Python中seaborn库之countplot的数据可视化使用
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效。
seaborn官方文档见链接:http://seaborn.pydata.org/api.html
countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数。接下来,对seaborn中的countplot方法进行详细的一个讲解,希望可以帮助到刚入门的同行。
导入seaborn库
import seaborn as sns
使用countplot
sns.countplot()
countplot方法中必须要x或者y参数,不然就报错。
官方给出的countplot方法及参数:
sns.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
下面讲解countplot方法中的每一个参数。以泰坦尼克号为例。
原始数据如下:
sns.set(style='darkgrid')
titanic = sns.load_dataset('titanic')
titanic.head()

x, y, hue : names of variables in ``data`` or vector data, optional. Inputs for plotting long-form data. See examples for interpretation.
第一种方式
x: x轴上的条形图,以x标签划分统计个数
y: y轴上的条形图,以y标签划分统计个数
hue: 在x或y标签划分的同时,再以hue标签划分统计个数
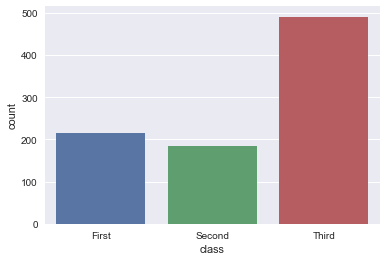
sns.countplot(x="class", data=titanic)
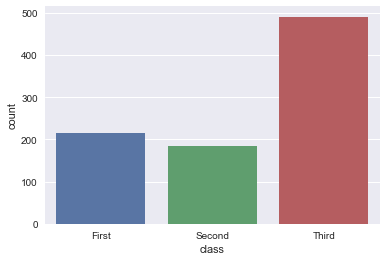
sns.countplot(y="class", data=titanic)
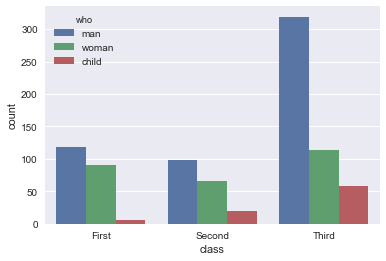
sns.countplot(x="class", hue="who", data=titanic)
第二种方法
x: x轴上的条形图,直接为series数据
y: y轴上的条形图,直接为series数据
sns.countplot(x=titanic['class'])
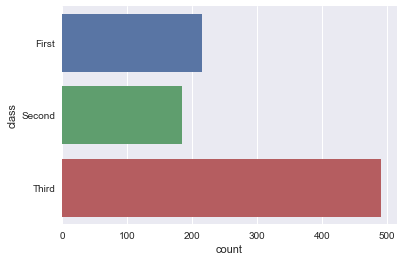
sns.countplot(y=titanic['class'])

data : DataFrame, array, or list of arrays, optional. Dataset for plotting.
If ``x`` and ``y`` are absent, this is interpreted as wide-form. Otherwise it is expected to be long-form.
data: DataFrame或array或array列表,用于绘图的数据集,x或y缺失时,data参数为数据集,同时x或y不可缺少,必须要有其中一个。
sns.countplot(x='class', data=titanic)
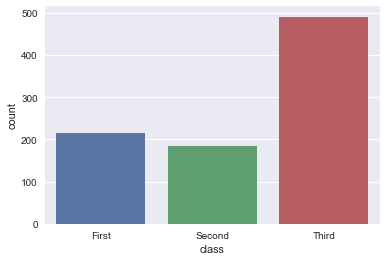
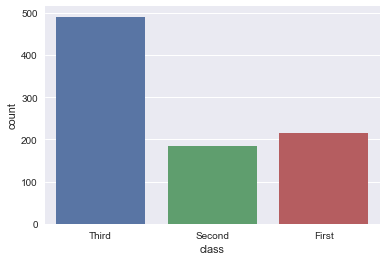
order, hue_order : lists of strings, optional.Order to plot the categorical levels in, otherwise the levels are inferred from the data objects.
