MySQL之join查询优化方式
目录
- MySQL join查询优化
- 1. 那什么是驱动表呢?
- 2. 复杂的sql怎么识别驱动表呢?
- 3. 关联查询原理是怎样的?
- 4. 该如如何优化?
- 5. 实例
- MySQL优化(关联查询优化)
- 准备数据
- left join左外连接
- inner join:MySQL会自动根据表中的数据选择驱动表
- 总结
MySQL join查询优化
在日常的开发中,我们经常遇到这样情况:select * from TableA inner join TableB...它响应速度一直很快的,随着数据的增长,突然有一天开始很慢了。那该怎么破?
对,驱动表是突破口,
1. 那什么是驱动表呢?
- 指定了联接条件时,满足查询条件的记录行数少的表为驱动表
- 未指定联接条件时,行数少的表为驱动表(Important!)
如果你搞不清楚该让谁做驱动表、谁 join 谁,就别指定谁 left/right join 谁了,请交给 MySQL优化器 运行时决定吧。
2. 复杂的sql怎么识别驱动表呢?
按经验谈,使用EXPLAIN, 第一行出现的表就是驱动表。
3. 关联查询原理是怎样的?
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
//例: user表10000条数据,class表20条数据 select * from user u left join class c u.userid=c.userid
上面sql的后果就是需要用user表循环10000次才能查询出来,而如果用class表驱动user表则只需要循环20次就能查询出来。
4. 该如如何优化?
优化的目标是尽可能减少JOIN中Nested Loop的循环次数,以此保证:永远用小结果集驱动大结果集。
排序的字段也有影响,有条原则:对驱动表可以直接排序,对非驱动表(的字段排序)需要对循环查询的合并结果(临时表)进行排序!
5. 实例
explain select * from user u left join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id WHERE 1=1 ORDER BY u.create_time DESC limit 0,10
够复杂吧。假如,user表有千万级记录,class表要少得多,从执行计划的得知驱动表(数据到千万级)。由于动用了“LEFT JOIN”,所以相当于已经指定了驱动表。
如何优化?
