浅析Python的对象拷贝和内存布局
目录
- 前言
- Python 对象的内存布局
- 牛刀小试
- 查看对象的内存地址
- copy模块
- 可变和不可变对象与对象拷贝
- 代码片段分析
- 撕开 Python 对象的神秘面纱
- 总结
前言
在本篇文章当中主要给大家介绍 python 当中的拷贝问题,话不多说我们直接看代码,你知道下面一些程序片段的输出结果吗?
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
a = [1, 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4]
b = copy.copy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4]
b = copy.deepcopy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
在本篇文章当中我们将对上面的程序进行详细的分析。
Python 对象的内存布局
在 python 当中我们应该如何确定一个对象的内存地址呢?在 Python 当中给我们提供了一个内嵌函数 id() 用于得到一个对象的内存地址:
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
print(f"{id(a) = } \t|\t {id(b) = }")
# 输出结果
# a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
# a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
# id(a) = 4393578112 | id(b) = 4393578112
事实上上面的对象内存布局是有一点问题的,或者说是不够准确的,但是也是能够表示出各个对象之间的关系的,我们现在来深入了解一下。在 Cpython 里你可以认为每一个变量都可以认为是一个指针,指向被表示的那个数据,这个指针保存的就是这个 Python 对象的内存地址。
在 Python 当中,实际上列表保存的指向各个 Python 对象的指针,而不是实际的数据,因此上面的一小段代码,可以用如下的图表示对象在内存当中的布局:
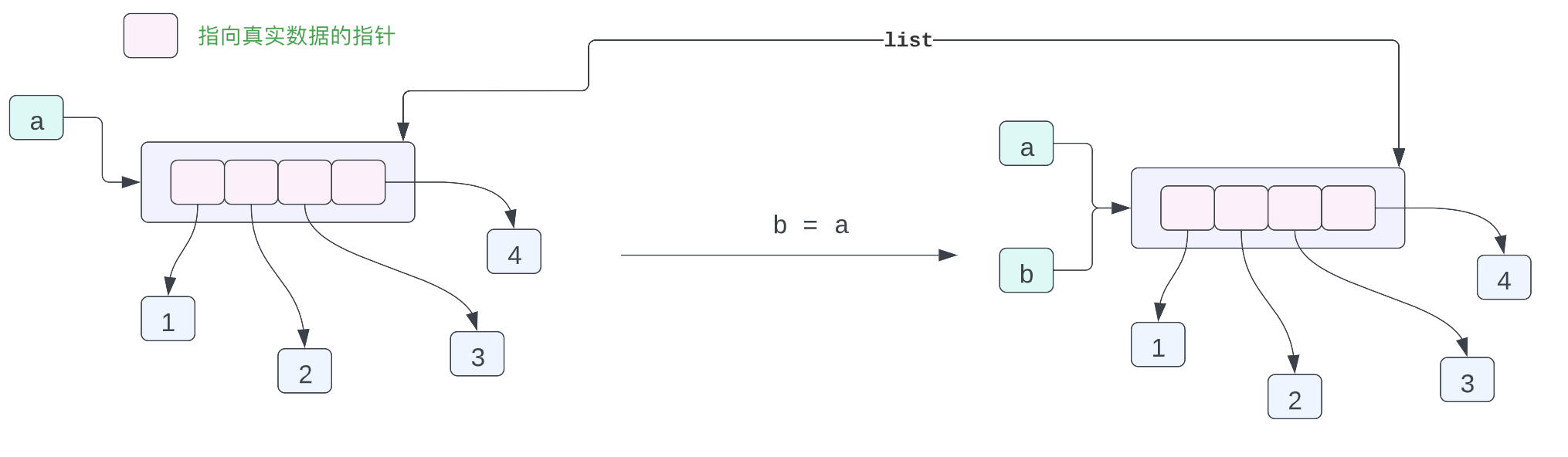
变量 a 指向内存当中的列表 [1, 2, 3, 4],列表当中有 4 个数据,这四个数据都是指针,而这四个指针指向内存当中 1,2,3,4 这四个数据。可能你会有疑问,这不是有问题吗?都是整型数据为什么不直接在列表当中存放整型数据,为啥还要加一个指针,再指向这个数据呢?
