selenium python 实现基本自动化测试的示例代码
安装selenium
打开命令控制符输入:pip install -U selenium
火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能
Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/
如何使用IDE录制脚本:点击seleniumIDE——点击录制——开始录制——录制完成后点击文件Export Test Case——python/unittest/Webdriver——保存;
安装python
安装的时候,推荐选择“Add exe to path”,将会自动添加Python的程序到环境变量中。然后可以在命令行输入 python -V 检测安装的Python版本。
浏览器内壳:IE、chrome、FireFox、Safari
1、webdriver:用unittest框架写自动化用例(setUp:前置条件,tearDown清场)
import unittest
from selenium import webdriver
class Ranzhi(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox() #选择火狐浏览器
def test_ranzhi(self):
pass
def tearDown(self):
self.driver.quit()#退出浏览器
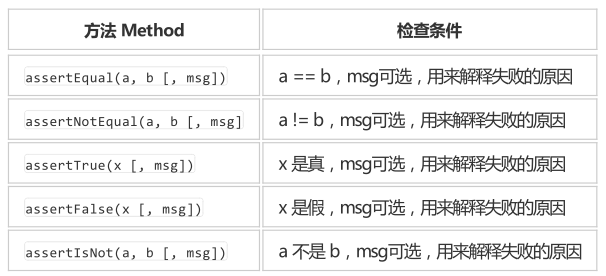
2、断言,检查跳转的网页是否和实际一致
断言网址时需注意是否为伪静态(PATH_INFO)或者GET,前者采用路径传参数(sys/user-creat.html),后者通过字符查询传参数(sys/index.php?m=user&f=index)
当采用不同方式校验网址会发现变化。
self.assertEqual("http://localhost:8080/ranzhi/www/s/index.php?m=index&f=index",
self.driver.current_url, "登录跳转失败")
3、定位元素,在html里面,元素具有各种各样的属性。我们可以通过这样唯一区别其他元素的属性来定位到这个元素.
WebDriver提供了一系列的元素定位方法。常见的有以下几种:id,name,link text,partial link text,xpath,css seletor,class,tag.
self.driver.find_element_by_xpath('//*[@id="s-menu-superadmin"]/button').click()
self.driver.find_element_by_id('account').send_keys('admin')
self.driver.find_element_by_link_text(u'退出').click()
定位元素需注意的问题:
a.时间不够,采用两种方式(self.implicitly_wait(30),sleep(2))
b.函数嵌套(<iframe></iframe>)
# 进入嵌套
self.driver.switch_to.frame('iframe-superadmin')
#退出嵌套
self.driver.switch_to.default_content()
c.flash,验证码(关闭验证码或使用万能码)
d.xpath问题:最好采用最简xpath,当xpath中出现li[10]等时需注意,有时页面定位会出现问题
4、采用CSV存数据
CSV:以纯文本形式存储表格数据(数字和文本),CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。大量程序都支持某种CSV变体,至少是作为一种可选择的输入/输出格式。
melody101,melody101,m,1,3,123456,@qq.com melody102,melody101,f,2,5,123456,@qq.com melody103,melody101,m,3,2,123456,@qq.com
import csv
# 读取CSV文件到user_list字典类型变量中
user_list = csv.reader(open("list_to_user.csv", "r"))
# 遍历整个user_list
for user in user_list:
sleep(2)
self.logn_in('admin', 'admin')
sleep(2)
# 读取一行csv,并分别赋值到user_to_add 中
user_to_add = {'account': user[0],
'realname': user[1],
'gender': user[2],
'dept': user[3],
'role': user[4],
'password': user[5],
'email': user[0] + user[6]}
self.add_user(user_to_add)
5、对下拉列表的定位采用select标签
from selenium.webdriver.support.select import Select
# 选择部门
dp =self.driver.find_element_by_id('dept')
Select(dp).select_by_index(user['dept'])
# 选择角色
Select(self.driver.find_element_by_id('role')).select_by_index(user['role'])
6、模块化代码
需要对自动化重复编写的脚本进行重构(refactor),将重复的脚本抽取出来,放到指定的代码文件中,作为共用的功能模块。使用模块化代码注意需倒入该代码。
