使用Python Pandas处理亿级数据的方法
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章《别老扯什么Hadoop了,你的数据根本不够大》指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择。这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据:
硬件环境
- CPU:3.5 GHz Intel Core i7
- 内存:32 GB HDDR 3 1600 MHz
- 硬盘:3 TB Fusion Drive
数据分析工具
- Python:2.7.6
- Pandas:0.15.0
- IPython notebook:2.0.0
源数据如下表所示:
| Table | Size | Desc | |
|---|---|---|---|
| ServiceLogs | 98,706,832 rows x 14 columns | 8.77 GB | 交易日志数据,每个交易会话可以有多条交易 |
| ServiceCodes | 286 rows × 8 columns | 20 KB | 交易分类的字典表 |
数据读取
启动IPython notebook,加载pylab环境:
ipython notebook --pylab=inline
Pandas提供了IO工具可以将大文件分块读取,测试了一下性能,完整加载9800万条数据也只需要263秒左右,还是相当不错了。
import pandas as pd
reader = pd.read_csv('data/servicelogs', iterator=True)
try:
df = reader.get_chunk(100000000)
except StopIteration:
print "Iteration is stopped."
| 1百万条 | 1千万条 | 1亿条 | |
|---|---|---|---|
| ServiceLogs | 1 s | 17 s | 263 s |
使用不同分块大小来读取再调用pandas.concat连接DataFrame,chunkSize设置在1000万条左右速度优化比较明显。
loop = True
chunkSize = 100000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print "Iteration is stopped."
df = pd.concat(chunks, ignore_index=True)
下面是统计数据,Read Time是数据读取时间,Total Time是读取和Pandas进行concat操作的时间,根据数据总量来看,对5~50个DataFrame对象进行合并,性能表现比较好。
Chunk Size
Read Time (s)
Total Time (s)
Performance100,000224.418173261.358521200,000232.076794256.6741541,000,000213.128481234.934142√√2,000,000208.410618230.006299√√√5,000,000209.460829230.939319√√√10,000,000207.082081228.135672√√√√20,000,000209.628596230.775713√√√50,000,000222.910643242.405967100,000,000263.574246263.574246
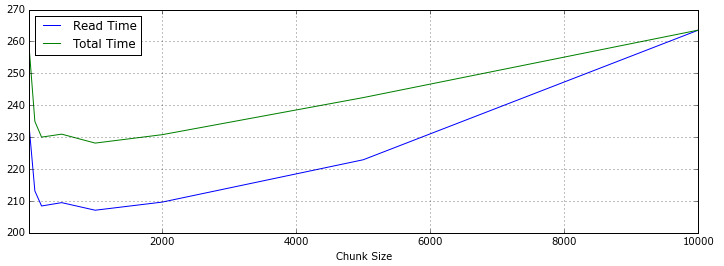
如果使用Spark提供的Python Shell,同样编写Pandas加载数据,时间会短25秒左右,看来Spark对Python的内存使用都有优化。
数据清洗
Pandas提供了DataFrame.describe方法查看数据摘要,包括数据查看(默认共输出首尾60行数据)和行列统计。由于源数据通常包含一些空值甚至空列,会影响数据分析的时间和效率,在预览了数据摘要后,需要对这些无效数据进行处理。
首先调用DataFrame.isnull()方法查看数据表中哪些为空值,与它相反的方法是DataFrame.notnull(),Pandas会将表中所有数据进行null计算,以True/False作为结果进行填充,如下图所示:
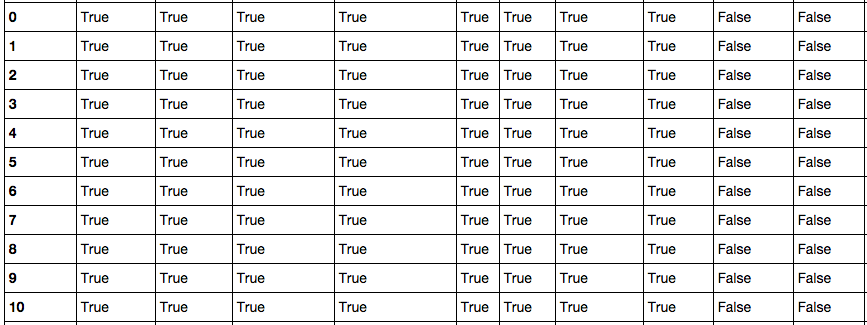
Pandas的非空计算速度很快,9800万数据也只需要28.7秒。得到初步信息之后,可以对表中空列进行移除操作。尝试了按列名依次计算获取非空列,和DataFrame.dropna()两种方式,时间分别为367.0秒和345.3秒,但检查时发现 dropna() 之后所有的行都没有了,查了Pandas手册,原来不加参数的情况下, dropna() 会移除所有包含空值的行。如果只想移除全部为空值的列,需要加上 axis 和 how 两个参数:
df.dropna(axis=1, how='all')
共移除了14列中的6列,时间也只消耗了85.9秒。
接下来是处理剩余行中的空值,经过测试,在DataFrame.replace()中使用空字符串,要比默认的空值NaN节省一些空间;但对整个CSV文件来说,空列只是多存了一个“,”,所以移除的9800万 x 6列也只省下了200M的空间。进一步的数据清洗还是在移除无用数据和合并上。
对数据列的丢弃,除无效值和需求规定之外,一些表自身的冗余列也需要在这个环节清理,比如说表中的流水号是某两个字段拼接、类型描述等,通过对这些数据的丢弃,新的数据文件大小为4.73GB,足足减少了4.04G!