事实上在 Python 当中,列表当中能够存放任何 Python 对象,比如下面的程序是合法的:
data = [1, {1:2, 3:4}, {'a', 1, 2, 25.0}, (1, 2, 3), "hello world"]
在上面的列表当中第一个到最后一个数据的数据类型为:整型数据,字典,集合,元祖,字符串,现在来看为了实现 Python 的这个特性,指针的特性是不是符合要求呢?每个指针所占用的内存是一样的,因此可以使用一个数组去存储 Python 对象的指针,然后再将这个指针指向真正的 Python 对象!
牛刀小试
在经过上面的分析之后,我们来看一下下面的代码,他的内存布局是什么情况:
data = [[1, 2, 3], 4, 5, 6] data_assign = data data_copy = data.copy()
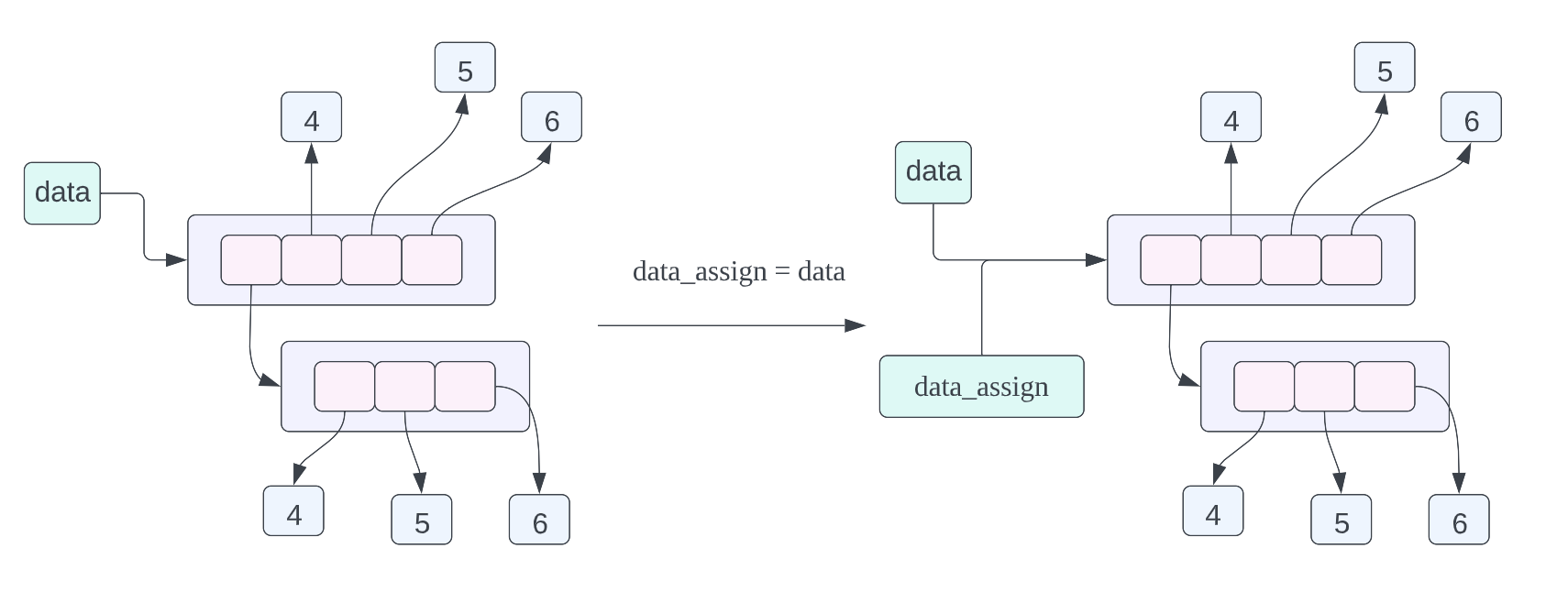
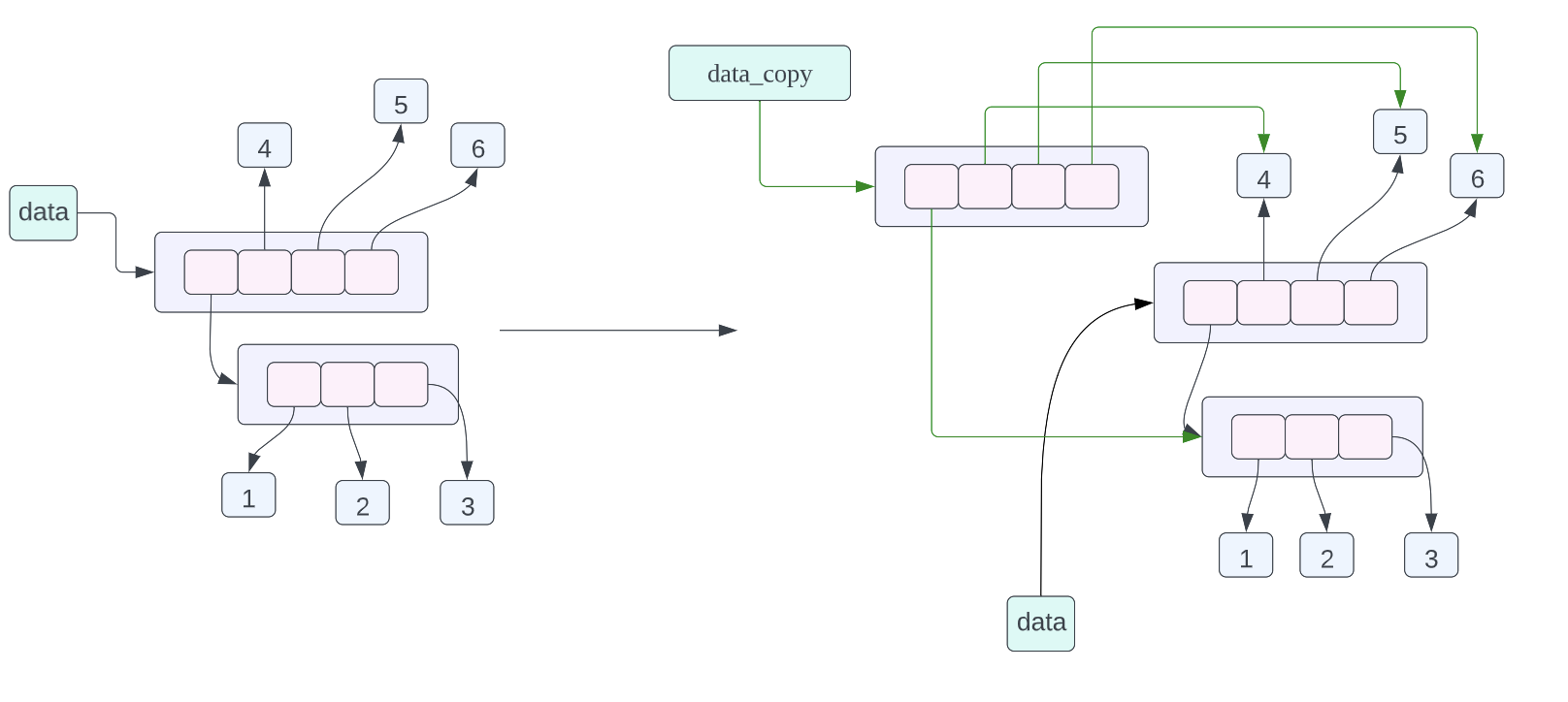
data_assign = data,关于这个赋值语句的内存布局我们在之前已经谈到过了,不过我们也再复习一下,这个赋值语句的含义就是 data_assign 和 data 指向的数据是同一个数据,也就是同一个列表。data_copy = data.copy(),这条赋值语句的含义是将 data 指向的数据进行浅拷贝,然后让 data_copy 指向拷贝之后的数据,这里的浅拷贝的意思就是,对列表当中的每一个指针进行拷贝,而不对列表当中指针指向的数据进行拷贝。从上面的对象的内存布局图我们可以看到 data_copy 指向一个新的列表,但是列表当中的指针指向的数据和 data 列表当中的指针指向的数据是一样的,其中 data_copy 使用绿色的箭头进行表示,data 使用黑色的箭头进行表示。
查看对象的内存地址
在前面的文章当中我们主要分析了一下对象的内存布局,在本小节我们使用 python 给我们提供一个非常有效的工具去验证这一点。在 python 当中我们可以使用 id() 去查看对象的内存地址,id(a) 就是查看对象 a 所指向的对象的内存地址。