#模块化代码后引用,需导入代码模块 from ranzhi_lib import RanzhiLib self.lib = RanzhiLib(self.driver) # 点击后台管理 self.lib.click_admin_app() sleep(2) # 点击添加用户 self.lib.click_add_user() # 添加用户 self.lib.add_user(user_to_add) sleep(1) # 退出 self.lib.logn_out() sleep(2)
class RanzhiLib():
# 构造方法
def __init__(self, driver):
self.driver = driver
7、自定义函数运行的先后顺序:完整的单元测试很少只执行一个测试用例,开发人员通常都需要编写多个测试用例才能对某一软件功能进行比较完整的测试,这些相关的测试用例称为一个测试用例集,在PyUnit中是用TestSuite类来表示,采用unittest.TestSuite()。
PyUnit使用TestRunner类作为测试用例的基本执行环境,来驱动整个单元测试过程。Python开发人员在进行单元测试时一般不直接使用TestRunner类,而是使用其子类TextTestRunner来完成测试。
# 构造测试集
suite = unittest.TestSuite()
suite.addTest(RanzhiTest("test_login"))
suite.addTest(RanzhiTest("test_ranzhi"))
# 执行测试
runner = unittest.TextTestRunner()
runner.run(suite)
以下代码为登录“然之系统”,进入添加用户,循环添加用户并检测添加成功,再退出的过程。以下程序分别为主程序,模块化程序,执行程序,CSV文件
import csv
import unittest
from time import sleep
from selenium import webdriver
# 模块化代码后引用需导入代码模块
from ranzhi_lib import RanzhiLib
class Ranzhi(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.lib = RanzhiLib(self.driver)
# 主函数
def test_ranzhi(self):
# 读取CSV文件到user_list字典类型变量中
user_list = csv.reader(open("list_to_user.csv", "r"))
# 遍历整个user_list
for user in user_list:
sleep(2)
self.lib.logn_in('admin', 'admin')
sleep(2)
# 断言
self.assertEqual("http://localhost:8080/ranzhi/www/sys/index.html",
self.driver.current_url,
'登录跳转失败')
# 读取一行csv,并分别赋值到user_to_add 中
user_to_add = {'account': user[0],
'realname': user[1],
'gender': user[2],
'dept': user[3],
'role': user[4],
'password': user[5],
'email': user[0] + user[6]}
# 点击后台管理
self.lib.click_admin_app()
# 进入嵌套
self.lib.driver.switch_to.frame('iframe-superadmin')
sleep(2)
# 点击添加用户
self.lib.click_add_user()
# 添加用户
self.lib.add_user(user_to_add)
# 退出嵌套
self.driver.switch_to.default_content()
sleep(1)
# 退出
self.lib.logn_out()
sleep(2)
# 用新账号登录
self.lib.logn_in(user_to_add['account'], user_to_add['password'])
sleep(2)
self.lib.logn_out()
sleep(2)
def tearDown(self):
self.driver.quit()
from time import sleep
from selenium.webdriver.support.select import Select
class RanzhiLib():
# 构造方法
def __init__(self, driver):
self.driver = driver
# 模块化添加用户
def add_user(self, user):
driver = self.driver
# 添加用户名
ac = driver.find_element_by_id('account')
ac.send_keys(user['account'])
# 真实姓名
rn = driver.find_element_by_id('realname')
rn.clear()
rn.send_keys(user['realname'])
# 选择性别
if user['gender'] == 'm':
driver.find_element_by_id('gender2').click()
elif user['gender'] == 'f':
driver.find_element_by_id('gender1').click()
# 选择部门
dp = driver.find_element_by_id('dept')
Select(dp).select_by_index(user['dept'])
