使用python实现两数之和的画解算法
题目描述
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
问题分析
1.暴力求解
两层循环,外层循环枚举(或称作选中一个标杆),内层循环从枚举值之后开始遍历,计算两数的和是否等于target。
如果找到了两个数,那么返回这两个数的下标。
for(int i = 0; i < n - 1; ++i) {
for(int j = i + 1; j < n; ++j ) {
if nums[i] + nums[j] == target
...
}
}
暴力求解的算法时间复杂度为指数级,也就是O(n^2)
分析暴力求解,我们发现存在重复搜索的情况,也就是对数组中的部分数据搜索了多次。
那如何只对数组中的数据搜索1次(或常数级),然后求解呢?
我们知道,寻找一个数是否存在,最快的方法是通过hash表,在O(1)的时间复杂度之内就可以判断是否存在某个数。
2.哈希表求解
可对数组遍历一次,然后将数据存入hash表,然后再遍历一次数组
查找 target - currentdata 是否存在hash表中,如果存在,那么我们就寻找到了两个数。
题目要求我们返回数组的下标,那么我们的hash表的key是数组元素的值,value是下标。
- 这种方法在最坏的情况下,对数组遍历了2次,也就是算法的时间复杂度是O(2n),去掉前导系数是O(n),虽然是相比暴力求解,算法的时间复杂度降低了,但是还有优化的空间。
- 在遍历数组并将数据放入hash表的同时,我们也可以
find(target - currentdata)是否存在,如果存在那么就找到了满足条件的两个数。
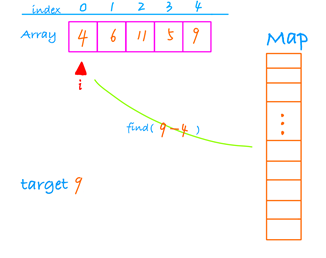
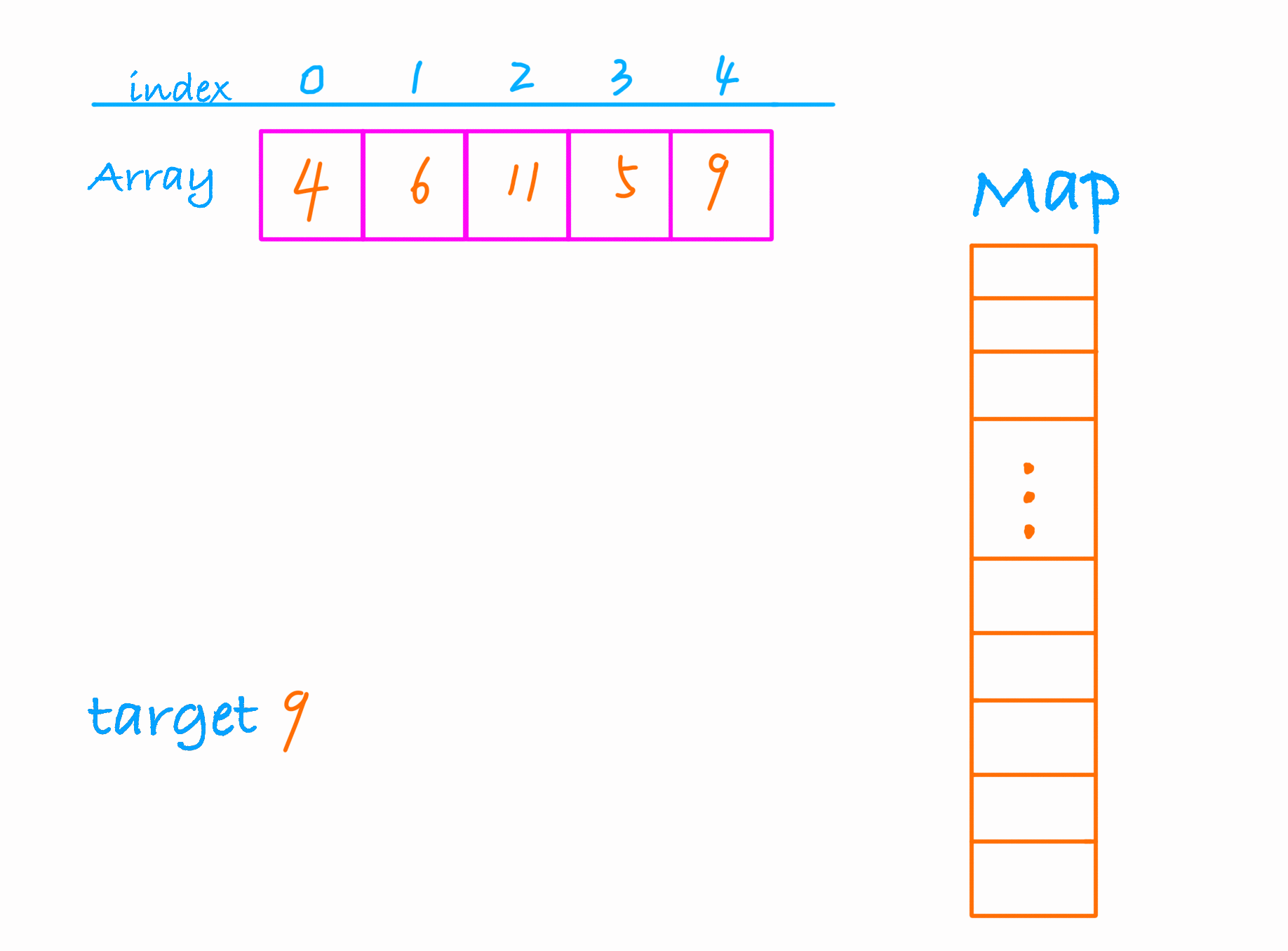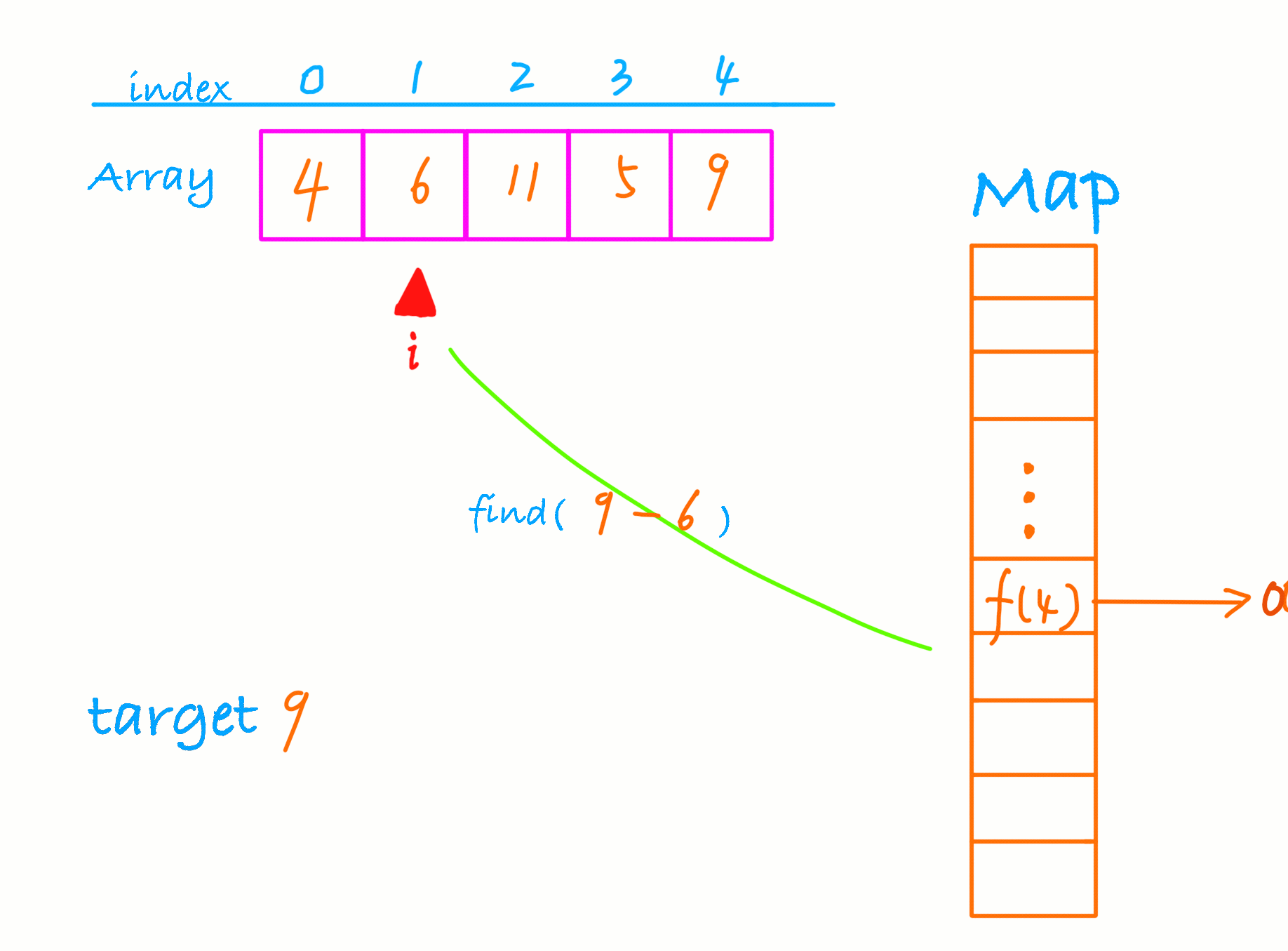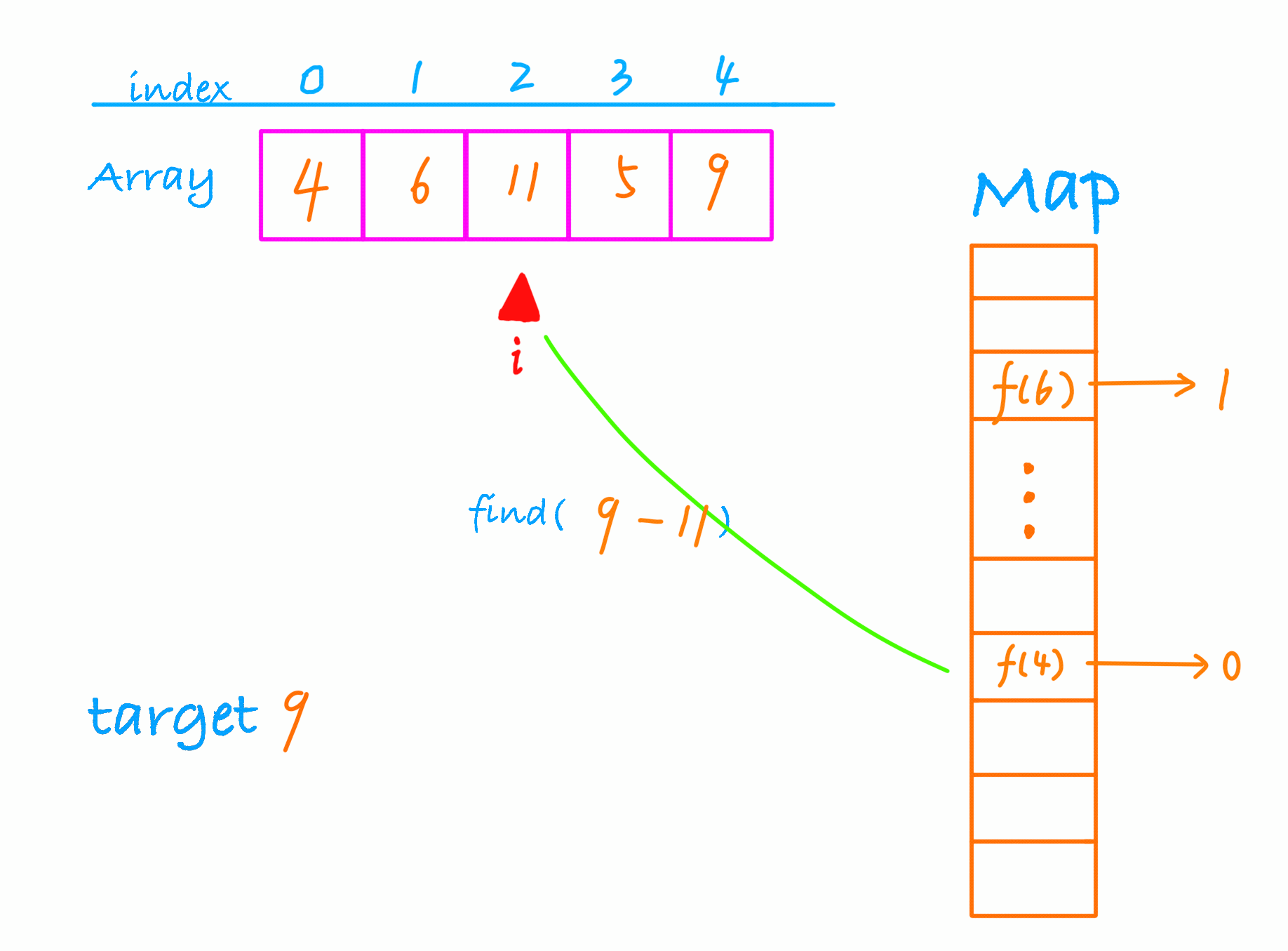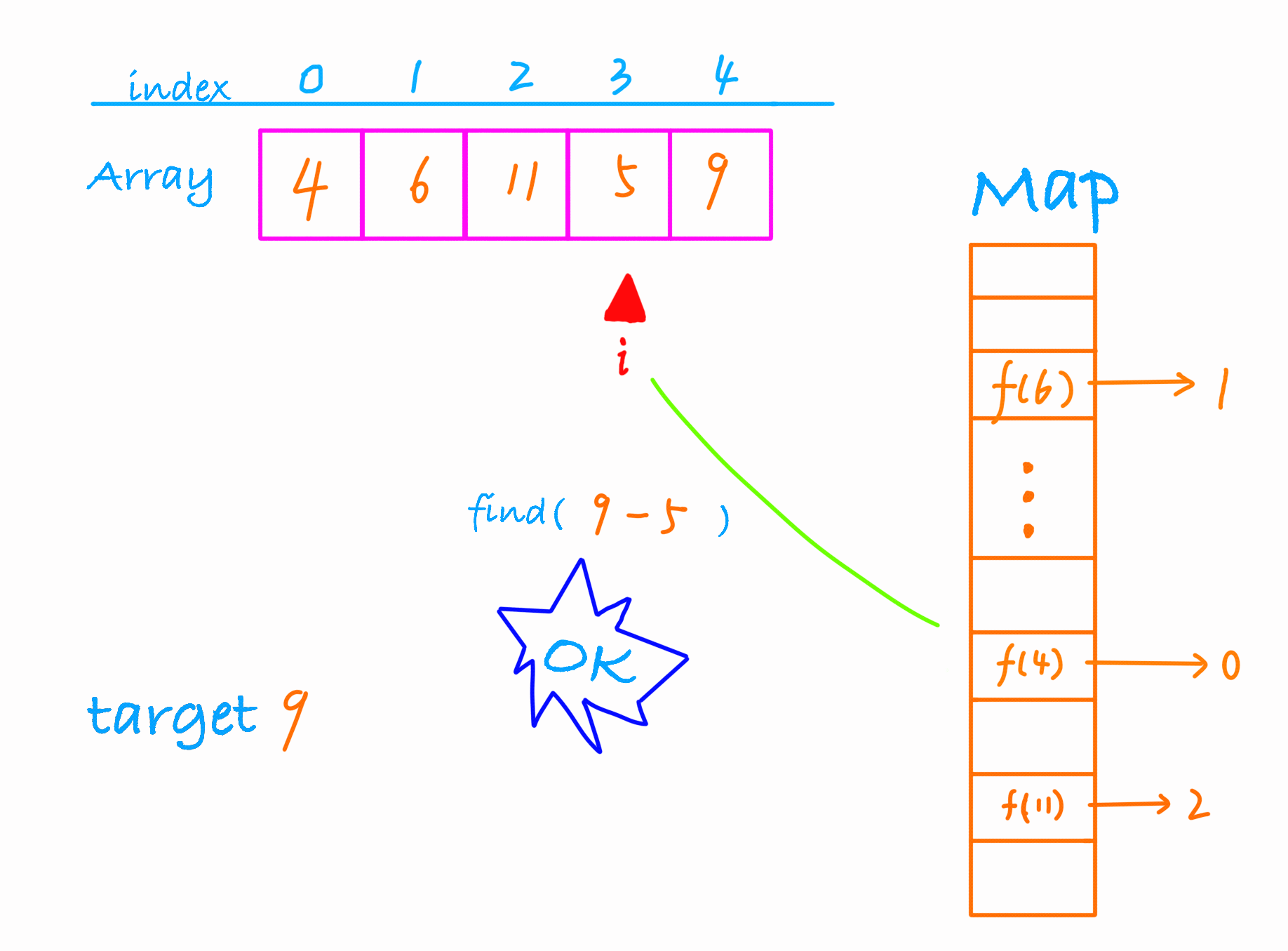