数据处理
使用DataFrame.dtypes可以查看每列的数据类型,Pandas默认可以读出int和float64,其它的都处理为object,需要转换格式的一般为日期时间。DataFrame.astype()方法可对整个DataFrame或某一列进行数据格式转换,支持Python和NumPy的数据类型。
df['Name'] = df['Name'].astype(np.datetime64)
对数据聚合,我测试了 DataFrame.groupby 和 DataFrame.pivot_table 以及 pandas.merge ,groupby 9800万行 x 3列的时间为99秒,连接表为26秒,生成透视表的速度更快,仅需5秒。
df.groupby(['NO','TIME','SVID']).count() # 分组
fullData = pd.merge(df, trancodeData)[['NO','SVID','TIME','CLASS','TYPE']] # 连接
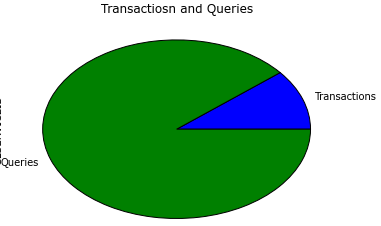
actions = fullData.pivot_table('SVID', columns='TYPE', aggfunc='count') # 透视表
根据透视表生成的交易/查询比例饼图:
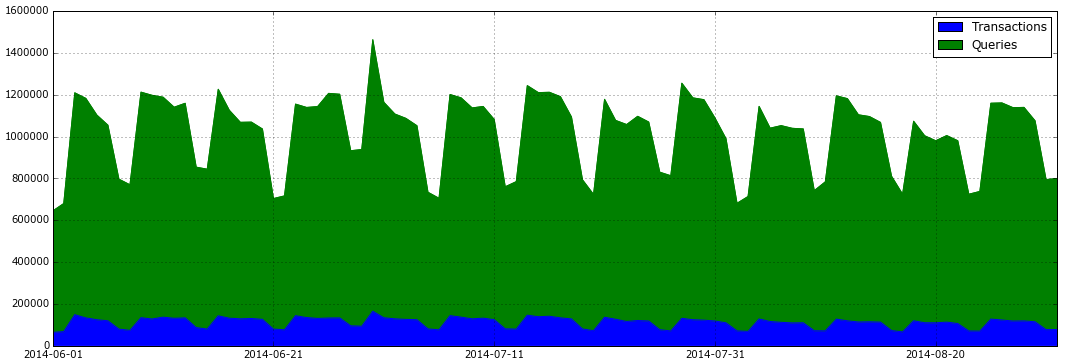
将日志时间加入透视表并输出每天的交易/查询比例图:
total_actions = fullData.pivot_table('SVID', index='TIME', columns='TYPE', aggfunc='count')
total_actions.plot(subplots=False, figsize=(18,6), kind='area')
除此之外,Pandas提供的DataFrame查询统计功能速度表现也非常优秀,7秒以内就可以查询生成所有类型为交易的数据子表:
tranData = fullData[fullData['Type'] == 'Transaction']
该子表的大小为[10250666 rows x 5 columns]。在此已经完成了数据处理的一些基本场景。实验结果足以说明,在非“>5TB”数据的情况下,Python的表现已经能让擅长使用统计分析语言的数据分析师游刃有余。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

在Python中利用Pandas库处理大数据的简单介绍
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬
-
Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
Python 数据处理库 pandas进阶教程
前言 本文紧接着前一篇的入门教程,会介绍一些关于pandas的进阶知识.建议读者在阅读本文之前先看完pandas入门教程. 同样的,本文的测试数据和源码可以在这里获取: Github:pandas_tutorial. 数据访问 在入门教程中,我们已经使用过访问数据的方法.这里我们再集中看一下. 注:这里的数据访问方法既适用于Series,也适用于DataFrame. 基础方法:[]和. 这是两种最直观的方法,任何有面向对象编程经验的人应该都很容易理解.下面是一个代码示例: # select_da
-
python使用pandas处理大数据节省内存技巧(推荐)
一般来说,用pandas处理小于100兆的数据,性能不是问题.当用pandas来处理100兆至几个G的数据时,将会比较耗时,同时会导致程序因内存不足而运行失败. 当然,像Spark这类的工具能够胜任处理100G至几个T的大数据集,但要想充分发挥这些工具的优势,通常需要比较贵的硬件设备.而且,这些工具不像pandas那样具有丰富的进行高质量数据清洗.探索和分析的特性.对于中等规模的数据,我们的愿望是尽量让pandas继续发挥其优势,而不是换用其他工具. 本文我们讨论pandas的内存使用,展示怎样
-
使用Python Pandas处理亿级数据的方法