看下面的程序的输出结果:
a = [1, 2, 3]
b = a
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a[i]) = } {id(b[i]) = }")
根据我们之前的分析,a 和 b 指向的同一块内存,也就说两个变量指向的是同一个 Python 对象,因此上面的多有输出的 id 结果 a 和 b 都是相同的,上面的输出结果如下:
id(a) = 4392953984 id(b) = 4392953984
i = 0 id(a[i]) = 4312613104 id(b[i]) = 4312613104
i = 1 id(a[i]) = 4312613136 id(b[i]) = 4312613136
i = 2 id(a[i]) = 4312613168 id(b[i]) = 4312613168
看一下浅拷贝的内存地址:
a = [[1, 2, 3], 4, 5]
b = a.copy()
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a[i]) = } {id(b[i]) = }")
根据我们在前面的分析,调用列表本身的 copy 方法是对列表进行浅拷贝,只拷贝列表的指针数据,并不拷贝列表当中指针指向的真正的数据,因此如果我们对列表当中的数据进行遍历得到指向的对象的地址的话,列表 a 和列表 b 返回的结果是一样的,但是和上一个例子不同的是 a 和 b 指向的列表的本身的地址是不一样的(因为进行了数据拷贝,可以参照下面浅拷贝的结果进行理解)。
可以结合下面的输出结果和上面的文字进行理解:
id(a) = 4392953984 id(b) = 4393050112 # 两个对象的输出结果不相等 i = 0 id(a[i]) = 4393045632 id(b[i]) = 4393045632 # 指向的是同一个内存对象因此内存地址相等 下同 i = 1 id(a[i]) = 4312613200 id(b[i]) = 4312613200 i = 2 id(a[i]) = 4312613232 id(b[i]) = 4312613232
