python因子分析的实例
目录
- 一、起源
- 二、基本思想
- 三、算法用途
- 四、因子分析步骤
- 五、factor_analyzer库
- 六、实例详解
- 1.导入库
- 2.读取数据
- 3.充分性检测
- 3.1 Bartlett's球状检验
- 3.2 KMO检验
- 4.选择因子个数
- 4.1 特征值和特征向量
- 4.2 可视化展示
- 4.3可视化中显示中文不报错
- 5.因子旋转
- 5.1建立因子分析模型
- 5.2 查看因子方差-get_communalities()
- 5.3 查看旋转后的特征值
- 5.4 查看成分矩阵
- 5.5 查看因子贡献率
- 6.隐藏变量可视化
- 7.转成新变量
- 七、参考资料
一、起源
因子分析的起源是这样的:1904年英国的一个心理学家发现学生的英语、法语和古典语成绩非常有相关性,他认为这三门课程背后有一个共同的因素驱动,最后将这个因素定义为“语言能力”。
基于这个想法,发现很多相关性很高的因素背后有共同的因子驱动,从而定义了因子分析,这便是因子分析的由来。
二、基本思想
我们再通过一个更加实际的例子来理解因子分析的基本思想:
现在假设一个同学的数学、物理、化学、生物都考了满分,那么我们可以认为这个学生的理性思维比较强,在这里理性思维就是我们所说的一个因子。在这个因子的作用下,偏理科的成绩才会那么高。
到底什么是因子分析?就是假设现有全部自变量x的出现是因为某个潜在变量的作用,这个潜在的变量就是我们说的因子。在这个因子的作用下,x能够被观察到。
因子分析就是将存在某些相关性的变量提炼为较少的几个因子,用这几个因子去表示原本的变量,也可以根据因子对变量进行分类。
因子分子本质上也是降维的过程,和主成分分析(PCA)算法比较类似。
三、算法用途
因子分析法和主成分分析法有很多类似之处。因子分析的主要目的是用来描述隐藏在一组测量到的变量中的一些更基本的,但又无法直接测量到的隐性变量。因子分析法也可以用来综合评价。
其主要思路是利用研究指标的之间存在一定的相关性,从而推想是否存在某些潜在的共性因子,而这些不同的潜在的共性因子不同程度地共同影响着研究指标。因子分析可以在许多变量中找出隐藏的具有代表性的因子,将共同本质的变量归入一个因子,可以减少变量的数目。
四、因子分析步骤
应用因子分析法的主要步骤如下:
- 对所给的数据样本进行标准化处理
- 计算样本的相关矩阵R
- 求相关矩阵R的特征值、特征向量
- 根据系统要求的累积贡献度确定主因子的个数
- 计算因子载荷矩阵A
- 最终确定因子模型
五、factor_analyzer库
利用Python进行因子分析的核心库是:factor_analyzer
pip install factor_analyzer
这个库主要有两个主要的模块需要学习:
- factor_analyzer.analyze(重点)
- factor_analyzer.factor_analyzer
官网学习地址:factor_analyzer package — factor_analyzer 0.3.1 documentation
六、实例详解
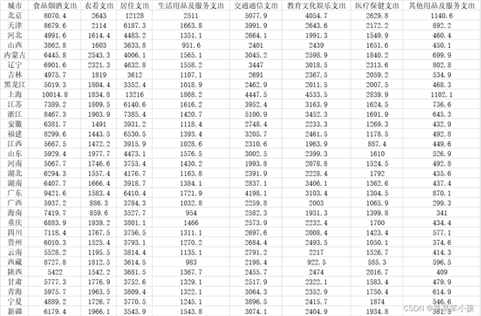
数据来源于中国统计年鉴。
1.导入库
# 数据处理 import pandas as pd import numpy as np # 绘图 import seaborn as sns import matplotlib.pyplot as plt # 因子分析 from factor_analyzer import FactorAnalyzer
2.读取数据
df = pd.read_csv("D:\桌面\demo.csv",encoding='gbk')
df
输出:

如果不想要城市那一列的话,可以在读取的时候就删除,也可以后面再删
比如,读取时删除
df = pd.read_csv("D:\桌面\demo.csv", index_col=0,encoding='gbk').reset_index(drop=True)
df
返回:

然后我们查询一下,数据的缺失值情况:
df.isnull().sum()
返回:

然后,我们可以针对的,对数据进行一次处理:
比如删除无效字段的那一列
# 去掉无效字段 df.drop(["变量名1","变量名2","变量名3"],axis=1,inplace=True)
或者,删除空值
# 去掉空值 df.dropna(inplace=True)
3.充分性检测
在进行因子分析之前,需要先进行充分性检测,主要是检验相关特征阵中各个变量间的相关性,是否为单位矩阵,也就是检验各个变量是否各自独立。
3.1 Bartlett's球状检验
检验总体变量的相关矩阵是否是单位阵(相关系数矩阵对角线的所有元素均为1,所有非对角线上的元素均为零);即检验各个变量是否各自独立。
如果不是单位矩阵,说明原变量之间存在相关性,可以进行因子分子;反之,原变量之间不存在相关性,数据不适合进行主成分分析
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity chi_square_value, p_value = calculate_bartlett_sphericity(df) chi_square_value, p_value
返回:

3.2 KMO检验
检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
通常取值从0.6开始进行因子分析
#KMO检验 from factor_analyzer.factor_analyzer import calculate_kmo kmo_all,kmo_model=calculate_kmo(df) kmo_model
返回:

通过结果可以看到KMO大于0.6,也说明变量之间存在相关性,可以进行分析。
4.选择因子个数
方法:计算相关矩阵的特征值,进行降序排列
4.1 特征值和特征向量
faa = FactorAnalyzer(25,rotation=None) faa.fit(df) # 得到特征值ev、特征向量v ev,v=faa.get_eigenvalues() print(ev,v)
返回:

4.2 可视化展示
将特征值和因子个数的变化绘制成图形:
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), ev)
plt.plot(range(1, df.shape[1] + 1), ev)
# 显示图的标题和xy轴的名字
# 最好使用英文,中文可能乱码
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid() # 显示网格
plt.show() # 显示图形
返回:

从上面的图形中,我们明确地看到:选择2或3个因子就可以了
4.3 可视化中显示中文不报错
只需要在画图前,再导入一个库即可,见代码
import matplotlib as mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
5.因子旋转
5.1 建立因子分析模型
在这里选择,最大方差化因子旋转
# 选择方式: varimax 方差最大化 # 选择固定因子为 2 个 faa_two = FactorAnalyzer(2,rotation='varimax') faa_two.fit(df)
返回:

ratation参数的其他取值情况:
- varimax (orthogonal rotation)
- promax (oblique rotation)
- oblimin (oblique rotation)
- oblimax (orthogonal rotation)
- quartimin (oblique rotation)
- quartimax (orthogonal rotation)
- equamax (orthogonal rotation)
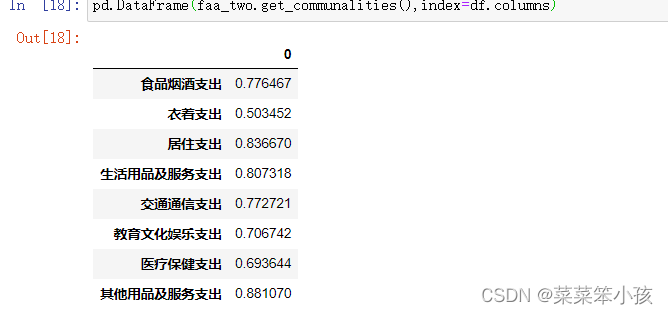
5.2 查看因子方差-get_communalities()
查看公因子方差
# 公因子方差 faa_two.get_communalities()
返回:

查看每个变量的公因子方差数据
pd.DataFrame(faa_two.get_communalities(),index=df.columns)
返回:
5.3 查看旋转后的特征值
faa_two.get_eigenvalues()
返回:

pd.DataFrame(faa_two.get_eigenvalues())
返回:

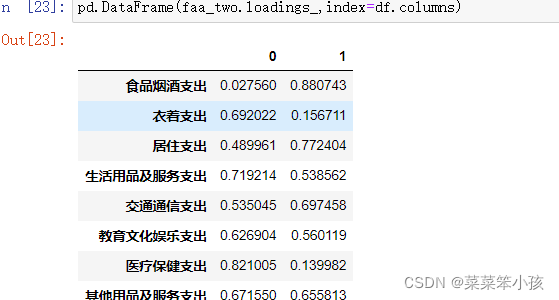
5.4 查看成分矩阵
查看它们构成的成分矩阵:
# 变量个数*因子个数 faa_two.loadings_
返回:

如果转成DataFrame格式,index就是我们的变量,columns就是指定的因子factor。转DataFrame格式后的数据:
pd.DataFrame(faa_two.loadings_,index=df.columns)
返回:
5.5 查看因子贡献率
通过理论部分的解释,我们发现每个因子都对变量有一定的贡献,存在某个贡献度的值,在这里查看3个和贡献度相关的指标:
- 总方差贡献:variance (numpy array) – The factor variances
- 方差贡献率:proportional_variance (numpy array) – The proportional factor variances
- 累积方差贡献率:cumulative_variances (numpy array) – The cumulative factor variances
我们来看一下总方差贡献吧
faa_two.get_factor_variance()
返回:

6.隐藏变量可视化
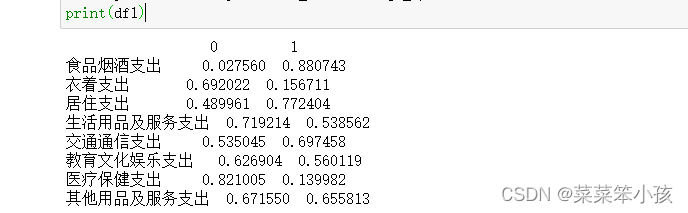
为了更直观地观察每个隐藏变量和哪些特征的关系比较大,进行可视化展示,为了方便取上面相关系数的绝对值:
df1 = pd.DataFrame(np.abs(faa_two.loadings_),index=df.columns) print(df1)
返回:
然后我们通过热力图将系数矩阵绘制出来:
# 绘图
plt.figure(figsize = (14,14))
ax = sns.heatmap(df1, annot=True, cmap="BuPu")
# 设置y轴字体大小
ax.yaxis.set_tick_params(labelsize=15)
plt.title("Factor Analysis", fontsize="xx-large")
# 设置y轴标签
plt.ylabel("Sepal Width", fontsize="xx-large")
# 显示图片
plt.show()
# 保存图片
# plt.savefig("factorAnalysis", dpi=500)
返回:

7.转成新变量
上面我们已经知道了2个因子比较合适,可以将原始数据转成2个新的特征,具体转换方式为:
faa_two.transform(df)
返回:
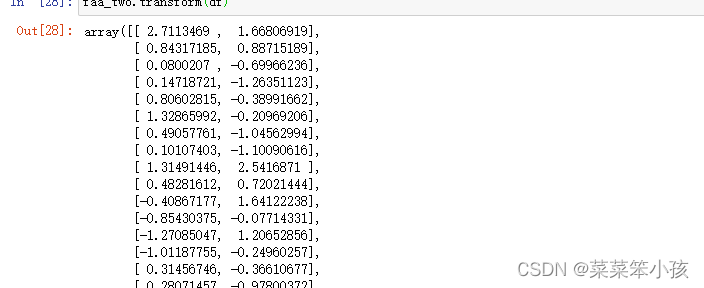
转成DataFrame格式后数据展示效果更好:
df2 = pd.DataFrame(faa_two.transform(df)) print(df2)
返回:

七、参考资料
1、Factor Analysis:Factor Analysis with Python — DataSklr
2、多因子分析:因子分析(factor analysis)例子–Python | 文艺数学君
3、factor_analyzer package的官网使用手册:factor_analyzer package — factor_analyzer 0.3.1 documentation
4、浅谈主成分分析和因子分析:浅谈主成分分析与因子分析 - 知乎
到此这篇关于python因子分析的实例的文章就介绍到这了,更多相关python 因子分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
用Python的SimPy库简化复杂的编程模型的介绍
在我遇到 SimPy 包的其中一位创始人 Klaus Miller 时,从他那里知道了这个包.Miller 博士阅读过几篇提出使用 Python 2.2+ 生成器实现半协同例程和"轻便"线程的技术的 可爱的 Python专栏文章.特别是(使我很高兴的是),他发现在用 Python 实现 Simula-67 样式模拟时,这些技术很有用. 结果表明 Tony Vignaux 和 Chang Chui 以前曾创建了另一个 Python 库,它在概念上更接近于 Simscript,而且该库使用
-