# 选择角色
role = driver.find_element_by_id('role')
Select(role).select_by_index(user['role'])
# 输入密码
pwd1 = driver.find_element_by_id('password1')
pwd1.clear()
pwd1.send_keys(user['password'])
pwd2 = driver.find_element_by_id('password2')
pwd2.send_keys(user['password'])
# 输入邮箱
em = driver.find_element_by_id('email')
em.send_keys(user['email'])
# 点击保存
driver.find_element_by_id('submit').click()
sleep(2)
# 登录账号
def logn_in(self, name, password):
driver = self.driver
driver.get('http://localhost:8080/ranzhi/www')
sleep(2)
driver.find_element_by_id('account').clear()
driver.find_element_by_id('account').send_keys(name)
driver.find_element_by_id('password').clear()
driver.find_element_by_id('password').send_keys(password)
driver.find_element_by_id('submit').click()
sleep(2)
# 退出账号
def logn_out(self):
self.driver.find_element_by_id('start').click()
sleep(4)
self.driver.find_element_by_link_text(u'退出').click()
sleep(3)
# 点击后台管理
def click_admin_app(self):
self.driver.find_element_by_xpath('//*[@id="s-menu-superadmin"]/button').click()
sleep(1)
def click_add_user(self):
self.driver.find_element_by_xpath('//*[@id="shortcutBox"]/div/div[1]/div/a/h3').click()
sleep(3)
import unittest
from ranzhi import Ranzhi
class RanzhiTestRunner():
def run_tests(self):
suite = unittest.TestSuite()
suite.addTest(Ranzhi('test_ranzhi'))
runner = unittest.TextTestRunner()
runner.run(suite)
if __name__ == "__main__":
ranzhi_test_runner = RanzhiTestRunner()
ranzhi_test_runner.run_tests()
melody109,melody101,m,1,3,123456,@qq.com melody106,melody101,f,2,5,123456,@qq.com melody107,melody101,m,3,2,123456,@qq.com
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python实现报表自动化详解
本篇文章将介绍: xlwt 常用功能 xlrd 常用功能 xlutils 常用功能 xlwt写Excel时公式的应用 xlwt写入特定目录(路径设置) xlwt Python语言中,写入Excel文件的扩展工具.可以实现指定表单.指定单元格的写入.支持excel03版到excel2013版.使用时请确保已经安装python环境 xlrd Python语言中,读取Excel的扩展工具.可以实现指定表单.指定单元格的读取.使用时请确保已经安装python环境. NOTICE: xlwt对Excel只
-
selenium+python实现自动登录脚本
os:windows 前提:Python,selenium,IEDriverServer.exe,ie浏览器 首先安装Python2.7 安装成功后,计算机联网状态下在cmd命令行下输入:pip install -U selenium selenium安装后,在selenium官网下载IEDriverServer.exe 将IEDriverServer.exe放到ie浏览器的安装目录下:C:\Program Files (x86)\Internet Explorer,并将该目录添加到计算机的环境
-
Python实现自动添加脚本头信息的示例代码
前言 每个人写脚本时的格式都会有所不同,有的会注明脚本本身的一些信息,有的则开门见山,这在小团队里其实没什么,基本别人做什么你也都知道,但如果放到大的团队就比较麻烦了,因为随着人数的增多,脚本成指数增长,如果每个人风格不统一,到最后就会造成非常大的弊端,所以当团队人数增长后,就必须有一套标准,形成大家统一的编码规则,这样即使不看脚本具体实现,也知道这个脚本的功能是什么. 我们今天分享的一段脚本是自动添加注释信息的脚本,添加的信息包括脚本名称.作者.时间.描述.脚本用法.语言版本.备注等,下面来看
-
selenium+python实现自动化登录的方法