copy模块
在 python 里面有一个自带的包 copy ,主要是用于对象的拷贝,在这个模块当中主要有两个方法 copy.copy(x) 和 copy.deepcopy()。
copy.copy(x) 方法主要是用于浅拷贝,这个方法的含义对于列表来说和列表本身的 x.copy() 方法的意义是一样的,都是进行浅拷贝。这个方法会构造一个新的 python 对象并且会将对象 x 当中所有的数据引用(指针)拷贝一份。
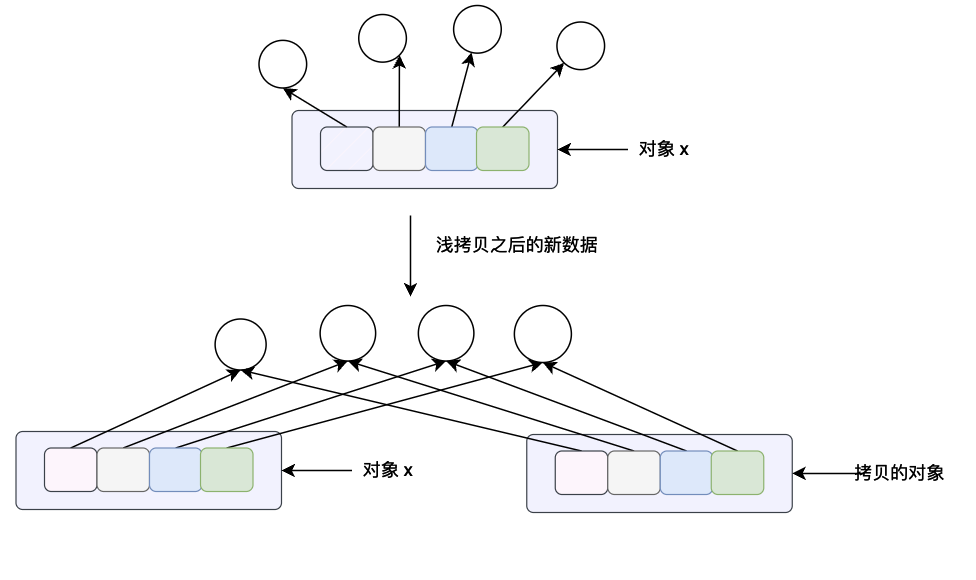
copy.deepcopy(x) 这个方法主要是对对象 x 进行深拷贝,这里的深拷贝的含义是会构造一个新的对象,会递归的查看对象 x 当中的每一个对象,如果递归查看的对象是一个不可变对象将不会进行拷贝,如果查看到的对象是可变对象的话,将重新开辟一块内存空间,将原来的在对象 x 当中的数据拷贝的新的内存当中。(关于可变和不可变对象我们将在下一个小节仔细分析)
根据上面的分析我们可以知道深拷贝的花费是比浅拷贝多的,尤其是当一个对象当中有很多子对象的时候,会花费很多时间和内存空间。
对于 python 对象来说进行深拷贝和浅拷贝的区别主要在于复合对象(对象当中有子对象,比如说列表,元祖、类的实例等等)。这一点主要是和下一小节的可变和不可变对象有关系。
可变和不可变对象与对象拷贝
在 python 当中主要有两大类对象,可变对象和不可变对象,所谓可变对象就是对象的内容可以发生改变,不可变对象就是对象的内容不能够发生改变。
- 可变对象:比如说列表(list),字典(dict),集合(set),字节数组(bytearray),类的实例对象。
- 不可变对象:整型(int),浮点型(float),复数(complex),字符串,元祖(tuple),不可变集合(frozenset),字节(bytes)。
看到这里你可能会有疑问了,整数和字符串不是可以修改吗?
