Linux中安装配置hadoop集群详细步骤
一. 简介
参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功。下面就把详细的安装步骤叙述一下。我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本。(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明)
二. 准备工作
2.1 创建用户
创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好。
sudo adduser hadoop sudo vim /etc/sudoers # 修改内容如下: root ALL = (ALL)ALL hadoop ALL = (ALL)ALL
给hadoop用户创建目录,并添加到sudo用户组中,命令如下:
sudo chown hadoop /home/hadoop # 添加到sudo用户组 sudo adduser hadoop sudo
最后注销当前用户,使用新创建的hadoop用户登陆。
2.2 安装ssh服务
ubuntu中默认是没有装ssh server的(只有ssh client),所以先运行以下命令安装openssh-server。安装过程轻松加愉快~
sudo apt-get install ssh openssh-server
2.3 配置ssh无密码登陆
直接上代码:执行完下边的代码就可以直接登陆了(可以运行ssh localhost进行验证)
cd ~/.ssh # 如果找不到这个文件夹,先执行一下 "ssh localhost" ssh-keygen -t rsa cp id_rsa.pub authorized_keys
注意:
这里实现的是无密登陆自己,只适用与hadoop单机环境。如果配置Hadoop集群设置Master与Slave的SSH无密登陆可以参考我的另一篇博文:http://www.jb51.net/article/105483.htm
三. 安装过程
3.1 下载hadoop安装包
有两种下载方式:
1. 直接去官网下载:
http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2. 使用wget命令下载:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
3.2 配置hadoop
1. 解压下载的hadoop安装包,并修改配置文件。我的解压目录是(/home/hadoop/hadoop-2.7.1),即进入/home/hadoop/文件夹下执行下面的解压缩命令。
tar -zxvf hadoop-2.7.1.tar.gz
2. 修改配置文件:(hadoop2.7.1/etc/hadoop/)目录下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml。
(1). core-site.xml 配置:其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
(2). mapred-site.xml.template配置:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
(3). hdfs-site.xml配置: 其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
注意:如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop-env.sh里面,具体如下:
export JAVA_HOME="/opt/java_file/jdk1.7.0_79",即安装java时的路径。
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成后运行hadoop。
四. 运行hadoop
4.1 初始化HDFS系统
在hadop2.7.1目录下执行命令:
bin/hdfs namenode -format
出现如下结果说明初始化成功。

4.2 开启 NameNode 和 DataNode 守护进程
在hadop2.7.1目录下执行命令:
sbin/start-dfs.sh
成功的截图如下:

4.3 使用jps命令查看进程信息:

若出现如图所示结果,则说明DataNode和NameNode都已经开启。
4.4 查看web界面
在浏览器中输入 http://localhost:50070 ,即可查看相关信息,截图如下
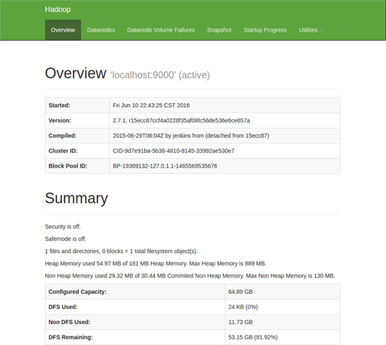
至此,hadoop的环境就已经搭建好了。
五. 运行wordcount demo
1. 在本地新建一个文件,里面内容随便填:例如我在home/hadoop目录下新建了一个haha.txt文件,里面的内容为" hello world! "。
2. 然后在分布式文件系统(hdfs)中新建一个test文件夹,用于上传我们的测试文件haha.txt。在hadoop-2.7.1目录下运行命令:
# 在hdfs的根目录下建立了一个test目录 bin/hdfs dfs -mkdir /test # 查看HDFS根目录下的目录结构 bin/hdfs dfs -ls /
结果如下:

3. 将本地haha.txt文件上传到test目录中;
# 上传 bin/hdfs dfs -put /home/hadoop/haha.txt /test/ # 查看 bin/hdfs dfs -ls /test/
结果如下:

4. 运行wordcount demo;
# 将运行结果保存在/test/out目录下 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/haha.txt /test/out # 查看/test/out目录下的文件 bin/hdfs dfs -ls /test/out
结果如下:

运行结果表示:运行成功,结果保存在part-r-00000中。
5. 查看运行结果;
# 查看part-r-00000中的运行结果 bin/hadoop fs -cat /test/out/part-r-00000
结果如下:

至此,wordcount demo 运行结束。
六. 总结
配置过程遇到了很多问题,最后都一一解决,收获很多,特此把这次配置的经验分享出来,方便想要配置hadoop环境的各位朋友~
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Java执行hadoop的基本操作实例代码
Java执行hadoop的基本操作实例代码 向HDFS上传本地文件 public static void uploadInputFile(String localFile) throws IOException{ Configuration conf = new Configuration(); String hdfsPath = "hdfs://localhost:9000/"; String hdfsInput = "hdfs://localhost:9000/user/
-

详解搭建ubuntu版hadoop集群
用到的工具:VMware.hadoop-2.7.2.tar.jdk-8u65-linux-x64.tar.ubuntu-16.04-desktop-amd64.iso 1. 在VMware上安装ubuntu-16.04-desktop-amd64.iso 单击"创建虚拟机"è选择"典型(推荐安装)"è单击"下一步" è点击完成 修改/etc/hostname vim hostname 保存退出 修改etc/hosts 127.0.0.1 loc
-
hadoop动态增加和删除节点方法介绍
上一篇文章中我们介绍了Hadoop编程基于MR程序实现倒排索引示例的有关内容,这里我们看看如何在Hadoop中动态地增加和删除节点(DataNode). 假设集群操作系统均为:CentOS 6.7 x64 Hadoop版本为:2.6.3 一.动态增加DataNode 1.准备新的DataNode节点机器,配置SSH互信,可以直接复制已有DataNode中.ssh目录中的authorized_keys和id_rsa 2.复制Hadoop运行目录.hdfs目录及tmp目录至新的DataNode 3.
-
详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
详解VMware12使用三台虚拟机Ubuntu16.04系统搭建hadoop-2.7.1+hbase-1.2.4(完全分布式)
初衷 首先说明一下既然网上有那么多教程为什么要还要写这样一个安装教程呢?网上教程虽然多,但是有些教程比较老,许多教程忽略许多安装过程中的细节,比如添加用户的权限,文件权限,小编在安装过程遇到许多这样的问题所以想写一篇完整的教程,希望对初学Hadoop的人有一个直观的了解,我们接触真集群的机会比较少,虚拟机是个不错的选择,可以基本完全模拟真实的情况,前提是你的电脑要配置相对较好不然跑起来都想死,废话不多说. 环境说明 本文使用VMware® Workstation 12 Pro虚拟机创建并安装三台
-
Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
在centos 7中安装配置k8s集群的步骤详解
配置背景介绍 kubernetes是google开源的容器集群管理系统,提供应用部署.维护.扩展机制等功能,利用kubernetes能方便管理跨集群运行容器化的应用,简称:k8s(k与s之间有8个字母) 为什么要用kubernetes这么复杂的docker集群管理工具呢?一开始接触了docker内置的swarm,这个工具非常简单快捷的完成docker集群功能.但是在使用docker1.13内置的swarm做集群的时候遇到vip负载均衡没有正确映射端口到外网,或者出现地址被占用的情况,这对高可用性
-
Linux下安装Hadoop集群详细步骤
目录 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 2.进入vim /etc/profile文件并编辑配置文件 3.使文件生效 4.进入Hadoop目录下 5.编辑配置文件 6.进入slaves添加主节点和从节点 7.将各个文件复制到其他虚拟机上 8.格式化hadoop (仅在主节点中进行操作) 9.回到Hadoop目录下(仅在主节点操作) 1.在usr目录下创建Hadoop目录,将安装包导入目录中并解压文件 2.进入vim /etc/profile文件并编辑配置文件
