Python3爬虫中Selenium的用法详解
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效。本节中,就让我们来感受一下它的强大之处吧。
1. 准备工作
本节以Chrome为例来讲解Selenium的用法。在开始之前,请确保已经正确安装好了Chrome浏览器并配置好了ChromeDriver。另外,还需要正确安装好Python的Selenium库,详细的安装和配置过程可以参考第1章。
2. 基本使用
准备工作做好之后,首先来大体看一下Selenium有一些怎样的功能。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
运行代码后发现,会自动弹出一个Chrome浏览器。浏览器首先会跳转到百度,然后在搜索框中输入Python,接着跳转到搜索结果页,如图7-1所示。
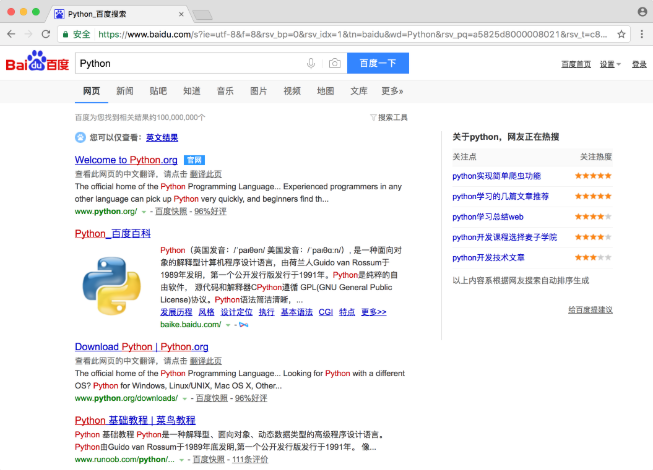
图7-1 运行结果
搜索结果加载出来后,控制台分别会输出当前的URL、当前的Cookies和网页源代码:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=Python&rsv_pq=c94d0df9000a72d0&rsv_t=
07099xvun1ZmC0bf6eQvygJ43IUTTUOl5FCJVPgwG2YREs70GplJjH2F%2BCQ&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=
0&inputT=87&rsv_sug4=87
[{'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598', 'domain': '.baidu.com', 'path': '/', 'httpOnly':
False, 'name': 'BDORZ', 'expiry': 1491688071.707553}, {'secure': False, 'value': '22473_1441_21084_17001',
'domain': '.baidu.com', 'path': '/', 'httpOnly': False, 'name': 'H_PS_PSSID'}, {'secure': False, 'value':
'12883875381399993259_00_0_I_R_2_0303_C02F_N_I_I_0', 'domain': '.www.baidu.com', 'path': '/', 'httpOnly': False,
'name': '__bsi', 'expiry': 1491601676.69722}]
<!DOCTYPE html><!--STATUS OK-->...</html>
源代码过长,在此省略。可以看到,我们得到的当前URL、Cookies和源代码都是浏览器中的真实内容。
所以说,如果用Selenium来驱动浏览器加载网页的话,就可以直接拿到JavaScript渲染的结果了,不用担心使用的是什么加密系统。
下面来详细了解一下Selenium的用法。
3. 声明浏览器对象
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
此外,我们可以用如下方式初始化:
from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.Edge() browser = webdriver.PhantomJS() browser = webdriver.Safari()
这样就完成了浏览器对象的初始化并将其赋值为browser对象。接下来,我们要做的就是调用browser对象,让其执行各个动作以模拟浏览器操作。
4. 访问页面
我们可以用get()方法来请求网页,参数传入链接URL即可。比如,这里用get()方法访问淘宝,然后打印出源代码,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
运行后发现,弹出了Chrome浏览器并且自动访问了淘宝,然后控制台输出了淘宝页面的源代码,随后浏览器关闭。
通过这几行简单的代码,我们可以实现浏览器的驱动并获取网页源码,非常便捷。
5. 查找节点
Selenium可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而Selenium提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
单个节点
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码,如图7-2所示。
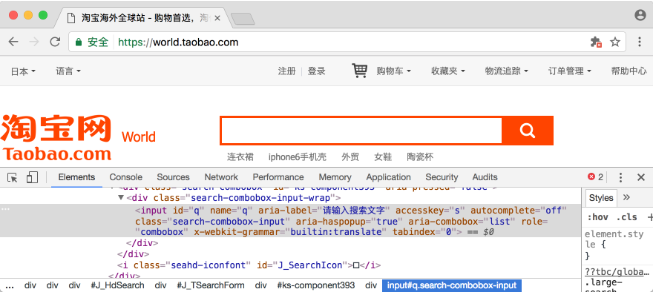
图7-2 源代码
可以发现,它的id是q,name也是q。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。比如,find_element_by_name()是根据name值获取,find_element_by_id()是根据id获取。另外,还有根据XPath、CSS选择器等获取的方式。
我们用代码实现一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)
browser.close()
