Java内存模型之重排序的相关知识总结
一、数据依赖性
如果两个操作访问同一个变量,而且这两个操作中有一个操作为写操作,此时这两个操作之间存在数据依赖性。数据依赖性分为三种,如表所示:
| 名称 | 代码示例 | 说明 |
|---|---|---|
| 写后读 | a=1;b=a; | 写一个变量后,再读这个位置 |
| 写后写 | a=1;a=2; | 写一个变量后,在写这个变量 |
| 读后写 | a=b;b=1; | 读一个变量后,再写这个变量 |
上面的这三种情况,只要重排序了两个操作的执行顺序,程序的执行结果就会被改变。编译器和处理器针对单个处理器中执行的指令序列和单个线程中执行的操作重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。(不同处理器和不同线程之间的数据依赖性不被编译器和处理器考虑)。
二、as-if-serial语义
as-if-serial语义指的是:不管怎么重排序,单线程执行程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为 这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
举例说明,计算圆面积的代码示例:
double pi = 3.14; // A double r = 1.0; // B double area = pi * r; // C
上面3个操作的数据依赖关系如下所示:

3个操作之间的依赖关系
解释:A和B之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不可能被排到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可重排序A和B之间的执行顺序。
重排序后存在如下的执行可能:

总结:as-if-serial语义吧单线程程序保护起来了,遵守as-if-serial语义的编译器、runtime和处理器共同为编写单线程程序的程序员创建了一个错误的幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
三、程序顺序规则
根据happens-before的程序规则,上面计算圆的面积的示例代码存在3个happens-before关系。
1.A happens-before B
2.B happens-before C
3.A happens-before C
A happens-before C是根据1和2推导出来的。
虽然A happens-before B但是实际执行时B却可以排在A前面执行(在上面的执行图中)。如果A happens-before B,JMM并不要求A一定要在B之前执行,JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里A的执行结果不需要对B可见;而且重排序操作A和操作B后的执行结果,与A和操作B按happens-before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法(not illegal),JMM运行这种重排序。
在计算机中,软件技术和硬件技术有一个共同目标:再不改变程序执行结果的前提下,尽可能提高并行度。编译器和处理区遵从这一目标,从happens-before的定义我们可以看出,JMM同样也遵循这一目标。
四、重排序对多线程的影响
重排序是否会影响多线程的执行结果呢?
package com.lizba.p1;
/**
* <p>
*
* </p>
*
* @Author: Liziba
* @Date: 2021/6/7 23:01
*/
public class ReorderExample {
// 定义变量a
int a = 0;
// flag变量是个标记,用来标志变量a是否被写入
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
System.out.println("i:" + i);
}
}
/**
* 测试
*
* @param args
*/
public static void main(String[] args) {
final ReorderExample re = new ReorderExample();
new Thread() {
public void run() {
re.writer();
}
}.start();
new Thread() {
public void run() {
re.reader();
}
}.start();
}
}
这里假设两个线程A和B,A首先执行write(),B再执行readr()。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入呢?
答案是:不一定能!