find(9-4), 存在那返回这两个数的下标,如果不存在,那么将 4 放入hash表。
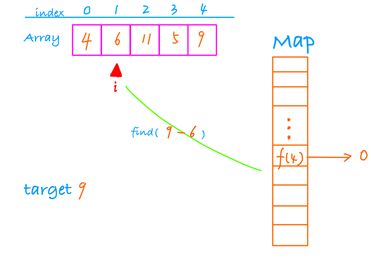
find(9-6), 存在那返回这两个数的下标,如果不存在,那么将 6 放入hash表。
在遍历到元素5的时候,我们find(9-5),找到了这两个数。

动画演示下这个过程
代码实现
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashtable = dict()
for i, num in enumerate(nums):
# ② map中查找是否有 target - curvalue的数据
if target - num in hashtable:
return [hashtable[target - num], i]
# ① 数组中的每个数放入map中
hashtable[nums[i]] = i
return []
以上就是使用python实现两数之和的画解算法的详细内容,更多关于python实现两数之和的画解算法的资料请关注我们其它相关文章!
相关推荐
-
Python 经典算法100及解析(小结)
1:找出字符串s="aaabbbccceeefff111144444"中,字符出现次数最多的字符 (1)考虑去重,首先将字符串进行过滤去重,这样在根据这些字符进行循环查询时,将会减少循环次数,提升效率.但是本人写的代码较为臃肿,有更好的希望留言评论 str = 'a1fsfs111bbbcccccvvvvvnnnnboooooosssnb' class Countvalue(): def countvalue(self, str1): ''' 利用set自身的去重功能 :param s
-