//优化第一步:LEFT JOIN改为JOIN,对,直接 join! explain select * from user u join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id WHERE 1=1 ORDER BY u.create_time DESC limit 0,10 //优化第二步:从上面执行计划得知, 有Using temporary(临时表);Using filesort,解决方法是调整排序字段(借助前面讲过排序的原则) explain select * from user u join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id WHERE 1=1 ORDER BY c.id DESC limit 0,10
总之,sql优化中explain工具是非常重要的武器。
MySQL优化(关联查询优化)
准备数据
#分类 CREATE TABLE IF NOT EXISTS `class` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`) ); #图书 CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`bookid`) ); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
left join左外连接
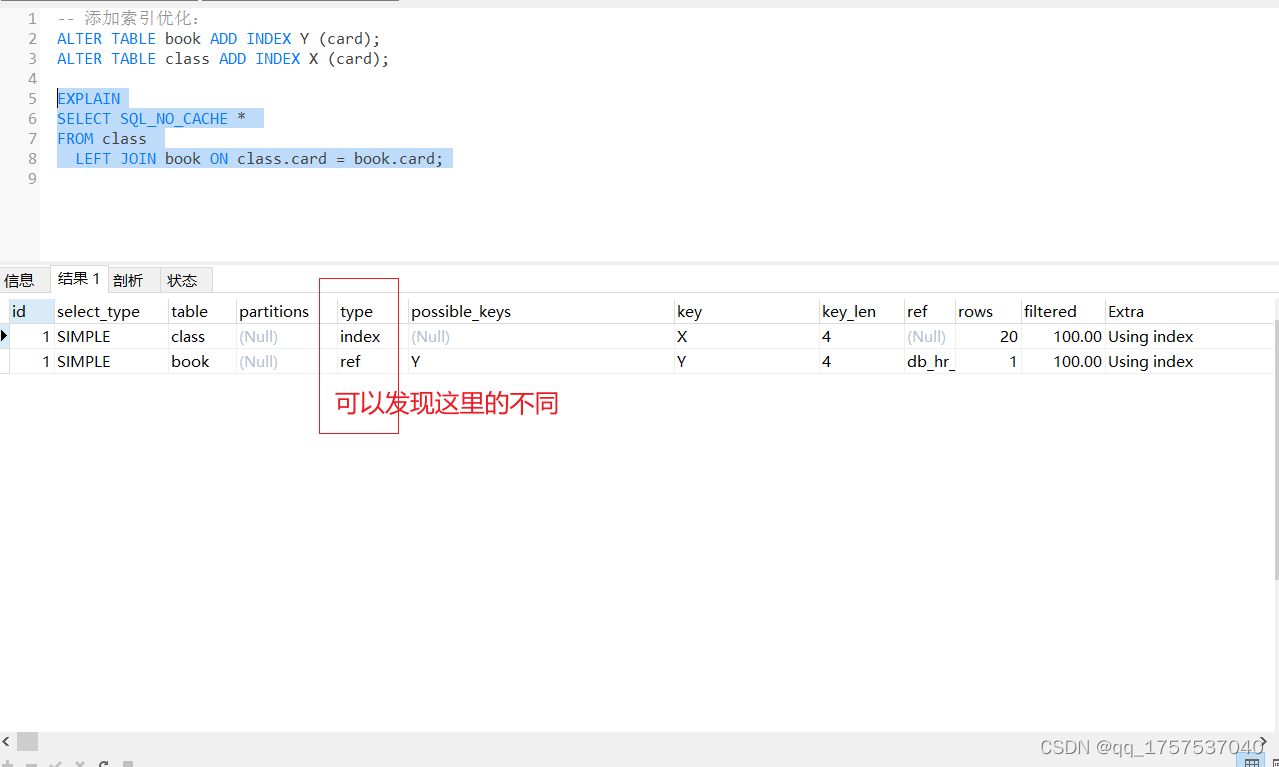
看这个分析结果发现:在 class 表上添加的索引起的作用不大。
结论:
- **小表驱动大表**
- - 小表:相对来说记录较少的表
- - 大表:相对来说记录较多的表
- 驱动方式识别
- left join:左边驱动右边(此时把小表放在左边)
- right join:右边驱动左边(此时把小表放在右边)
- 加索引的方式:通常建议在大表(被驱动)的表加索引,效率提升更明显。
- 原因:
- 原因1:被驱动表加了索引之后,收益更大。从 ALL -> ref
- 原因2:外连接首先读取驱动表的全部数据,被驱动只读取满足连接条件的数据。
inner join:MySQL会自动根据表中的数据选择驱动表
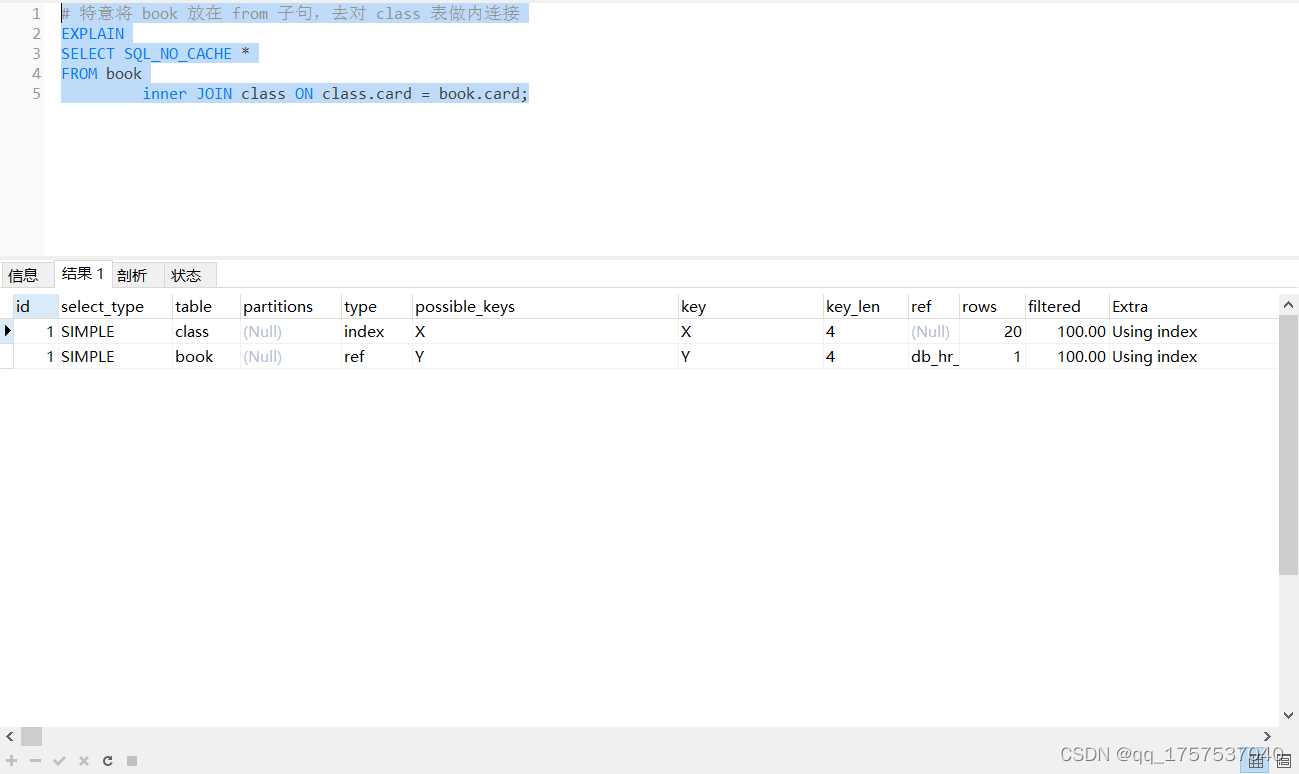
小结:
- 保证被驱动表的 join 字段被索引。join 字段就是作为连接条件的字段。
- left join 时,选择小表作为驱动表(放左边),大表作为被驱动表(放右边)
- inner join 时,mysql 会自动将小结果集的表选为驱动表。