a = 10 a = 100 a = "hello" a = "world"
比如下面的代码是正确的,并不会发生错误,但是事实上其实 a 指向的对象是发生了变化的,第一个对象指向整型或者字符串的时候,如果重新赋一个新的不同的整数或者字符串对象的话,python 会创建一个新的对象,我们可以使用下面的代码进行验证:
a = 10
print(f"{id(a) = }")
a = 100
print(f"{id(a) = }")
a = "hello"
print(f"{id(a) = }")
a = "world"
print(f"{id(a) = }")
上面的程序的输出结果如下所示:
id(a) = 4365566480
id(a) = 4365569360
id(a) = 4424109232
id(a) = 4616350128
可以看到的是当重新赋值之后变量指向的内存对象是发生了变化的(因为内存地址发生了变化),这就是不可变对象,虽然可以对变量重新赋值,但是得到的是一个新对象并不是在原来的对象上进行修改的!
我们现在来看一下可变对象列表发生修改之后内存地址是怎么发生变化的:
data = []
print(f"{id(data) = }")
data.append(1)
print(f"{id(data) = }")
data.append(1)
print(f"{id(data) = }")
data.append(1)
print(f"{id(data) = }")
data.append(1)
print(f"{id(data) = }")
上面的代码输出结果如下所示:
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
从上面的输出结果来看可以知道,当我们往列表当中加入新的数据之后(修改了列表),列表本身的地址并没有发生变化,这就是可变对象。
我们在前面谈到了深拷贝和浅拷贝,我们现在来分析一下下面的代码:
data = [1, 2, 3]
data_copy = copy.copy(data)
data_deep = copy.deepcopy(data)
print(f"{id(data ) = } | {id(data_copy) = } | {id(data_deep) = }")
print(f"{id(data[0]) = } | {id(data_copy[0]) = } | {id(data_deep[0]) = }")
print(f"{id(data[1]) = } | {id(data_copy[1]) = } | {id(data_deep[1]) = }")
print(f"{id(data[2]) = } | {id(data_copy[2]) = } | {id(data_deep[2]) = }")
上面的代码输出结果如下所示:
id(data ) = 4620333952 | id(data_copy) = 4619860736 | id(data_deep) = 4621137024
id(data[0]) = 4365566192 | id(data_copy[0]) = 4365566192 | id(data_deep[0]) = 4365566192
id(data[1]) = 4365566224 | id(data_copy[1]) = 4365566224 | id(data_deep[1]) = 4365566224
id(data[2]) = 4365566256 | id(data_copy[2]) = 4365566256 | id(data_deep[2]) = 4365566256
看到这里你肯定会非常疑惑,为什么深拷贝和浅拷贝指向的内存对象是一样的呢?前列我们可以理解,因为浅拷贝拷贝的是引用,因此他们指向的对象是同一个,但是为什么深拷贝之后指向的内存对象和浅拷贝也是一样的呢?这正是因为列表当中的数据是整型数据,他是一个不可变对象,如果对 data 或者 data_copy 指向的对象进行修改,那么将会指向一个新的对象并不会直接修改原来的对象,因此对于不可变对象其实是不用开辟一块新的内存空间在重新赋值的,因为这块内存中的对象是不会发生改变的。
我们再来看一个可拷贝的对象:
data = [[1], [2], [3]]
data_copy = copy.copy(data)
data_deep = copy.deepcopy(data)
print(f"{id(data ) = } | {id(data_copy) = } | {id(data_deep) = }")
print(f"{id(data[0]) = } | {id(data_copy[0]) = } | {id(data_deep[0]) = }")
print(f"{id(data[1]) = } | {id(data_copy[1]) = } | {id(data_deep[1]) = }")