python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
Python时间序列处理之ARIMA模型的使用讲解
ARIMA模型 ARIMA模型的全称是自回归移动平均模型,是用来预测时间序列的一种常用的统计模型,一般记作ARIMA(p,d,q). ARIMA的适应情况 ARIMA模型相对来说比较简单易用.在应用ARIMA模型时,要保证以下几点: 时间序列数据是相对稳定的,总体基本不存在一定的上升或者下降趋势,如果不稳定可以通过差分的方式来使其变稳定. 非线性关系处理不好,只能处理线性关系 判断时序数据稳定 基本判断方法:稳定的数据,总体上是没有上升和下降的趋势的,是没有周期性的,方差趋向于一个稳定的值. A
-
python构建指数平滑预测模型示例
指数平滑法 其实我想说自己百度的- 只有懂的人才会找到这篇文章- 不懂的人-看了我的文章-还是不懂哈哈哈 指数平滑法相比于移动平均法,它是一种特殊的加权平均方法.简单移动平均法用的是算术平均数,近期数据对预测值的影响比远期数据要大一些,而且越近的数据影响越大.指数平滑法正是考虑了这一点,并将其权值按指数递减的规律进行分配,越接近当前的数据,权重越大:反之,远离当前的数据,其权重越小.指数平滑法按照平滑的次数,一般可分为一次指数平滑法.二次指数平滑法和三次指数平滑法等.然而一次指数平滑法适用于无趋
-
用Python给文本创立向量空间模型的教程
我们需要开始思考如何将文本集合转化为可量化的东西.最简单的方法是考虑词频. 我将尽量尝试不使用NLTK和Scikits-Learn包.我们首先使用Python讲解一些基本概念. 基本词频 首先,我们回顾一下如何得到每篇文档中的词的个数:一个词频向量. #examples taken from here: http://stackoverflow.com/a/1750187 mydoclist = ['Julie loves me more than Linda loves me', 'Jane
-
深入浅析Python 中的sklearn模型选择
1.主要功能如下: 1.classification分类 2.Regression回归 3.Clustering聚类 4.Dimensionality reduction降维 5.Model selection模型选择 6.Preprocessing预处理 2.主要模块分类: 1.sklearn.base: Base classes and utility function基础实用函数 2.sklearn.cluster: Clustering聚类 3.sklearn.cluster.biclu
-
解决python 无法加载downsample模型的问题
downsample 在最新版本里面修改了位置 from theano.tensor.single import downsample (旧版本) 上面以上的的import会有error raise: from theano.tensor.signal import downsample ImportError: cannot import name 'downsample' 找到from theano.tensor.single import downsample所在文件,如: ...\lib
-
python 机器学习之支持向量机非线性回归SVR模型
本文介绍了python 支持向量机非线性回归SVR模型,废话不多说,具体如下: import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm from sklearn.model_selection import train_test_split def load_data_regression(): ''' 加载用于回归问题的数据集 ''' diabetes =
-
python因子分析的实例
目录 一.起源 二.基本思想 三.算法用途 四.因子分析步骤 五.factor_analyzer库 六.实例详解 1.导入库 2.读取数据 3.充分性检测 3.1 Bartlett's球状检验 3.2 KMO检验 4.选择因子个数 4.1 特征值和特征向量 4.2 可视化展示 4.3可视化中显示中文不报错 5.因子旋转 5.1建立因子分析模型 5.2 查看因子方差-get_communalities() 5.3 查看旋转后的特征值 5.4 查看成分矩阵 5.5 查看因子贡献率 6.隐藏变量可视化
-
python装饰器实例大详解
一.作用域 在python中,作用域分为两种:全局作用域和局部作用域. 全局作用域是定义在文件级别的变量,函数名.而局部作用域,则是定义函数内部. 关于作用域,我们要理解两点: a.在全局不能访问到局部定义的变量 b.在局部能够访问到全局定义的变量,但是不能修改全局定义的变量(当然有方法可以修改) 下面我们来看看下面实例: x = 1 def funx(): x = 10 print(x) # 打印出10 funx() print(x) # 打印出1 如果局部没有定义变量x,那么函数内部会从内往