Python实现各种排序算法的代码示例总结
在Python实践中,我们往往遇到排序问题,比如在对搜索结果打分的排序(没有排序就没有Google等搜索引擎的存在),当然,这样的例子数不胜数.<数据结构>也会花大量篇幅讲解排序.之前一段时间,由于需要,我复习了一下排序算法,并用Python实现了各种排序算法,放在这里作为参考. 最简单的排序有三种:插入排序,选择排序和冒泡排序.这三种排序比较简单,它们的平均时间复杂度均为O(n^2),在这里对原理就不加赘述了.贴出来源代码. 插入排序: def insertion_sort(sort_lis
-
详解用python实现简单的遗传算法
今天整理之前写的代码,发现在做数模期间写的用python实现的遗传算法,感觉还是挺有意思的,就拿出来分享一下. 首先遗传算法是一种优化算法,通过模拟基因的优胜劣汰,进行计算(具体的算法思路什么的就不赘述了).大致过程分为初始化编码.个体评价.选择,交叉,变异. 遗传算法介绍 遗传算法是通过模拟大自然中生物进化的历程,来解决问题的.大自然中一个种群经历过若干代的自然选择后,剩下的种群必定是适应环境的.把一个问题所有的解看做一个种群,经历过若干次的自然选择以后,剩下的解中是有问题的最优解的.当然,只
-
Python常用算法学习基础教程
本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出.如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题.不同的算法可能用不同的时间.空间或效率来完成同样的任务.一个算法的优劣可以用空间复杂度与时间复杂度来衡量. 一个算法应该具有以下七个重要的特征: ①有穷性(Fin
-
使用python实现两数之和的画解算法