这里我们使用3种方式获取输入框,分别是根据ID、CSS选择器和XPath获取,它们返回的结果完全一致。运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.564956309 6161541-1")> <selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.564956309 6161541-1")> <selenium.webdriver.remote.webelement.WebElement (session="5e53d9e1c8646e44c14c1c2880d424af", element="0.564956309 6161541-1")>
可以看到,这3个节点都是WebElement类型,是完全一致的。
这里列出所有获取单个节点的方法:
find_element_by_id find_element_by_name find_element_by_xpath find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name find_element_by_css_selector
另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。我们用代码实现一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()
实际上,这种查找方式的功能和上面列举的查找函数完全一致,不过参数更加灵活。
多个节点
如果查找的目标在网页中只有一个,那么完全可以用find_element()方法。但如果有多个节点,再用find_element()方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用find_elements()这样的方法。注意,在这个方法的名称中,element多了一个s,注意区分。
比如,要查找淘宝左侧导航条的所有条目,如图7-3所示。
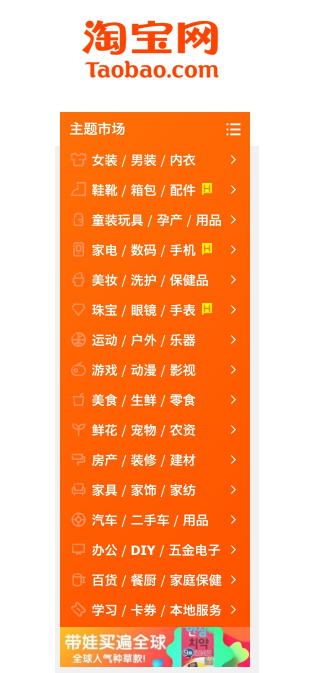
图7-3 导航栏
就可以这样来实现:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()
运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.0922104 4033125603-1")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-2")>, <selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d 96bfab3740d19", element="0.09221044033125603-3")>...<selenium.webdriver.remote.webelement.WebElement (session="c26290835d4457ebf7d96bfab3740d19", element="0.09221044033125603-16")>]
这里简化了输出结果,中间部分省略。
可以看到,得到的内容变成了列表类型,列表中的每个节点都是WebElement类型。
也就是说,如果我们用find_element()方法,只能获取匹配的第一个节点,结果是WebElement类型。如果用find_elements()方法,则结果是列表类型,列表中的每个节点是WebElement类型。
这里列出所有获取多个节点的方法:
find_elements_by_id find_elements_by_name find_elements_by_xpath find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name find_elements_by_css_selector
当然,我们也可以直接用find_elements()方法来选择,这时可以这样写:
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
结果是完全一致的。
6. 节点交互
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()
这里首先驱动浏览器打开淘宝,然后用find_element_by_id()方法获取输入框,然后用send_keys()方法输入iPhone文字,等待一秒后用clear()方法清空输入框,再次调用send_keys()方法输入iPad文字,之后再用find_element_by_class_name()方法获取搜索按钮,最后调用click()方法完成搜索动作。
通过上面的方法,我们就完成了一些常见节点的动作操作,更多的操作可以参见官方文档的交互动作介绍:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement。
7. 动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明ActionChains对象并将其赋值为actions变量,然后通过调用actions变量的drag_and_drop()方法,再调用perform()方法执行动作,此时就完成了拖曳操作,如图7-4和图7-5所示。

图7-4 拖曳前的页面
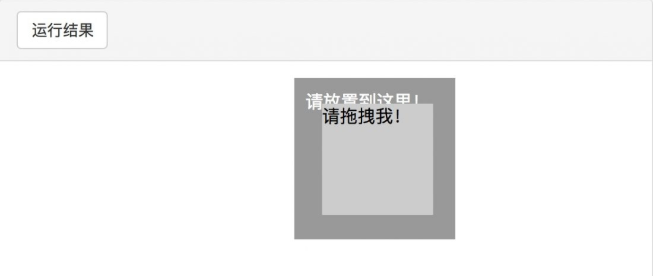
图7-5 拖曳后的页面
更多的动作链操作可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains。
