联邦学习FedAvg中模型聚合过程的理解分析
目录
- 问题
- 聚合
- 1. 聚合所有客户端
- 2. 仅聚合被选中的客户端
- 3. 选择
问题
联邦学习原始论文中给出的FedAvg的算法框架为:

参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率。
首先是服务器执行以下步骤:

对每一个本地客户端来说,要做的就是更新本地参数,具体来讲:
- 把自己的数据集按照参数B分成若干个块,每一块大小都为B。
- 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w 。
- 更新完后 w w w将被传送到中央服务器,服务器整合所有客户端计算出的 w,得到最新的全局模型参数 wt+1
- 客户端收到服务器发送的最新全局参数模型参数,进行下一次更新。
我们仔细观察server的最后一步:
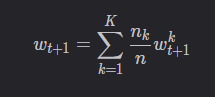

聚合
那么针对聚合,就有以下两种情况。
1. 聚合所有客户端
服务器端每次将新的全局模型发送给全部客户端,并且聚合全部客户端的模型参数。如果客户端未被选中,那么一轮通信结束后,该客户端的模型为一轮通信开始时从服务器获得的初始模型。
设当前全局模型为 wt,服务器选中了 m个客户端(集合V),m个客户端本地更新完毕后,服务器端的聚合公式为:

也就是说,每一次聚合时服务器端都将所有客户端的模型考虑在内。
2. 仅聚合被选中的客户端
服务器每次只是将当前新的参数传递给被选中的模型,并且只是聚合被选中客户端的模型参数。
设当前全局模型为 wt,服务器选中了 m 个客户端(集合V),然后将wt只发送给这 m个客户端。 m m m个客户端训练完毕后,服务器端的聚合公式为:

3. 选择
虽然原始论文中对所有K个客户端都进行了聚合,但在真正实现时,感觉用第二种会更好一点,因为如果客户端数量很庞大,每一次通信都会有不小的代价,用第二种会明显降低通信成本。
以上就是FedAvg中模型聚合过程的理解分析的详细内容,更多关于FedAvg模型聚合的资料请关注我们其它相关文章!
相关推荐
-

联邦学习神经网络FedAvg算法实现
目录 I. 前言 II. 数据介绍 1. 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 4. 代码实现 4.1 初始化 4.2 服务器端 4.3 客户端 4.4 测试 IV. 实验及结果 V. 源码及数据 I. 前言 联邦学习(Federated Learning) 是人工智能的一个新的分支,这项技术是谷歌2016年于论文 Communication-Efficient Learning of Deep Networks from Decentralized Dat
-
联邦学习论文解读分散数据的深层网络通信
目录 前言 Abstract Introduction Federated Learning Privacy Federated Optimization The FederatedAveraging Algorithm Experimental Results Increasing parallelism Increasing computation per client Can we over-optimize on the client datasets? Conclusions and
-
联邦学习FedAvg中模型聚合过程的理解分析
目录 问题 聚合 1. 聚合所有客户端 2. 仅聚合被选中的客户端 3. 选择 问题 联邦学习原始论文中给出的FedAvg的算法框架为: 参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率. 首先是服务器执行以下步骤: 对每一个本地客户端来说,要做的就是更新本地参数,具体来讲: 把自己的数据集按照参数B分成若干个块,每一块大小都为B. 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w . 更新
-
一起来学习C++中remove与erase的理解
目录 erase简介 remove简介 代码示例 代码分析 remove是如何工作的? remove的工作流程 总结 erase 简介 vector 中 erase 函数原型如下: iterator erase( const_iterator position); iterator erase( const_iterator first, const_iterator last); 用于删除 vector 容器中的一个或者一段元素. 在删除一个元素的时候,其参数为指向相应元素的迭代器:而在删除一
-
PyTorch实现联邦学习的基本算法FedAvg
目录 I. 前言 II. 数据介绍 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 IV. 代码实现 1. 初始化 2. 服务器端 3. 客户端 4. 测试 V. 实验及结果 VI. 源码及数据 I. 前言 在之前的一篇博客联邦学习基本算法FedAvg的代码实现中利用numpy手搭神经网络实现了FedAvg,手搭的神经网络效果已经很好了,不过这还是属于自己造轮子,建议优先使用PyTorch来实现. II. 数据介绍 联邦学习中存在多个客户端,每个客户端都有自己的数据集
-
知识蒸馏联邦学习的个性化技术综述
目录 前言 摘要 I. 引言 II. 个性化需求 III. 方法 A. 添加用户上下文 B. 迁移学习 C. 多任务学习 D. 元学习 E. 知识蒸馏 F. 基础+个性化层 G. 全局模型和本地模型混合 IV. 总结 前言 题目: Survey of Personalization Techniques for FederatedLearning 会议: 2020 Fourth World Conference on Smart Trends in Systems, Security and S
-
FedAvg联邦学习FedProx异质网络优化实验总结
目录 前言 I. FedAvg II. FedProx III. 实验 IV. 总结 前言 题目: Federated Optimization for Heterogeneous Networks 会议: Conference on Machine Learning and Systems 2020 论文地址:Federated Optimization for Heterogeneous Networks FedAvg对设备异质性和数据异质性没有太好的解决办法,FedProx在FedAvg的
-
PyTorch实现FedProx联邦学习算法
目录 I. 前言 III. FedProx 1. 模型定义 2. 服务器端 3. 客户端更新 IV. 完整代码 I. 前言 FedProx的原理请见:FedAvg联邦学习FedProx异质网络优化实验总结 联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的. 数据集为某城市十个地区的风电功率,我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型. III. FedProx 算法伪代码: 1. 模型定义 客户端的模
-
学习Angular中作用域需要注意的坑
Angular作用域 在用angular搭建的网页应用中,作用域(scope)这个概念是贯穿其中的.在angular的视图(view)中的很多指令是会创建一个作用域的,例如 ng-app , ng-controller 等.这个作用域就是我们在写控制器构造函数时注入的 $scope (angular1.2之前的版本),他是视图模型(view model)中的一个概念.我们的数据模型(model)就是定义在作用域中的. Angular作用域的坑 用过angular的人应该都会经过一个过程,就是刚开
-
C# API中模型与它们的接口设计详解
关键要点 可变模型应该具备自我验证的能力,并实现验证接口. 在共享对象时(特别是在跨线程共享时),考虑使用不可变模型. 考虑支持MVVM风格UI的单层和多层撤消. 在实现属性变更通知时避免不必要的内存分配. 不要覆盖模型的Equals和GetHashCode方法. 在传统的MVC.MVP.MVVM.Web MVC这些UI模式中,模型是一个公共元素.虽然有很多文章讨论这些架构中的视图和控制器,但几乎无一涉及模型.在本文中,我们将讨论模型本身以及相应的.NET接口. 我想先定义一些术语,这些术语在其