order, hue_order分别是对x或y的字段排序,hue的字段排序。排序的方式为列表。
sns.countplot(x='class', data=titanic, order=['Third', 'Second', 'First'])
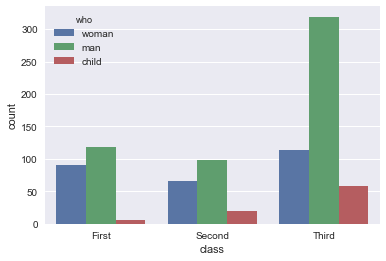
sns.countplot(x='class', hue='who', data=titanic, hue_order=['woman', 'man', 'child'])
orient : "v" | "h", optional
Orientation of the plot (vertical or horizontal). This is usually
inferred from the dtype of the input variables, but can be used to
specify when the "categorical" variable is a numeric or when plotting
wide-form data.
强制定向,v:竖直方向;h:水平方向,具体实例未知。
color : matplotlib color, optional
Color for all of the elements, or seed for a gradient palette.
palette : palette name, list, or dict, optional.Colors to use for the different levels of the ``hue`` variable.
Should be something that can be interpreted by :func:`color_palette`, or a dictionary mapping hue levels to matplotlib colors.
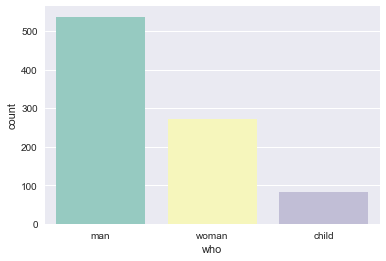
palette:使用不同的调色板
sns.countplot(x="who", data=titanic, palette="Set3")
ax : matplotlib Axes, optional
Axes object to draw the plot onto, otherwise uses the current Axes.
ax用来指定坐标系。
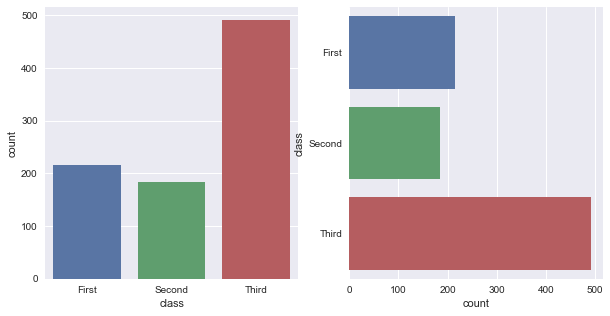
fig, ax = plt.subplots(1, 2, figsize=(10, 5)) sns.countplot(x='class', data=titanic, ax=ax[0]) sns.countplot(y='class', data=titanic, ax=ax[1])
到此这篇关于Python中seaborn库之countplot的数据可视化使用的文章就介绍到这了,更多相关Python seaborn库countplot内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中seaborn包常用图形使用详解
seaborn包是对matplotlib的增强版,需要安装matplotlib后才能使用. 所有图形都用plt.show()来显示出来,也可以使用下面的创建画布 fig,ax=plt.subplots() #一个画布 fig,(ax1,ax2) = plt.subplots( ncols=2) #两个画布 1)单个特征统计图countplot sn.countplot(train.mnth)#离散型特征可使用,描述样本点出现的次数. 2)单个特征统计图distplot sn.distplot(t
-

python可视化分析的实现(matplotlib、seaborn、ggplot2)
一.matplotlib库 1.基本绘图命令 import matplotlib.pyplot as plt plt.figure(figsize=(5,4)) #设置图形大小 plt.rcParams['axes.unicode_minus']=False #正常显示负号 plt.rcParams['font.sans-self']=['Kai Ti'] #设置字体,这里是楷体,SimHei表示黑体 #基本统计图 plt.bar(x,y);plt.pie(y,labels=x);plt.plo
-
Python数据可视化库seaborn的使用总结
seaborn是python中的一个非常强大的数据可视化库,它集成了matplotlib,下图为seaborn的官网,如果遇到疑惑的地方可以到官网查看.http://seaborn.pydata.org/ 从官网的主页我们就可以看出,seaborn在数据可视化上真的非常强大. 1.首先我们还是需要先引入库,不过这次要用到的python库比较多. import numpy as np import pandas as pd import matplotlib as mpl import matpl
-
Python-Seaborn热图绘制的实现方法
制图环境: pycharm python-3.6 Seaborn-0.8 热图 import numpy as np import seaborn as sns import matplotlib.pyplot as plt sns.set() np.random.seed(0) uniform_data = np.random.rand(10, 12) ax = sns.heatmap(uniform_data) plt.show() # 改变颜色映射的值范围 ax = sns.heatmap