8. 执行JavaScript
对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以直接模拟运行JavaScript,此时使用execute_script()方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
这里就利用execute_script()方法将进度条下拉到最底部,然后弹出alert提示框。
所以说有了这个方法,基本上API没有提供的所有功能都可以用执行JavaScript的方式来实现了。
9. 获取节点信息
前面说过,通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。
不过,既然Selenium已经提供了选择节点的方法,返回的是WebElement类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
接下来,就看看通过怎样的方式来获取节点信息吧。
获取属性
我们可以使用get_attribute()方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
运行之后,程序便会驱动浏览器打开知乎页面,然后获取知乎的logo节点,最后打印出它的class。
控制台的输出结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="e08c0f28d7f44d75ccd50df6bb676104", element="0.723639066 0048155-1")> zu-top-link-logo
通过get_attribute()方法,然后传入想要获取的属性名,就可以得到它的值了。
获取文本值
每个WebElement节点都有text属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于Beautiful Soup的get_text()方法、pyquery的text()方法,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.text)
这里依然先打开知乎页面,然后获取“提问”按钮这个节点,再将其文本值打印出来。
控制台的输出结果如下:
提问
获取id、位置、标签名和大小
另外,WebElement节点还有一些其他属性,比如id属性可以获取节点id,location属性可以获取该节点在页面中的相对位置,tag_name属性可以获取标签名称,size属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)
这里首先获得“提问”按钮这个节点,然后调用其id、location、tag_name、size属性来获取对应的属性值。
10. 切换Frame
我们知道网页中有一种节点叫作iframe,也就是子Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium打开页面后,它默认是在父级Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到子Frame里面的节点的。这时就需要使用switch_to.frame()方法来切换Frame。示例如下:
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
控制台的输出如下:
NO LOGO <selenium.webdriver.remote.webelement.WebElement (session="4bb8ac03ced4ecbdefef03ffdc0e4ccd", element="0.1379261132 0464965-2")> RUNOOB.COM
这里还是以前面演示动作链操作的网页为实例,首先通过switch_to.frame()方法切换到子Frame里面,然后尝试获取父级Frame里的logo节点(这是不能找到的),如果找不到的话,就会抛出NoSuchElementException异常,异常被捕捉之后,就会输出NO LOGO。接下来,重新切换回父级Frame,然后再次重新获取节点,发现此时可以成功获取了。
所以,当页面中包含子Frame时,如果想获取子Frame中的节点,需要先调用switch_to.frame()方法切换到对应的Frame,然后再进行操作。
11. 延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的Ajax请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
这里我们用implicitly_wait()方法实现了隐式等待。
显式等待
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
这里首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。比如,这里传入了presence_of_element_located这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
这样可以做到的效果就是,在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为element_to_be_clickable,也就是可点击,所以查找按钮时查找CSS选择器为.btn-search的按钮,如果10秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过10秒还不可点击,也就是没有加载出来,就抛出异常。