- 子查询尽量不要放在被驱动表,衍生表建不了索引
- 能够直接多表关联的尽量直接关联,不用子查询
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

MySQL关联查询优化实现方法详解
目录 左外连接 内连接INNER JOIN 我们准备如下两个表,并插入数据. #分类 CREATE TABLE IF NOT EXISTS `type` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`) ); #图书 CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NO
-
详解Mysql多表联合查询效率分析及优化
1. 多表连接类型 1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: SELECT * FROM table1 CROSS JOIN table2 SELECT * FROM table1 JOIN table2 SELECT * FROM table1,table2 由于其返回的结果为被连接的两个数据表的乘积,因此当有WHERE, ON或USING条件的时候一般不建议使用,因为当数据表项目太多的时候,会非常慢.一般使用LE
-
MySQL优化常用的19种有效方法(推荐!)
目录 1.EXPLAIN 2.SQL语句中IN包含的值不应过多 3.SELECT语句务必指明字段名称 4.当只需要一条数据的时候,使用limit1 5.如果排序字段没有用到索引,就尽量少排序 6.如果限制条件中其他字段没有索引,尽量少用or 7.尽量用unionall代替union 8.不使用ORDERBYRAND() 9.区分in和exists.notin和notexists 10.使用合理的分页方式以提高分页的效率 11.分段查询 12.避免在where子句中对字段进行null值判断 13.
-
MySQL 百万级数据的4种查询优化方式
一.limit越往后越慢的原因 当我们使用limit来对数据进行分页操作的时,会发现:查看前几页的时候,发现速度非常快,比如 limit 200,25,瞬间就出来了.但是越往后,速度就越慢,特别是百万条之后,卡到不行,那这个是什么原理呢.先看一下我们翻页翻到后面时,查询的sql是怎样的: select * from t_name where c_name1='xxx' order by c_name2 limit 2000000,25; 这种查询的慢,其实是因为limit后面的偏移量太大导致的.