print(f"{id(data[2]) = } | {id(data_copy[2]) = } | {id(data_deep[2]) = }")
上面的代码输出结果如下所示:
id(data ) = 4619403712 | id(data_copy) = 4617239424 | id(data_deep) = 4620032640
id(data[0]) = 4620112640 | id(data_copy[0]) = 4620112640 | id(data_deep[0]) = 4620333952
id(data[1]) = 4619848128 | id(data_copy[1]) = 4619848128 | id(data_deep[1]) = 4621272448
id(data[2]) = 4620473280 | id(data_copy[2]) = 4620473280 | id(data_deep[2]) = 4621275840
从上面程序的输出结果我们可以看到,当列表当中保存的是一个可变对象的时候,如果我们进行深拷贝将创建一个全新的对象(深拷贝的对象内存地址和浅拷贝的不一样)。
代码片段分析
经过上面的学习对于在本篇文章开头提出的问题对于你来说应该是很简单的,我们现在来分析一下这几个代码片段:
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
这个很简单啦,a 和 b 不同的变量指向同一个列表,a 中间的数据发生变化,那么 b 的数据也会发生变化,输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
id(a) = 4614458816 | id(b) = 4614458816
我们再来看一下第二个代码片段
a = [1, 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
因为 b 是 a 的一个浅拷贝,所以 a 和 b 指向的是不同的列表,但是列表当中数据的指向是相同的,但是由于整型数据是不可变数据,当a[0] 发生变化的时候,并不会修改原来的数据,而是会在内存当中创建一个新的整型数据,因此列表 b 的内容并不会发生变化。因此上面的代码输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4] a = [100, 2, 3, 4] | b = [1, 2, 3, 4]
再来看一下第三个片段:
a = [[1, 2, 3], 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
这个和第二个片段的分析是相似的,但是 a[0] 是一个可变对象,因此进行数据修改的时候,a[0] 的指向没有发生变化,因此 a 修改的内容会影响 b。
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[100, 2, 3], 2, 3, 4]
最后一个片段:
a = [[1, 2, 3], 2, 3, 4]
b = copy.deepcopy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")
深拷贝会在内存当中重新创建一个和a[0]相同的对象,并且让 b[0] 指向这个对象,因此修改 a[0],并不会影响 b[0],因此输出结果如下所示:
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4]
撕开 Python 对象的神秘面纱
我们现在简要看一下 Cpython 是如何实现 list 数据结构的,在 list 当中到底定义了一些什么东西:
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;
在上面定义的结构体当中 :
allocated 表示分配的内存空间的数量,也就是能够存储指针的数量,当所有的空间用完之后需要再次申请内存空间。
ob_item 指向内存当中真正存储指向 python 对象指针的数组,比如说我们想得到列表当中第一个对象的指针的话就是 list->ob_item[0],如果要得到真正的数据的话就是 *(list->ob_item[0])。
PyObject_VAR_HEAD 是一个宏,会在结构体当中定一个子结构体,这个子结构体的定义如下:
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
这里我们不去谈对象 PyObject 了,主要说一下 ob_size,他表示列表当中存储了多少个数据,这个和 allocated 不一样,allocated 表示 ob_item 指向的数组一共有多少个空间,ob_size 表示这个数组存储了多少个数据 ob_size <= allocated。
在了解列表的结构体之后我们现在应该能够理解之前的内存布局了,所有的列表并不存储真正的数据而是存储指向这些数据的指针。
总结