运行代码,在网速较佳的情况下是可以成功加载出来的。
控制台的输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="07dd2fbc2d5b1ce40e82b9754aba8fa8", element="0.564264629 4074107-1")> <selenium.webdriver.remote.webelement.WebElement (session="07dd2fbc2d5b1ce40e82b9754aba8fa8", element="0.564264629 4074107-2")>
可以看到,控制台成功输出了两个节点,它们都是WebElement类型。
如果网络有问题,10秒内没有成功加载,那就抛出TimeoutException异常,此时控制台的输出如下:
TimeoutException Traceback (most recent call last)
<ipython-input-4-f3d73973b223> in <module>()
7 browser.get('https://www.taobao.com/')
8 wait = WebDriverWait(browser, 10)
----> 9 input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
关于等待条件,其实还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。表7-1列出了所有的等待条件。
表7-1 等待条件及其含义
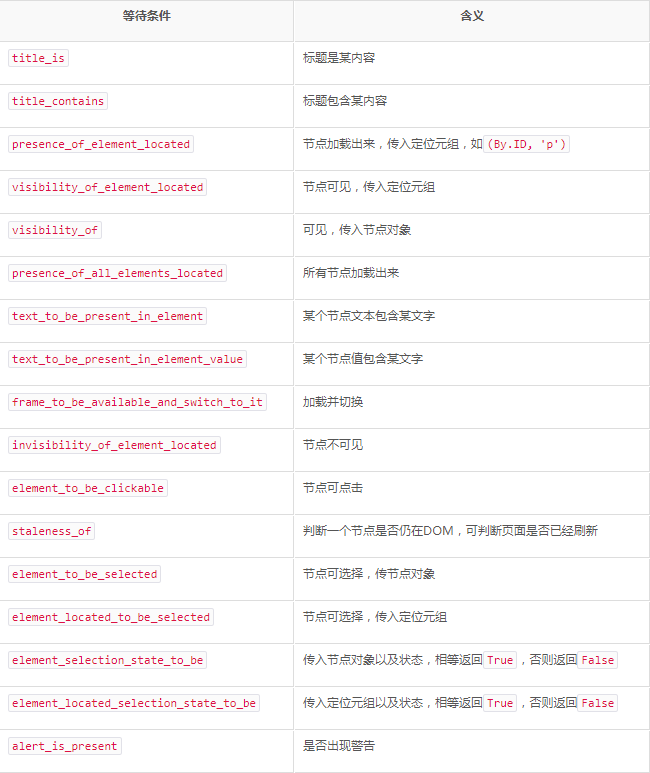
关于更多等待条件的参数及用法,可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions。
12. 前进和后退
平常使用浏览器时都有前进和后退功能,Selenium也可以完成这个操作,它使用back()方法后退,使用forward()方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
这里我们连续访问3个页面,然后调用back()方法回到第二个页面,接下来再调用forward()方法又可以前进到第三个页面。
13. Cookies
使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除Cookies等。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
首先,我们访问了知乎。加载完成后,浏览器实际上已经生成Cookies了。接着,调用get_cookies()方法获取所有的Cookies。然后,我们添加一个Cookie,这里传入一个字典,有name、domain和value等内容。接下来,再次获取所有的Cookies。可以发现,结果就多了这一项新加的Cookie。最后,调用delete_all_cookies()方法删除所有的Cookies。再重新获取,发现结果就为空了。
控制台的输出如下:
[{'secure': False, 'value': '"NGM0ZTM5NDAwMWEyNDQwNDk5ODlkZWY3OTkxY2I0NDY=|1491604091|236e34290a6f407bfbb517888
849ea509ac366d0"', 'domain': '.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'l_cap_id', 'expiry':
1494196091.403418}]
[{'secure': False, 'value': 'germey', 'domain': '.www.zhihu.com', 'path': '/', 'httpOnly': False, 'name':
'name'},
{'secure': False, 'value': '"NGM0ZTM5NDAwMWEyNDQwNDk5ODlkZWY3OTkxY2I0NDY=|1491604091|236e34290a6f407bfbb517888849
ea509ac366d0"', 'domain': '.zhihu.com', 'path': '/', 'httpOnly': False, 'name': 'l_cap_id', 'expiry':
1494196091.403418}]
[]
14. 选项卡管理
在访问网页的时候,会开启一个个选项卡。在Selenium中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://python.org')
控制台的输出如下:
['CDwindow-4f58e3a7-7167-4587-bedf-9cd8c867f435', 'CDwindow-6e05f076-6d77-453a-a36c-32baacc447df']
首先访问了百度,然后调用了execute_script()方法,这里传入window.open()这个JavaScript语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用window_handles属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用switch_to_window()方法即可,其中参数是选项卡的代号。这里我们将第二个选项卡代号传入,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用switch_to_window()方法,再执行其他操作即可。