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以多这两个操作重排序。
假设操作1和操作2重排序:(虚箭线代表错误的读操作)

程序执行时序图
如上图操作1和操作2发生了重排序。程序执行时,线程A首先写标记变量flag,随后线程B读取这个变量,条件判断为真,线程B读取变量a的值。此时,变量a还没有被线程A写入,在这里多线程程序的语义被重排序破坏了。
假设操作3和操作4重排序:
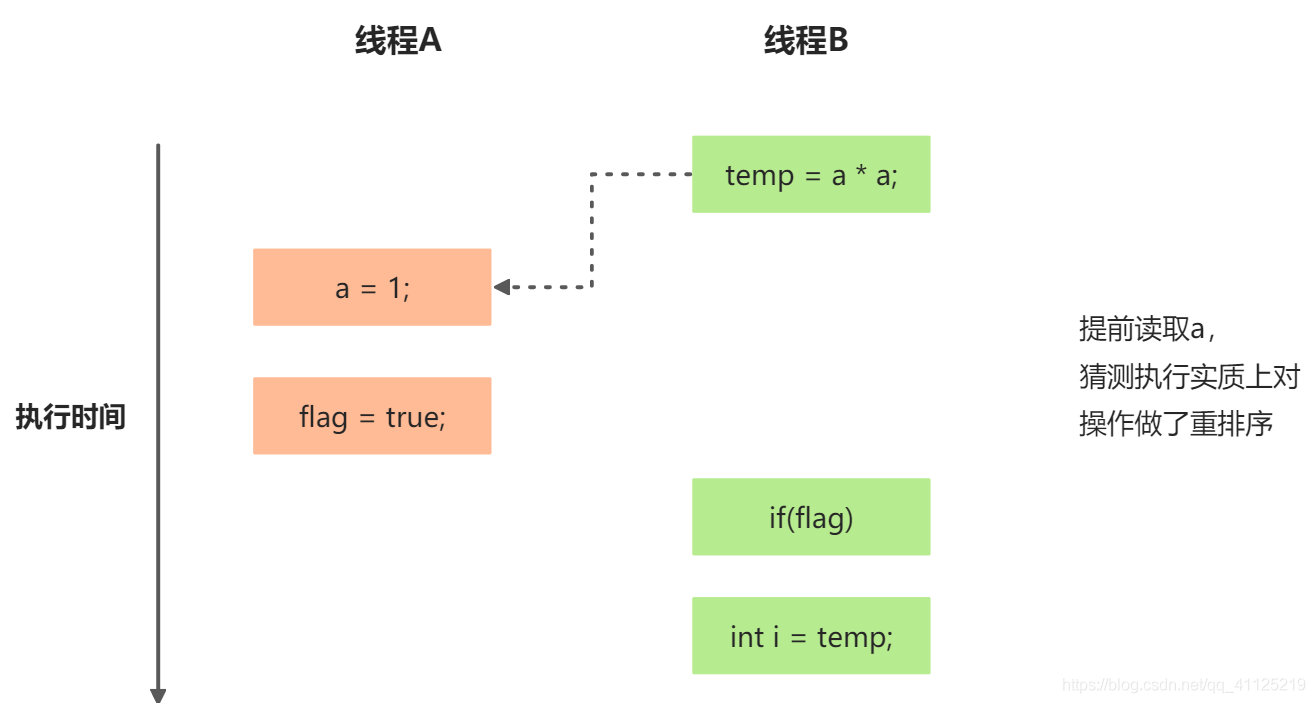
程序执行时序图
在上述执行方式的程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令并行度。为此编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行现场B的处理器可提前读取并行计算a*a,然后计算结果保存到一个名为重排序缓冲(Recorder Buffer, ROB)的硬件缓存中。当操作3的条件判断为真时,就把计算结果写入变量i中。
在上图中可以看出,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义!