-
Python 调用Java实例详解
Python 调用Java实例详解 前言: Python 对服务器端编程不如Java 所以这方面可能要调用Java代码 前提: Linux 环境 1 安装 jpype1 安装后测试代码: from jpype import * startJVM(getDefaultJVMPath(), "-ea") java.lang.System.out.println("Hello World") shutdownJVM() 2 调用非jdk的jar包, test.jar 包
-
python 系统调用的实例详解
python 系统调用的实例详解 本文将通过两种方法对python 系统调用进行讲解,包括python使用CreateProcess函数运行其他程序和ctypes模块的实例, 一 python使用CreateProcess函数运行其他程序 >>> import win32process >>> handle = win32process.CreateProcess('c:\\windows\\notepad.exe','',None,None
-
python中类和实例如何绑定属性与方法示例详解
前言 python类与实例的方法的调用中觉得云里雾里,思考之后将自己的想法记录下,一来加深自己理解,巩固自己记忆,而来帮助一些想要学习python的朋友理解这门抽象的语言,由于Python是动态语言,类以及根据类创建的实例可以任意绑定属性以及方法,下面分别介绍. 1.类绑定属性 类绑定属性可以直接在class中定义属性,这种属性是类属. class Student(object): name = 'Student' 这个属性虽然归类所有,但类的所有实例都可以访问到. class Student(
-
Python 实现链表实例代码
Python 实现链表实例代码 前言 算法和数据结构是一个亘古不变的话题,作为一个程序员,掌握常用的数据结构实现是非常非常的有必要的. 实现清单 实现链表,本质上和语言是无关的.但是灵活度却和实现它的语言密切相关.今天用Python来实现一下,包含如下操作: ['addNode(self, data)'] ['append(self, value)'] ['prepend(self, value)'] ['insert(self, index, value)'] ['delNode(self,
-
Python 加密的实例详解
Python 加密的实例详解 hashlib支持md5,sha1,sha256,sha384,sha512,用法和md5一样 import hashlib #hashlib支持md5,sha1,sha256,sha384,sha512,用法和md5一样 m = hashlib.md5() #创建加密对象 m.update(b'password') #对输入内容进行加密, m.digest() #获取二进制加密密文 m.hexdigest() #获取十六进制加密密文 '''''python3默认
-
Python 异常处理的实例详解
Python 异常处理的实例详解 与许多面向对象语言一样,Python 具有异常处理,通过使用 try...except 块来实现. Note: Python v s. Java 的异常处理 Python 使用 try...except 来处理异常,使用 raise 来引发异常.Java 和 C++ 使用 try...catch 来处理异常,使用 throw 来引发异常. 异常在 Python 中无处不在:实际上在标准 Python 库中的每个模块都使用了它们,并且 Python 自已会在许多不
-
Python字符串处理实例详解
Python字符串处理实例详解 一.拆分含有多种分隔符的字符串 1.如何拆分含有多种分隔符的字符串 问题: 我们要把某个字符串依据分隔符号拆分不同的字段,该字符串包含多种不同的分隔符,例如: s = "ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz" 其中;,|,\t 都是分隔符号,如何处理? 方法一: 连续使用str.split()方法,每次处理一种分隔符号 s = "ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz&q
-
gearman的安装启动及python API使用实例
本文讲述了gearman的安装启动及python API使用实例,对于网站建设及服务器维护来说非常有用! 一.概述: Gearman是一款非常优秀的任务分发框架,可以用于分布式计算.具体的gearmand服务的安装启动及gearman的python 模块的安装以及简单示例如下: 操作系统:rnel 5.7 1. 首先,我们需要安装gearmand,在centos和rhel环境下,我们只需运行以下命令: yum install gearmand -y 注意:如果不希望通过yum的方式来安装