15. 异常处理
在使用Selenium的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用try except语句来捕获各种异常。
首先,演示一下节点未找到的异常,示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.find_element_by_id('hello')
这里首先打开百度页面,然后尝试选择一个并不存在的节点,此时就会遇到异常。
运行之后控制台的输出如下:
NoSuchElementException Traceback (most recent call last)
<ipython-input-23-978945848a1b> in <module>()
3 browser = webdriver.Chrome()
4 browser.get('https://www.baidu.com')
----> 5 browser.find_element_by_id('hello')
可以看到,这里抛出了NoSuchElementException异常,这通常是节点未找到的异常。为了防止程序遇到异常而中断,我们需要捕获这些异常,示例如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
这里我们使用try except来捕获各类异常。比如,我们对find_element_by_id()查找节点的方法捕获NoSuchElementException异常,这样一旦出现这样的错误,就进行异常处理,程序也不会中断了。
控制台的输出如下:
No Element
关于更多的异常类,可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions。
现在,我们基本对Selenium的常规用法有了大体的了解。使用Selenium,处理JavaScript不再是难事。
到此这篇关于Python3爬虫中Selenium的用法详解的文章就介绍到这了,更多相关Python3里Selenium的使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python3.7+selenium模拟淘宝登录功能的实现
在使用selenium去获取淘宝商品信息时会遇到登录界面 这个登录界面处理的难度在于滑动验证的实现,有的人使用微博登录,避免了滑动验证,那可不可以使用密码登录呢?答案是可以的 实现思路 首先导入需要的库 from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.web
-
python3.8.1+selenium实现登录滑块验证功能
python3.8.1+selenium解决登录滑块验证的问题,先给大家分享一个效果图,感觉不错,可以参考实现代码. 这里的滑块是qq邮箱的截图,如图所示,可以作为同类滑块验证的参考. """ auther = "zwb",这里使用的python版本是3.8.1,selenium版本是3.141.0,webdriver是谷歌,版本是81.0.4044.138(正式版本) (64 位) webdriver各版本对应的浏览器下载地址:https://npm.t
-
Python3 selenium 实现QQ群接龙自动化功能
一.环境 环境配置为安装了 selenium 模块的 Python3 ,以及浏览器对应的driver 如果没有安装 selenium ,可以在控制台执行下面的代码 pip3 install selenium 浏览器driver下载地址:https://selenium-python.readthedocs.io/installation.html#drivers 需要选择对应的浏览器的对应版本进行下载 下载完成之后放到Python安装目录即可 二.代码 不足:只能给最新发布的一个群接龙进行自动接
-
Python3+Selenium+Chrome实现自动填写WPS表单
引言 本文通过python3.第三方python库Selenium和谷歌浏览器Chrome,完成WPS表单的自动填写. 开发环境配置 python3的安装:略,网上都有教程. Selenium的安装:在命令行输入pip3 install selenium并回车即可完成安装,如果不成功,查找网上教程. Chrome的安装:略,网上都有教程. 因为Selenium需要ChromeDriver来驱动Chrome,所以还需要下载驱动ChromeDriver.下面重点介绍一下Chrom
-
python3+selenium获取页面加载的所有静态资源文件链接操作
软件版本: python 3.7.2 selenium 3.141.0 pycharm 2018.3.5 具体实现流程如下,废话不多说,直接上代码: from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.desired_capabilities import DesiredCapabilities d = Desired
-
Python3爬虫中Selenium的用法详解