题目描述 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标. 你可以假设每种输入只会对应一个答案.但是,数组中同一个元素在答案里不能重复出现. 你可以按任意顺序返回答案. 示例 1: 输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] . 示例 2: 输入:nums = [3,2,4],
-
python简单实现整数反转的画解算法
题目描述 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果. 如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0. 假设环境不允许存储 64 位整数(有符号或无符号). 示例 1: 输入:x = 123 输出:321 示例 2: 输入:x = -123 输出:-321 示例 3: 输入:x = 120 输出:21 示例 4: 输入:x = 0 输出:0 问题分析 首先我们想一下,怎么去反转一个整数? 用栈? 或者把整数变成字符串
-
JS求解两数之和算法详解
本文实例讲述了JS求解两数之和算法.分享给大家供大家参考,具体如下: 题目描述 给定一个整数数组和一个目标值,找出数组中和为目标值的两个数. 你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用. ::: tip 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返回 [0, 1] ::: 解法 利用 Map 记录数组元素值和对应的下标,对于一个数 nums[i],判断 target - num
-
Java实现LeetCode(两数之和)
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数. 你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用. 示例: 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返回[0, 1] 思路一:最直接的思维,两次遍历查询,时间复杂度O(N*N). 代码: public static int[] twoSum1(int[] nums, int target) { int[] label =