-
Android Studio安装配置、环境搭建详细步骤及基本使用的详细教程
前言 Android Studio的安装配置及使用篇终于来啦~ 废话不多说,以下针对JDK正确安装(及其环境变量配置完毕,即Java开发环境下).Android Studio的安装,配置,以及创建工程.主题字体更换.窗口工具.布局.快捷方式等的基本使用逐一说明. 安装java 下载Java安装包(jdk,网上有很多下载地址,最好去官网下:https://www.java.com/zh_CN/),安装完后记得配置环境变量: 在"系统变量"新建一个变量名为JAVA_HOME的变量,变量值为
-
CentOS 7.4 64位安装配置MySQL8.0的详细步骤
第一步:获取mysql YUM源 进入mysql官网获取RPM包下载地址 https://dev.mysql.com/downloads/repo/yum/ 点击下载 获取到下载链接: https://repo.mysql.com//mysql80-community-release-el7-1.noarch.rpm -------------------------------------------------------------------------------- 第二步:下载和安装
-
Linux上安装搭建Nginx服务器的详细步骤
1.将nginx的压缩包nginx-1.8.0.tar.gz上传到Linux服务器 2.由于nginx是C语言开发的并且我们这里是通过编译nginx的源码来安装nginx,所以Linux上要安装C语言的编译环境gcc, 如果已经安装此步可以省略,否则执行命令: yum install gcc-c++ 3.nginx的http模块使用pcre来解析正则表达式,所以需要在linux上安装pcre库. yum install -y pcre pcre-devel 4.zlib库提供了很多种压缩和解压缩
-
linux下安装配置svn独立服务器的步骤分享
file:/// 直接版本库访问(本地磁盘). http:// 通过配置Subversion的Apache服务器的WebDAV协议. https:// 与http://相似,但是包括SSL加密. svn:// 通过svnserve服务自定义的协议. svn+ssh:// 与svn://相似,但通过SSH封装 svn存储版本数据也有2种方式:BDB和FSFS.因为BDB方式在服务器中断时,有可能锁住数据,所以还是FSFS方式更安全一点.1. svn服务器安装操作系统: Redhat Linux A
-
在CentOS中安装Rancher2并配置kubernetes集群的图文教程
准备 一台CentOS主机,安装DockerCE,用于安装Rancher2 一台CentOS主机,安装DockerCE,用于安装kubernetes集群管理主机 多台CentOS主机,安装DockerCE,用于运行kubernetes工作节点,工作节点需要与集群管理主机在同一个子网中 掌握Docker常用操作,了解K8s基本原理 安装Rancher2 第一步:执行命令,运行Rancher2,绑定主机端口80和443. docker run -d --restart=unless-stopped
-
使用docker部署hadoop集群的详细教程
最近要在公司里搭建一个hadoop测试集群,于是采用docker来快速部署hadoop集群. 0. 写在前面 网上也已经有很多教程了,但是其中都有不少坑,在此记录一下自己安装的过程. 目标:使用docker搭建一个一主两从三台机器的hadoop2.7.7版本的集群 准备: 首先要有一台内存8G以上的centos7机器,我用的是阿里云主机. 其次将jdk和hadoop包上传到服务器中. 我安装的是hadoop2.7.7.包给大家准备好了,链接:https://pan.baidu.com/s/15n
-
利用MySQL Shell安装部署MGR集群的详细过程
目录 1. 安装准备 2. 利用MySQL Shell构建MGR集群 3. MySQL Shell接管现存的MGR集群 4. 小结 参考资料.文档 免责声明 本文介绍如何利用MySQL Shell + GreatSQL 8.0.25构建一个三节点的MGR集群. MySQL Shell是一个客户端工具,可用于方便管理和操作MySQL,支持SQL.JavaScript.Python等多种语言,也包括完善的API.MySQL Shell支持文档型和关系型数据库模式,通过X DevAPI可以管理文档型数