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击.下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬.对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效.本节中,就让我们来感受一下它的强大之处吧. 1. 准备工作 本节以Chrome为例来讲解Selenium的用法.在开始之前,请确保已经正确安装好了Chrome浏览器并配置好了ChromeDriver.另外,还需要正确安装好Python的Selenium库,详细的安装和配置过程
-
python爬虫中多线程的使用详解
queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue.python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性. #多线程实战栗子(糗百) #用一个队列Queue对象, #先产生所有url,put进队列: #开启多线程,把q
-
python中yield的用法详解——最简单,最清晰的解释
首先我要吐槽一下,看程序的过程中遇见了yield这个关键字,然后百度的时候,发现没有一个能简单的让我懂的,讲起来真TM的都是头头是道,什么参数,什么传递的,还口口声声说自己的教程是最简单的,最浅显易懂的,我就想问没有有考虑过读者的感受. 接下来是正题: 首先,如果你还没有对yield有个初步分认识,那么你先把yield看做"return",这个是直观的,它首先是个return,普通的return是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了.看做return之后再把它
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
python中yield的用法详解
首先我要吐槽一下,看程序的过程中遇见了yield这个关键字,然后百度的时候,发现没有一个能简单的让我懂的,讲起来真TM的都是头头是道,什么参数,什么传递的,还口口声声说自己的教程是最简单的,最浅显易懂的,我就想问没有有考虑过读者的感受. 接下来是正题: 首先,如果你还没有对yield有个初步分认识,那么你先把yield看做"return",这个是直观的,它首先是个return,普通的return是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了.看做return之后再把它
-
基于C++中setiosflags()的用法详解
cout<<setiosflags(ios::fixed)<<setiosflags(ios::right)<<setprecision(2); setiosflags 是包含在命名空间iomanip 中的C++ 操作符,该操作符的作用是执行由有参数指定区域内的动作: iso::fixed 是操作符setiosflags 的参数之一,该参数指定的动作是以带小数点的形式表示浮点数,并且在允许的精度范围内尽可能的把数字移向小数点右侧: iso::right 也是se
-
Angular 中 select指令用法详解
最近在angular中使用select指令时,出现了很多问题,搞得很郁闷.查看了很多资料后,发现select指令并不简单,决定总结一下. select用法: <select ng-model="" [name=""] [required=""] [ng-required=""] [ng-options=""]> </select> 属性说明: 发现并没有ng-change属性 ng-
-
java 中 ChannelHandler的用法详解
java 中 ChannelHandler的用法详解 前言: ChannelHandler处理一个I/O event或者拦截一个I/O操作,在它的ChannelPipeline中将其递交给相邻的下一个handler. 通过继承ChannelHandlerAdapter来代替 因为这个接口有许多的方法需要实现,你或许希望通过继承ChannelHandlerAdapter来代替. context对象 一个ChannelHandler和一个ChannelHandlerContext对象一起被提供.一个
-

Java中isAssignableFrom的用法详解
class1.isAssignableFrom(class2) 判定此 Class 对象所表示的类或接口与指定的 Class 参数所表示的类或接口是否相同,或是否是其超类或超接口.如果是则返回 true:否则返回 false.如果该 Class 表示一个基本类型,且指定的 Class 参数正是该 Class 对象,则该方法返回 true:否则返回 false. 1. class2是不是class1的子类或者子接口 2. Object是所有类的父类 一个例子搞定: package com.auuz
-
php 中的closure用法详解
Closure,匿名函数,是php5.3的时候引入的,又称为Anonymous functions.字面意思也就是没有定义名字的函数.比如以下代码(文件名是do.php) <?php function A() { return 100; }; function B(Closure $callback) { return $callback(); } $a = B(A()); print_r($a);//输出:Fatal error: Uncaught TypeError: Argument 1