MySQL生成千万测试数据以及遇到的问题
目录
- 1、创建基础表结构
- 2、创建内存表
- 3、创建存储过程和函数
- 4、执行存储过程
- 5、遇到的问题
- 5.1、1449错误
- 5.2、1114错误
- 6、同步数据
- 总结
1、创建基础表结构
CREATE TABLE `t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c_user_id` varchar(36) NOT NULL DEFAULT '', `c_name` varchar(22) NOT NULL DEFAULT '', `c_province_id` int(11) NOT NULL, `c_city_id` int(11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `idx_user_id` (`c_user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2、创建内存表
直接往实表添加数据比较慢,所以我们先插入内存表,然后再同步到实表。
CREATE TABLE `t_user_memory` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c_user_id` varchar(36) NOT NULL DEFAULT '', `c_name` varchar(22) NOT NULL DEFAULT '', `c_province_id` int(11) NOT NULL, `c_city_id` int(11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `idx_user_id` (`c_user_id`) ) ENGINE=MEMORY DEFAULT CHARSET=utf8mb4;
3、创建存储过程和函数
# 创建随机字符串 delimiter $$ CREATE DEFINER = `root` @`%` FUNCTION `randStr` ( n INT ) RETURNS VARCHAR ( 255 ) CHARSET utf8mb4 DETERMINISTIC BEGIN DECLARE chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; DECLARE return_str VARCHAR ( 255 ) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = concat( return_str, substring( chars_str, FLOOR( 1 + RAND() * 62 ), 1 )); SET i = i + 1; END WHILE; RETURN return_str; END $$ # 创建随机时间的函数,sd和ed两个入参代表生成的时间是这个时间范围内的。sd开始时间,ed截止时间。 CREATE DEFINER = `root` @`%` FUNCTION `randDataTime` ( sd DATETIME, ed DATETIME ) RETURNS datetime DETERMINISTIC BEGIN DECLARE sub INT DEFAULT 0; DECLARE ret DATETIME; SET sub = ABS( UNIX_TIMESTAMP( ed )- UNIX_TIMESTAMP( sd )); SET ret = DATE_ADD( sd, INTERVAL FLOOR( 1+RAND ()*( sub - 1 )) SECOND ); RETURN ret; END $$ # 创建插入数据存储过程 CREATE DEFINER = `root` @`%` PROCEDURE `add_t_user_memory` ( IN n INT ) BEGIN DECLARE i INT DEFAULT 1; WHILE ( i <= n ) DO INSERT INTO t_user_memory ( c_user_id, c_name, c_province_id, c_city_id, create_time ) VALUES ( uuid(), randStr ( 20 ), FLOOR( RAND() * 1000 ), FLOOR( RAND() * 100 ), randDataTime ( "2020-01-01", "2021-01-01" )); SET i = i + 1; END WHILE; END $$ delimiter ;
4、执行存储过程
存储过程当中的数字就是要生成的数量,自行填写。
CALL add_t_user_memory(10);
100万大概需要8分钟!

5、遇到的问题
创建存储过程和执行的时候可能会出现以下两种问题:
5.1、1449错误
在创建存储过程的时候可能会出现1449:错误:
mysql 1449 : The user specified as a definer (‘root’@‘%’) does not exist
经查询是权限问题,解决办法:
运行sql:
grant all privileges on *.* to 'root'@'%' identified by "."; flush privileges;
5.2、1114错误
当生成数量大的时候就可能会报这个错误:

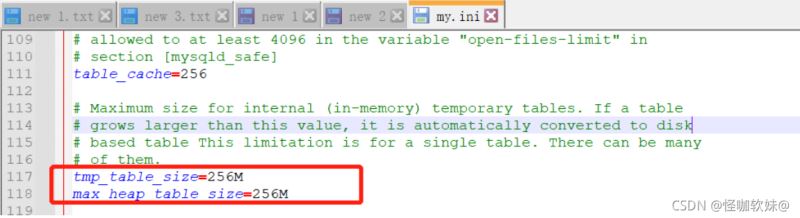
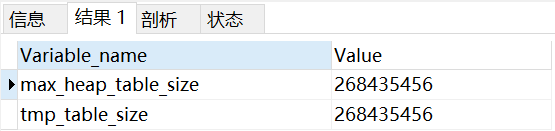
解决方法:在my.cnf中修改max_heap_table_size = 256M tmp_table_size = 256M,重启MySQL服务(my.cnf在mysql安装路径),如果还不够用根据自己电脑自行修改。如果是线上服务器,最好不要自行修改,还是跟运维多沟通沟通,避免出现问题。
show VARIABLES like '%TABLE_size%';