-
C++实现LeetCode(170.两数之和之三 - 数据结构设计)
[LeetCode] 170. Two Sum III - Data structure design 两数之和之三 - 数据结构设计 Design and implement a TwoSum class. It should support the following operations: add and find. add - Add the number to an internal data structure. find - Find if there exists any pai
-
C++实现LeetCode(167.两数之和之二 - 输入数组有序)
[LeetCode] 167.Two Sum II - Input array is sorted 两数之和之二 - 输入数组有序 Given an array of integers that is already sorted in ascending order, find two numbers such that they add up to a specific target number. The function twoSum should return indices of t
-
c语言如何实现两数之和
目录 c语言实现两数之和 c语言中比较两数大小 题目要求 分析一下 c语言实现两数之和 int *twoSum(int *nums , int numsSize , int target , int *returnSize) { int i = 0 , j = 0; *returnSize = 2; int *a = (int *)malloc(sizeof(int) * 2); for(i = 0;i<numsSize;i++) { for(j=i+1;j<numsSize;j++) { i
-
C++求两数之和并返回下标详解
目录 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标. ACM模式 核心代码模式 方法一: 创建vector 添加元素 删除元素 其他 方法二: auto的使用 unordered_map 查找元素是否存在 若有unordered_map <int, int> mp;查找x是否在map中 类 总结: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 tar
-
C#算法之两数之和
题目 给定一个整数数组 nums和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个数组中同样的元素. 示例: 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9所以返回 [0, 1] 提示:不能自身相加. 测试用例 [2,7,11,15] 9 预期结果 [0,1] 格式模板 public class S
-
C++实现LeetCode(三数之和)
Given an array S of n integers, are there elements a, b, c in S such that a + b + c = 0? Find all unique triplets in the array which gives the sum of zero. Note: Elements in a triplet (a,b,c) must be in non-descending order. (ie, a ≤ b ≤ c) The solut