在本篇文章当中主要给大家介绍了 python 当中对象的拷贝和内存布局,以及对对象内存地址的验证,最后稍微介绍了一下 cpython 内部实现列表的结构体,帮助大家深入理解列表对象的内存布局。
到此这篇关于浅析Python的对象拷贝和内存布局的文章就介绍到这了,更多相关Python对象拷贝 内存布局内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中的对象拷贝示例 python引用传递
何谓引用传递,我们来看一个C++交换两个数的函数: 复制代码 代码如下: void swap(int &a, int &b){ int temp; temp = a; a = b; b = temp;} 这个例子就是一个引用传递的例子!目的是说明一下概念:引用传递的意思就是说你传递的是对象的引用,对这个引用的修改也会导致原有对象的改变.学过C/C++的朋友们都知道,在交换2个数的时候,如果自己实现一个swap函数,需要传递其引用或者指针. Python直接使用引用传
-

Python万字深入内存管理讲解
目录 Python内存管理 一.对象池 1.小整数池 2.大整数池 3.inter机制(短字符串池) 二.垃圾回收 2.1.引用计数 2.1.1 引用计数增加 2.1.2 引用计数减少 2.2.标记清除 2.3.分代回收 2.3.1 分代回收触发时机?(GC阈值) 2.3.2 查看引用计数(gc模块的使用) 三.怎么优化内存管理 1.手动垃圾回收 2.调高垃圾回收阈值 3.避免循环引用 四.总结 Python内存管理 一.对象池 1.小整数池 系统默认创建好的,等着你使用 概述: 整数在程序中的
-
Python对象的深拷贝和浅拷贝详解
本文内容是在<Python核心编程2>上看到的,感觉很有用便写出来,给大家参考参考! 浅拷贝 首先我们使用两种方式来拷贝对象,一种是切片,另外一种是工厂方法.然后使用id函数来看看它们的标示符 复制代码 代码如下: # encoding=UTF-8 obj = ['name',['age',18]] a=obj[:] b=list(obj) for x in obj,a,b: print id(x) 35217032 35227912 29943304 他们的id都不同,按照正
-
Python 拷贝对象(深拷贝deepcopy与浅拷贝copy)
1. copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象.2. copy.deepcopy 深拷贝 拷贝对象及其子对象一个很好的例子: Code highlighting produced by Actipro CodeHighlighter (freeware) http://www.CodeHighlighter.com/ -->import copya = [1, 2, 3, 4, ['a', 'b']] #原始对象b = a #赋值,传对象的引用c = copy.c
-
Python超详细讲解内存管理机制
目录 什么是内存管理机制 一.引用计数机制 二.数据池和缓存 什么是内存管理机制 python中创建的对象的时候,首先会去申请内存地址,然后对对象进行初始化,所有对象都会维护在一 个叫做refchain的双向循环链表中,每个数据都保存如下信息: 1. 链表中数据前后数据的指针 2. 数据的类型 3. 数据值 4. 数据的引用计数 5. 数据的长度(list,dict..) 一.引用计数机制 引用计数增加: 1.1 对象被创建 1.2 对象被别的变量引用(另外起了个名字) 1.3 对象被作为元素,
-
浅析Python的对象拷贝和内存布局
目录 前言 Python 对象的内存布局 牛刀小试 查看对象的内存地址 copy模块 可变和不可变对象与对象拷贝 代码片段分析 撕开 Python 对象的神秘面纱 总结 前言 在本篇文章当中主要给大家介绍 python 当中的拷贝问题,话不多说我们直接看代码,你知道下面一些程序片段的输出结果吗? a = [1, 2, 3, 4] b = a print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }
-
深入浅析Python获取对象信息的函数type()、isinstance()、dir()
type()函数: 使用type()函数可以判断对象的类型,如果一个变量指向了函数或类,也可以用type判断. 如: class Student(object): name = 'Student' a = Student() print(type(123)) print(type('abc')) print(type(None)) print(type(abs)) print(type(a)) 运行截图如下: 可以看到返回的是对象的类型. 我们可以在if语句中判断比较两个变量的type类型是否相
-
关于C++对象继承中的内存布局示例详解