-
python seaborn heatmap可视化相关性矩阵实例
方法 import pandas as pd import numpy as np import seaborn as sns df = pd.DataFrame(np.random.randn(50).reshape(10,5)) corr = df.corr() sns.heatmap(corr, cmap='Blues', annot=True) 将矩阵型简化为对角矩阵型: mask = np.zeros_like(corr) mask[np.tril_indices_from(mask)
-
Python中seaborn库之countplot的数据可视化使用
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数.接下来,对seaborn中的countplot方法进行详细的一个讲解,希望可以帮助到刚入门的同行. 导入seaborn库 import seaborn as sns 使用countplot sns.countplot() cou
-
python中requests库session对象的妙用详解
在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有时候需要保持一些共用的数据,例如cookies信息. 妙用1 requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies. 举个栗子,跨请求保持cookies,在命令行上输入下面命令: # 创建一个session对象 s = requests.Session() # 用session对象发出get请求,设置cookies s.get('http://ht
-
Python 中Pickle库的使用详解
在"通过简单示例来理解什么是机器学习"这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 那么为什么需要序列化和反序列化这一操作呢? 1.便于存储.序列化过程将文本信息转变为二进制数据流.这样就信息就容易存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据,然后再将其反序列化便可以得到原始的数据.在Python程序运行中得到了一些字符串.列表.字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据.python模块大全中的Pickle模块就派
-
python中pandas库中DataFrame对行和列的操作使用方法示例
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
Python中Selenium库使用教程详解
selenium介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 中文参考文档 官网 环境安装 下载安装selenium pip install selenium -i https://mirrors.aliyun.com/pypi/simple/ 谷歌浏览器驱动程序下载地址:
-
详解Python中第三方库Faker
项目开发初期,为了测试方便,我们总要造不少假数据到系统中,尽量模拟真实环境. 比如要创建一批用户名,创建一段文本,电话号码,街道地址.IP地址等等. 平时我们基本是键盘一顿乱敲,随便造个什么字符串出来,当然谁也不认识谁. 现在你不要这样做了,用Faker就能满足你的一切需求. 1. 安装 pip install Faker 2. 简单使用 >>> from faker import Faker >>> fake = Faker(locale='zh_CN') >&
-
python中xlutils库用法浅析
不少小伙伴认为,直接去操作excel,比我们利用各种代码数据去处理,直接又简单,不那么花里胡哨,但是在代码上,处理数据,直接的软件操作是行不通的,需要我们去利用代码去处理,其实解决麻烦的办法非常简单,只需要我们调用专业的处理数据的模块,就可以轻松处理了,比如excel处理中的xlutils库,下面详细为大家介绍使用. 简单介绍: 最常见的使用在excel中的复制. 安装方式: pip install xlutils 注意点: 虽然可以进行excel的复制.但是只能提供写操作,不能够复制格式. 使
-
python用faker库批量生成假数据
楔子 我们平时在做测试的时候,经常会使用一些假数据,而Python中有一个包叫faker(不是打LOL的那个),专门用来生成假数据,并且生成的假数据非常逼真,下面我们就来看一下. faker使用方法 基本使用 faker使用起来非常简单,我们看一下就知道了. from faker import Faker # 导入Faker这个类, 实例化即可 fake = Faker(locale="zh_CN") # 然后调用里面的方法即可生成相应的假数据 print(fake.name()) #
-
python中requests库+xpath+lxml简单使用
python的requests 它是python的一个第三方库,处理URL比urllib这个库要方便的多,并且功能也很丰富. [可以先看4,5表格形式的说明,再看前面的] 安装 直接用pip安装,anconda是自带这个库的. pip install requests 简单使用 requests的文档 1.简单访问一个url: import requests url='http://www.baidu.com' res = requests.get(url) res.text res.statu