和解密的示例代码
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准.这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用.经过五年的甄选流程,高级加密标准由美国国家标准与技术研究院(NIST)于2001年11月26日发布于FIPS PUB 197,并在2002年5月26日成为有效的标准.2006年,高级加密标准已然成为对称密钥加密中最流行的算法之一.---百度百科 本科的时候弄过DES
-

Python爬虫逆向分析某云音乐加密参数的实例分析
本文转自:https://blog.csdn.net/qq_42730750/article/details/108415551 前言 各大音乐平台是从何时开始收费的这个问题没有追溯过,印象中酷狗在16年就已经开始收费了,貌似当时的收费标准是付费音乐下载一首2元,会员一月8元,可以下载300首.虽然下载收费,但是还可以正常听歌.陆陆续续,各平台不仅收费,而且还更在乎版权问题,因为缺少版权,酷狗上以前收藏的音乐也不能听了,更过分的是,有些歌非VIP会员只能试听60秒(•́へ•́╬). 版权
-
python爬虫的一个常见简单js反爬详解
前言 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成cookie等来操作浏览器这两部分,今天说的是第二种情况. 目标网站 列表页url: http://www.hnrexian.com/archives/category/jk. 正常网站我们请求url会返回给我们网页数据内容等,看看这个网站返回给我们的是什么呢? 我们把相应中返回的js代码格式化一下,方便查看. < script typ
-
Python爬虫实战JS逆向AES逆向加密爬取
目录 爬取目标 工具使用 项目思路解析 简易源码分享 爬取目标 网址:监管平台 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,AES,json 涉及AES对称加密问题 需要 安装node.js环境 使用npm install 安装 crypto-js 项目思路解析 确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的? 突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第
-
Python爬虫实战之网易云音乐加密解析附源码
目录 环境 知识点 第一步 第二步 开始代码 先导入所需模块 请求数据 提取我们真正想要的 音乐的名称 id 导入js文件 保存文件 完整代码 环境 python3.8 pycharm2021.2 知识点 requests >>> pip install requests execjs >>> pip install PyExecJS 第一步 打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id 去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
-
Python Scrapy实战之古诗文网的爬取
目录 需求 1. Scrapy项目创建 2. 全局配置 settings.py 3. 爬虫程序.py 4. 数据结构 items.py 5. 管道 pipelines.py 6. 程序执行 start.py 需求 通过python,Scrapy框架,爬取古诗文网上的诗词数据,具体包括诗词的标题信息,作者,朝代,诗词内容,及译文.爬取过程需要逐页爬取,共4页.第一页的url为(https://www.gushiwen.cn/default_1.aspx). 1. Scrapy项目创建 首先创建Sc
-
python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用xpath提取此标签对象并返回: 调用点击事件,并循环上述过程: 最终效果图: 代码: from selenium import webdriver import time import re class Douyu(object): def __init__(self): # 开始时的url self.start
-
Python爬虫设置Cookie解决网站拦截并爬取蚂蚁短租的问题
我们在编写Python爬虫时,有时会遇到网站拒绝访问等反爬手段,比如这么我们想爬取蚂蚁短租数据,它则会提示"当前访问疑似黑客攻击,已被网站管理员设置为拦截"提示,如下图所示.此时我们需要采用设置Cookie来进行爬取,下面我们进行详细介绍.非常感谢我的学生承峰提供的思想,后浪推前浪啊! 一. 网站分析与爬虫拦截 当我们打开蚂蚁短租搜索贵阳市,反馈如下图所示结果. 我们可以看到短租房信息呈现一定规律分布,如下图所示,这也是我们要爬取的信息. 通过浏览器审查元素,我们可以看到需要爬取每条租
-
python爬虫实战steam加密逆向RSA登录解析
目录 采集目标 工具准备 项目思路解析 采集目标 网址:steam 工具准备 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests 项目思路解析 访问登录页面重登录页面获取登录接口, 先输入错误的账户密码去测试登录接口. 获取到登录的接口地址,请求方法是post请求,找到需要传递的参数,可以看到密码数据是加密的第一个数据是时间戳密码加密字段应该用的base64,rsatimestamp字段目前还不清楚是什么,其他的都是固定数据. 找到pass
-
Python爬虫实战项目掌握酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. 我们在搜索栏上输入我们想听的音乐,小编输入:刺客 是不是看到了一系列音乐,怎样得到这些音乐的一些信息呢?(这里指的音乐信息是指音乐的hash值和音乐的album_id值[这两个参数在获取音乐的下载链接那里会用到],当然还包括音乐的名称[不然怎么区别呢?]). 由于这一系列音乐是动态加载出来的,也就是
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
Python爬虫实战之爬取某宝男装信息
目录 知识点介绍 实现步骤 1. 分析目标网站 2. 获取单个商品界面 3. 获取多个商品界面 4. 获取商品信息 5. 保存到MySQL数据库 完整代码 知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审
-
Python爬虫实战:分析《战狼2》豆瓣影评
刚接触python不久,做一个小项目来练练手.前几天看了<战狼2>,发现它在最新上映的电影里面是排行第一的,如下图所示.准备把豆瓣上对它的影评做一个分析. 目标总览 主要做了三件事: 抓取网页数据 清理数据 用词云进行展示 使用的python版本是3.5. 一.抓取网页数据 第一步要对网页进行访问,python中使用的是urllib库.代码如下: from urllib import request resp = request.urlopen('https://movie.douban.co