改完可以在这进行查看:
6、同步数据
INSERT INTO t_user SELECT * FROM t_user_memory;
总结
到此这篇关于MySQL生成千万测试数据以及遇到的问题的文章就介绍到这了,更多相关MySQL生成千万测试数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Mysql快速插入千万条数据的实战教程
一.创建数据库 二.创建表 1.创建 dept表 CREATE TABLE `dept` ( `id` int(11) NOT NULL, `deptno` mediumint(9) DEFAULT NULL, `dname` varchar(20) DEFAULT NULL, `loc` varchar(13) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 2.创建emp表 CREATE TABLE
-
MySQL 千万级数据量如何快速分页
前言 后端开发中为了防止一次性加载太多数据导致内存.磁盘IO都开销过大,经常需要分页展示,这个时候就需要用到MySQL的LIMIT关键字.但你以为LIMIT分页就万事大吉了么,Too young,too simple啊,LIMIT在数据量大的时候极可能造成的一个问题就是深度分页. 案例 这里我以显示电商订单详情为背景举个例子,新建表如下: CREATE TABLE `cps_user_order_detail` ( `id` bigint(20) unsigned NOT NULL AUTO_I
-
Mysql中一千万条数据怎么快速查询
目录 普通分页查询 如何优化 偏移量大 采用id限定方式 优化数据量大问题 普通分页查询 当我们在日常工作中遇到大数据查询的时候,第一反应就是使用分页查询. mysql支持limit语句来选取指定的条数数据,而oracle可以使用rownum来选取 mysql分页查询语句如下: SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset 第一个参数用来指定第一个返回记录行的偏移量 第二个参数指定返回记录行的最大数目 当相同的偏移量时
-
mysql千万级数据分页查询性能优化
mysql数据量大时使用limit分页,随着页码的增大,查询效率越低下. 实验 1.直接使用用limit start, count分页语句: select * from order limit start, count 当起始页较小时,查询没有性能问题,我们分别看下从10, 100, 1000, 10000开始分页的执行时间(每页取20条), 如下: select * from order limit 10, 20 0.016秒 select * from order limit 100, 20
-
MySql 快速插入千万级大数据的方法示例
在数据分析领域,数据库是我们的好帮手.不仅可以接受我们的查询时间,还可以在这基础上做进一步分析.所以,我们必然要在数据库插入数据.在实际应用中,我们经常遇到千万级,甚至更大的数据量.如果没有一个快速的插入方法,则会事倍功半,花费大量的时间. 在参加阿里的天池大数据算法竞赛中(流行音乐趋势预测),我遇到了这样的问题,在没有优化数据库查询及插入之前,我花了不少冤枉时间,没有优化之前,1500万条数据,光插入操作就花费了不可思议的12个小时以上(使用最基本的逐条插入).这也促使我思考怎样优化数据库插入
-
MySQL循环插入千万级数据
1.创建测试表 CREATE TABLE `mysql_genarate` ( `id` int(11) NOT NULL AUTO_INCREMENT, `uuid` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5999001 DEFAULT CHARSET=utf8; 2.创建一个循环插入的存储过程 CREATE DEFINER=`root`@`localhost` PROCEDURE
-
MySQL 快速删除大量数据(千万级别)的几种实践方案详解
笔者最近工作中遇见一个性能瓶颈问题,MySQL表,每天大概新增776万条记录,存储周期为7天,超过7天的数据需要在新增记录前老化.连续运行9天以后,删除一天的数据大概需要3个半小时(环境:128G, 32核,4T硬盘),而这是不能接受的.当然如果要整个表删除,毋庸置疑用 TRUNCATE TABLE就好. 最初的方案(因为未预料到删除会如此慢),代码如下(最简单和朴素的方法): delete from table_name where cnt_date <= target_date 后经过研究,
-
30个mysql千万级大数据SQL查询优化技巧详解
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用
-
MySQL如何快速的创建千万级测试数据
备注: 此文章的数据量在100W,如果想要千万级,调大数量即可,但是不要大量使用rand() 或者uuid() 会导致性能下降 背景 在进行查询操作的性能测试或者sql优化时,我们经常需要在线下环境构建大量的基础数据供我们测试,模拟线上的真实环境. 废话,总不能让我去线上去测试吧,会被DBA砍死的 创建测试数据的方式 1. 编写代码,通过代码批量插库(本人使用过,步骤太繁琐,性能不高,不推荐) 2. 编写存储过程和函数执行(本文实现方式1) 3. 临时数据表方式执行 (本文实现方式2,强烈推荐该
-
mysql千万级数据大表该如何优化?
1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数据查询SQL条件:哪些数据项的列名称经常出现在WHERE.GROUP BY.ORDER BY子句中等: 4.数据更新类SQL条件:有多少列经常出现UPDATE或DELETE 的WHERE子句中: 5.SQL量的统计比,如:SELECT:UPDATE+DELETE:INSERT=多少? 6.预计大表及相关联的SQL,每天总的执行量在何数量级? 7.表中的数据:更新为主的