在单线程程序中,对存在控制依赖性的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但是在多线程中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
到此这篇关于Java内存模型之重排序的相关知识总结的文章就介绍到这了,更多相关Java重排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
海量数据去重排序bitmap(位图法)在java中实现的两种方法
在海量数据中查找出重复出现的元素或者去除重复出现的元素是面试中常考的文图.针对此类问题,可以使用位图法来解决.例如:已知某个文件内包含若干个电话号码,要求统计不同的号码的个数,甚至在O(n)时间复杂度内对这些号码进行排序. 位图法需要的空间很少(依赖于数据分布,但是我们也可以通过一些放啊发对数据进行处理,使得数据变得密集),在数据比较密集的时候效率非常高.例如:8位整数可以表示的最大十进制数值为99999999,如果每个数组对应于一个bit位,那么把所有的八进制整数存储起来只需要:99Mbit
-
浅谈java指令重排序的问题
指令重排序是个比较复杂.觉得有些不可思议的问题,同样是先以例子开头(建议大家跑下例子,这是实实在在可以重现的,重排序的概率还是挺高的),有个感性的认识 /** * 一个简单的展示Happen-Before的例子. * 这里有两个共享变量:a和flag,初始值分别为0和false.在ThreadA中先给 a=1,然后flag=true. * 如果按照有序的话,那么在ThreadB中如果if(flag)成功的话,则应该a=1,而a=a*1之后a仍然为1,下方的if(a==0)应该永远不会为 * 真,
-

Java 改造ayui表格组件实现多重排序
实现思路也比较简单,只需要用一个数组来存放所有排序的列,再把这个数组传到后端(后端排序)进行排序即可.沿用一般的使用习惯,按住 shift 键点击表头可增加排序列,按住 ctrl 键点击表头可减少排序列.话不多说,先上最终效果图: 1. 定义排序列数组 我当前用的是 2.5.6 版本,源码之前为适应业务需求也做过相应修改,所以下文说到的行数只是个大概数. 为兼容之前单列排序的使用习惯,我们增加一个 multiSort 的配置属性,默认为 false,为 true 时才开启多列排序.修改源码大概第
-
JAVA中JVM的重排序详细介绍
在并发程序中,程序员会特别关注不同进程或线程之间的数据同步,特别是多个线程同时修改同一变量时,必须采取可靠的同步或其它措施保障数据被正确地修改,这里的一条重要原则是:不要假设指令执行的顺序,你无法预知不同线程之间的指令会以何种顺序执行. 但是在单线程程序中,通常我们容易假设指令是顺序执行的,否则可以想象程序会发生什么可怕的变化.理想的模型是:各种指令执行的顺序是唯一且有序的,这个顺序就是它们被编写在代码中的顺序,与处理器或其它因素无关,这种模型被称作顺序一致性模型,也是基于冯·诺依曼体系的模型.
-
Java内存之happens-before和重排序
happens-before原则规则: 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作: 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作: volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作: 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C: 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作: 线程中断规则:对线程interrup
-
Java内存模型之重排序的相关知识总结
一.数据依赖性 如果两个操作访问同一个变量,而且这两个操作中有一个操作为写操作,此时这两个操作之间存在数据依赖性.数据依赖性分为三种,如表所示: 名称 代码示例 说明 写后读 a=1;b=a; 写一个变量后,再读这个位置 写后写 a=1;a=2; 写一个变量后,在写这个变量 读后写 a=b;b=1; 读一个变量后,再写这个变量 上面的这三种情况,只要重排序了两个操作的执行顺序,程序的执行结果就会被改变.编译器和处理器针对单个处理器中执行的指令序列和单个线程中执行的操作重排序时,会遵守数据依赖性,
-
Java内存模型可见性问题相关解析
这篇文章主要介绍了Java内存模型可见性问题相关解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 前言 之前的文章中讲到,JMM是内存模型规范在Java语言中的体现.JMM保证了在多核CPU多线程编程环境下,对共享变量读写的原子性.可见性和有序性. 本文就具体来讲讲JMM是如何保证共享变量访问的可见性的. 什么是可见性问题 我们从一段简单的代码来看看到底什么是可见性问题. public class VolatileDemo { boolean