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬盘:3 TB Fusion Drive 数据分析
-
Python pandas库中isnull函数使用方法
前言: python的pandas库中有⼀个⼗分便利的isnull()函数,它可以⽤来判断缺失值,我们通过⼏个例⼦学习它的使⽤⽅法.⾸先我们创建⼀个dataframe,其中有⼀些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[7,
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成
-
Python pandas求方差和标准差的方法实例
目录 准备 1.求方差 1.1对全表进行操作 1.1.1求取每列的方差 1.1.2 求取每行的方差 1.2 对单独的一行或者一列进行操作 1.2.1 求取单独某一列的方差 1.2.2 求取单独某一行的方差 1.3 对多行或者多列进行操作 1.3.1 求取多列的方差 1.3.2 求取多行的方差 2 求标准差 2.1对全表进行操作 2.1.1对每一列求标准差 2.1.2 对每一行求标准差 2.2 对单独的一行或者一列进行操作 2.2.1 对某一列求标准差 2.2.2 对某一行求标准差 2.3 对多行
-
Python pandas索引的设置和修改方法
目录 前言 创建索引 pd.Index pd.IntervalIndex pd.CategoricalIndex pd.DatetimeIndex pd.PeriodIndex pd.TimedeltaIndex 读取数据 set_index reset_index set_axis 操作行索引 操作列索引 rename 字典形式 函数形式 使用案例 按日统计总消费 按日.性别统计小费均值,消费总和 笨方法 总结 前言 本文主要是介绍Pandas中行和列索引的4个函数操作: set_index
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
python pandas dataframe 行列选择,切片操作方法
SQL中的select是根据列的名称来选取:Pandas则更为灵活,不但可根据列名称选取,还可以根据列所在的position(数字,在第几行第几列,注意pandas行列的position是从0开始)选取.相关函数如下: 1)loc,基于列label,可选取特定行(根据行index): 2)iloc,基于行/列的position: 3)at,根据指定行index及列label,快速定位DataFrame的元素: 4)iat,与at类似,不同的是根据position来定位的: 5)ix,为loc与i
-
python pandas 组内排序、单组排序、标号的实例
摘要:本文主要是讲解一下,如何进行排序.分为两种情况,不分组进行排序和组内进行排序.什么意思呢?具体来说,我举个栗子. ****注意**** 如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了.下文是关于如何把序号也打上的 ---------------------------- 我们有一个数据集如下: 我们下面想进行两种排序.先说第一种比较简单的也是很常用的,简单的对某一列进行排序然后添加一列序号. 例如,我们队comment_num这一列进行从大到小的
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
Python之pandas读写文件乱码的解决方法
python读写文件有时候会出现 'XXX'编码不能打开XXX什么的,用记事本打开要读取的文件,另存为UTF-8编码,然后再用py去读应该可以了.如果还不行,那么尝试使用文件原有的编码方式读取,参考之前的文章 在pandas中读写csv时候通过制定encoding可以有效防止excel打开或者写入中文乱码 data.to_csv(f_out,index=False,encoding='gb2312') 以上这篇Python之pandas读写文件乱码的解决方法就是小编分享给大家的全部内容了,希