-
Mysql中常用的几种join连接方式总结
目录 1.内连接 2.左连接 3.右连接 4.查询左表独有数据 5.查询右表独有数据 6.全连接 7.查询左右表各自的独有的数据 总结 1.首先准备两张表 部门表: 员工表: 以下我们就对这两张表进行不同的连接操作 1.内连接 作用: 查询两张表的共有部分 语句:Select from tableA A Inner join tableB B on A.Key = B.Key 示例:SELECT * from employee e INNER JOIN department d on e.dep
-
详解Mysql两表 join 查询方式
目录 一.SQL基本语法格式 二.3种join方式 1. left join(左连接) 2. right join(右连接) 3. inner join(内连接) 4. 在理解上面的三种join下,查询(A - A∩B) 5. 查询 ( B - A∩B ) 6. 查询(A∪B - A∩B) 7. 查询 AUB 一.SQL基本语法格式 SELECT DISTINCT < select_list > FROM < left_table > < join_type > JO
-
mysql大数据查询优化经验分享(推荐)
正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒. 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化. 实验环境:MacBook Pro MJLQ2CH/A,mysql5.7,数据量:212万+ ONE: select * from article INNER JOIN ( SELECT id FROM article WHERE length(content_url) > 0 an
-
Mysql Limit 分页查询优化详解
select * from table LIMIT 5,10; #返回第6-15行数据 select * from table LIMIT 5; #返回前5行 select * from table LIMIT 0,5; #返回前5行 我们来写分页 物理分页 select * from table LIMIT (当前页-1)*每页显示条数,每页显示条数; MySQL之Limit简单优化.md 同样是取90000条后100条记录,传统方式还是改造方式? 传统方式是先取了前90001条记录,取其中最
-
MySQL的join buffer原理
一.MySQL的join buffer 在MySQL对于join操作的处理过程中,join buffer是一个重要的概念,也是MySQL对于table join的一个重要的优化手段.虽然这个概念实现并不复杂,但是这个是实现MySQL join连接优化的一个重要方法,在"暴力"连接的时候可以极大提高join查询的效率. 关于这个概念的权威说明当然是来自MySQL文档中对于这个概念的说明,说明的文字不多,但是言简意赅,说明了这个优化的主要实现思想: Assume you have the
-
MySQL七大JOIN的具体使用
目录 简介 练习 简介 A的独有+AB的公有 B的独有+AB的公有 AB的公有 A的独有 B的独有 A的独有+B的独有+AB的公有 A的独有+B的独有 练习 建表 部门表 DROP TABLE IF EXISTS `dept`; CREATE TABLE `dept` ( `dept_id` int(11) NOT NULL AUTO_INCREMENT, `dept_name` varchar(30) DEFAULT NULL, `dept_number` int(11) DEFAULT NU
-
MySql中JOIN的用法示例详解
目录 笛卡尔积:CROSS JOIN 内连接:INNER JOIN 左连接:LEFT JOIN 右连接:RIGHT JOIN 外连接:OUTER JOIN USING子句 自然连接:NATURE JOIN 上次面试被问到JOIN,自己都已经忘了课堂上讲的笛卡尔积那些就是JOIN,最近重新复习了一遍 JOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接. 先创建两个表,下面用于示例 CREATE TABLE t_blog( id INT PRIM
-
MySQL中join查询的深入探究
目录 前引 索引对 join 查询的影响 数据准备 有索引查询过程 无索引查询过程 了解 Block Nested-Loop Join Block Nested-Loop Join查询过程 Join_buffer 如何正确的写出 join 查询 驱动表的选择 什么是小表 结论: 前引 相信大家 MySQL 都用了很久了,各种 join 查询天天都在写,但是 join 查询到底是怎么查的,怎么写才是最正确的,今天我就和大家一起学习探讨一下 索引对 join 查询的影响 数据准备 假设有两张表 t1
-
MySQL中join语句怎么优化
目录 Simple Nested-Loop Join Block Nested-Loop Join Index Nested-Loop Join 如何选择驱动表? Simple Nested-Loop Join 我们来看一下当进行 join 操作时,mysql是如何工作的.常见的 join 方式有哪些? 如图,当我们进行连接操作时,左边的表是驱动表,右边的表是被驱动表 Simple Nested-Loop Join 这种连接操作是从驱动表中取出一条记录然后逐条匹配被驱动表的记录,如果条件匹配则将