-
Java内存模型相关知识总结
[1]CPU和缓存的一致性 我们应该都知道,计算机在执行程序的时候,每条指令都是在CPU中执行的,而执行的时候,又免不了要和数据打交道.而计算机上面的数据,是存放在主存当中的,也就是计算机的物理内存啦. 刚开始,还相安无事的,但是随着CPU技术的发展,CPU的执行速度越来越快.而由于内存的技术并没有太大的变化,所以从内存中读取和写入数据的过程和CPU的执行速度比起来差距就会越来越大,这就导致CPU每次操作内存都要耗费很多等待时间. 所以,人们想出来了一个好的办法,就是在CPU和内存之间增
-
Java内存模型知识汇总
为什么要有内存模型 在介绍Java内存模型之前,先来看一下到底什么是计算机内存模型,然后再来看Java内存模型在计算机内存模型的基础上做了哪些事情.要说计算机的内存模型,就要说一下一段古老的历史,看一下为什么要有内存模型. 内存模型,英文名Memory Model,他是一个很老的老古董了.他是与计算机硬件有关的一个概念.那么我先给你介绍下他和硬件到底有啥关系. CPU和缓存一致性 我们应该都知道,计算机在执行程序的时候,每条指令都是在CPU中执行的,而执行的时候,又免不了要和数据打交道.而计算机
-
Java内存模型知识详解
1. 概述 多任务和高并发是衡量一台计算机处理器的能力重要指标之一.一般衡量一个服务器性能的高低好坏,使用每秒事务处理数(Transactions Per Second,TPS)这个指标比较能说明问题,它代表着一秒内服务器平均能响应的请求数,而TPS值与程序的并发能力有着非常密切的关系.在讨论Java内存模型和线程之前,先简单介绍一下硬件的效率与一致性. 2.硬件的效率与一致性 由于计算机的存储设备与处理器的运算能力之间有几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理
-
Java内存模型之happens-before概念详解
简介 happens-before是JMM的核心概念.理解happens-before是了解JMM的关键. 1.设计意图 JMM的设计需要考虑两个方面,分别是程序员角度和编译器.处理器角度: 程序员角度,希望内存模型易于理解.易于编程.希望是一个强内存模型. 编译器和处理器角度,希望减少对它们的束缚,以至于编译器和处理器可以做更多的性能优化.希望是一个弱内存模型. 因此JSR-133专家组设计JMM的核心目标就两个: 为程序员提供足够强的内存模型对编译器和处理器的限制尽可能少 下面通过一段代
-
详细分析Java内存模型
目录 一.为什么要学习并发编程 二.为什么需要并发编程 三.从物理机中得到启发 四.Java 内存模型 五.原子性 5.1.什么是原子性 5.2.如何保证原子性 六.可见性 6.1.什么是可见性 6.2.如何保证可见性 七.有序性 7.1.什么是有序性 7.2.如何保证有序性 一.为什么要学习并发编程 对于 "我们为什么要学习并发编程?" 这个问题,就好比 "我们为什么要学习政治?" 一样,我们(至少作为学生党是这样)平常很少接触到,然后背了一堆 "正确且
-
Java 内存模型(JMM)
目录 四.Happens-Before 规则 Java 内存模型 一.什么是 Java 内存模型 Java 内存模型定义如下: 内存模型限制的是共享变量,也就是存储在堆内存中的变量,在 Java 语言中,所有的实例变量.静态变量和数组元素都存储在堆内存之中.而方法参数.异常处理参数这些局部变量存储在方法栈帧之中,因此不会在线程之间共享,不会受到内存模型影响,也不存在内存可见性问题. 通常,在线程之间的通讯方式有共享内存和消息传递两种,很明显,Java 采用的是第一种即共享的内存模型,在共享的内存
-
并发编程之Java内存模型volatile的内存语义
1.volatile的特性 理解volatile特性的一个好办法是把对volatile变量的单个读/写,看成是使用同一个锁对单个读/写操作做了同步. 代码示例: package com.lizba.p1; /** * <p> * volatile示例 * </p> * * @Author: Liziba * @Date: 2021/6/9 21:34 */ public class VolatileFeatureExample { /** 使用volatile声明64位的long型
-
并发编程之Java内存模型顺序一致性
目录 1.数据竞争和顺序一致性 1.1 Java内存模型规范对数据竞争的定义 1.2 JMM对多线程程序的内存一致性做的保证 2.顺序一致性内存模型 2.1 特性 2.2 举例说明顺序一致性模型 2.3 同步程序的顺序一致性效果 2.4 未同步程序的执行特性 3. 64位long型和double型变量写原子性 3.1 CPU.内存和总线简述 3.2 long和double类型的操作 简介: 顺序一致性内存模型是一个理论参考模型,处理器的内存模型和编程语言的内存模型都会以顺序一致性内存模型作为参照