前言 本文给大家介绍的是关于C++对象继承的内存布局的相关内容,分享出来供大家参考学习,在开始之前说明下,关于单继承和多继承的简单概念可参考此文章 以下编译环境均为:WIN32+VS2015 虚函数表 对C++ 了解的人都应该知道虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的.简称为V-Table.在这个表中,主是要一个类的虚函数的地址表,这张表解决了继承.覆盖的问题,保证其容真实反应实际的函数. 首先先通过一个例子来引入虚函数表,假如现在有三
-
详解Java对象创建的过程及内存布局
一.对象的内存布局 对象头 对象头主要保存对象自身的运行时数据和用于指定该对象属于哪个类的类型指针. 实例数据 保存对象的有效数据,例如对象的字段信息,其中包括从父类继承下来的. 对齐填充 对齐填充不是必须存在的,没有特别的含义,只起到一个占位符的作用. 二.对象的创建过程 实例化一个类的对象的过程是一个典型的递归过程. 在准备实例化一个类的对象前,首先准备实例化该类的父类,如果该类的父类还有父类,那么准备实例化该类的父类的父类,依次递归直到递归到Object类. 此时,首先实例化Object类
-
Java 对象在 JVM 中的内存布局超详细解说
目录 一.new 对象的几种说法 二.Java 对象在内存中的存在形式 1. 栈帧(Frame) 2. 对象在内存中的存在形式 ① 3. 对象中的方法存储在那儿? 4. Java 对象在内存中的存在形式 ② 三.类中属性详细说明 四.细小知识点 1. 如何创建对象 2. 如何访问属性 五.Exercise 六.总结 一.new 对象的几种说法 初学 Java 面向对象的时候,实例化对象的说法有很多种,我老是被这些说法给弄晕. public class Test { public static v
-
浅析Python 中整型对象存储的位置
在 Python 整型对象所存储的位置是不同的, 有一些是一直存储在某个存储里面, 而其它的, 则在使用时开辟出空间. 说这句话的理由, 可以看看如下代码: a = 5 b = 5 a is b # True a = 500 b = 500 a is b # False 由上面的代码可知, 整型 5 是一直存在的, 而整型 500 不是一直存在的. 那么有哪些整数是一直存储的呢? a, b, c = 0, 0, 0 while a is b: i += 1 a, b = int(str(i)),
-
浅析内存对齐与ANSI C中struct型数据的内存布局
这些问题或许对不少朋友来说还有点模糊,那么本文就试着探究它们背后的秘密. 首先,至少有一点可以肯定,那就是ANSI C保证结构体中各字段在内存中出现的位置是随它们的声明顺序依次递增的,并且第一个字段的首地址等于整个结构体实例的首地址.比如有这样一个结构体: 复制代码 代码如下: struct vector{int x,y,z;} s; int *p,*q,*r; struct vector *ps; p = &s.x; q = &s.y; r = &s.z; ps =
-
浅谈C++中派生类对象的内存布局
主要从三个方面来讲: 1 单一继承 2 多重继承 3 虚拟继承 1 单一继承 (1)派生类完全拥有基类的内存布局,并保证其完整性. 派生类可以看作是完整的基类的Object再加上派生类自己的Object.如果基类中没有虚成员函数,那么派生类与具有相同功能的非派生类将不带来任何性能上的差异.另外,一定要保证基类的完整性.实际内存布局由编译器自己决定,VS里,把虚指针放在最前边,接着是基类的Object,最后是派生类自己的object.举个栗子: class A { int b; char c; }
-
深入理解JVM之Java对象的创建、内存布局、访问定位详解
本文实例讲述了深入理解JVM之Java对象的创建.内存布局.访问定位.分享给大家供大家参考,具体如下: 对象的创建 一个简单的创建对象语句Clazz instance = new Clazz();包含的主要过程包括了类加载检查.对象分配内存.并发处理.内存空间初始化.对象设置.执行ini方法等. 主要流程如下: 1. 类加载检查 JVM遇到一条new指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载.解析和初始化过.如果没有,那必须先执
-
浅析鸿蒙基础之Permanent 持久性内存对象(HarmonyOS鸿蒙开发基础知识)
HarmonyOS是一款"面向未来".面向全场景(移动办公.运动健康.社交通信.媒体娱乐等)的分布式操作系统.在传统的单设备系统能力的基础上,HarmonyOS提出了基于同一套系统能力.适配多种终端形态的分布式理念,能够支持多种终端设备. Permanent 持久性内存对象 注释持久性内存对象. 您可以使用此类在新语句中将一个对象注释为持久性内存对象,这样该对象将不会被Ark编译器的RC回收. 参考代码 以" Integer.java"文件中的" Inte