Selenium Python 提供了一个简单的API 便于我们使用 Selenium WebDriver编写 功能/验收测试. 通过Selenium Python的API,你可以直观地使用所有的 Selenium WebDriver 功能 .Selenium Python提供了一个很方便的接口来驱动 Selenium WebDriver , 例如Firefox.Chrome.Ie,以及Remote,目前支持的python版本有2.7或3.2以上. selenium 可以自动化测试.抢票.爬虫等
-
python http接口自动化脚本详解
今天给大家分享一个简单的python脚本,使用python进行http的接口测试,脚本很简单,逻辑是:读取excel写好的测试用例,然后根据excel中的用例内容进行调用,判断预期结果中的返回值是否和返回报文中的值一致,如果不一致则根据用例标题把bug提交到bug管理系统,这里使用的bug管理系统是bugfree. 实现步骤: 1.读取excel,保存测试用例中的内容: 2.根据excel中的请求url和参数拼接请求报文,调用接口,并保存返回报文: 3.读取返回报文,和预期结果对比,不一致的往b
-
python实现自动化上线脚本的示例
程序说明: 本程序实现将开发程序服务器中的打包文件通过该脚本上传到正式生产环境(注:生产环境和开发环境不互通) 程序基本思路: 将开发环境中的程序包拷贝到本地堡垒机 将程序包进行解压 获得解压后的文件通同步到生产服务器上 主要知识点:python库os.system()的基本使用 利用python调用xshell命令 程序使用方法: python addline.py 开发主机ip 程序包 目标主机ip 上传目录 上传编号 如:python addline.py 240 /home/shaoji
-
selenium+python实现基本自动化测试的示例代码
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/ 如何使用
-
selenium python 实现基本自动化测试的示例代码
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/ 如何使用
-
python+appium实现自动化测试的示例代码
目录 1.什么是Appium 2.启动一个app自动化程序的步骤 3.appium服务介绍 4. appium客户端使用 5.adb的使用 6.Appium启动过程分析 1.什么是Appium appium是一个开源的测试自动化框架,可以与原生的.混合的和移动的web应用程序一直使用.它使用WebDriver协议驱动IOS(内置的测试引擎xcuitest).Android(uiautomator2,Espresso)和Windows应用程序 原生应用程序:安卓程序是用JAVA或kotlin开发出
-
Python与Appium实现手机APP自动化测试的示例代码
目录 1.什么是Appium 2.启动一个app自动化程序的步骤 3.appium服务介绍 4. appium客户端使用 5.adb的使用 6.Appium启动过程分析 1.什么是Appium appium是一个开源的测试自动化框架,可以与原生的.混合的和移动的web应用程序一直使用.它使用WebDriver协议驱动IOS(内置的测试引擎xcuitest).Android(uiautomator2,Espresso)和Windows应用程序 原生应用程序:安卓程序是用JAVA或kotlin开发出
-
Python实现http接口自动化测试的示例代码
网上http接口自动化测试Python实现有很多,我也是在慕课网上学习了相关课程,并实际操作了一遍,于是进行一些总结,便于以后回顾温习,有许多不完善的地方,希望大神们多多指教! 接口测试常用的工具有fiddler,postman,jmeter等,使用这些工具测试时,需要了解常用的接口类型和区别,比如我用到的post和get请求,表面上看get用于获取数据post用于修改数据,两者传递参数的方式也有不一样,get是直接在url里通过?来连接参数,而post则是把数据放在HTTP的包体内(reque
-
C# 利用Selenium实现浏览器自动化操作的示例代码
概述 Selenium是一款免费的分布式的自动化测试工具,支持多种开发语言,无论是C. java.ruby.python.或是C# ,你都可以通过selenium完成自动化测试.本文以一个简单的小例子,简述C# 利用Selenium进行浏览器的模拟操作,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 要实现本例的功能,除了要掌握Html ,JavaScript,CSS等基础知识,还涉及以下知识点: log4net:主要用于日志的记录和存储,本例采用log4net进行日志记录,便于过程跟踪
-
基于Docker+Selenium Grid的测试技术应用示例代码
Selenium Grid介绍 尽管在未来将会推出的Selenium 4.0版本中对Selenium Grid的一些新特性进行了说明,但是目前来看官方并没有太多详细文档供大家参考,所以本书中仍结合目前被广泛使用的Selenium Grid 版本进行讲解. 正如其官网对Selenium Grid的描述,它是一个智能代理服务器,允许Selenium测试将命令路由到远程Web浏览器实例.其目的是提供一种在多台计算机上并行运行测试的简便方法.使用Selenium Grid,一台服务器充当将JSON格式的
-
Python实现登录接口的示例代码
之前写了Python实现登录接口的示例代码,最近需要回顾,就顺便发到随笔上了 要求: 1.输入用户名和密码 2.认证成功,显示欢迎信息 3.用户名3次输入错误后,退出程序 4.密码3次输入错误后,锁定用户名 Readme: 1.UserList.txt 是存放用户名和密码的文件,格式为:username: password,每行存放一条用户信息 2.LockList.txt 是存放已被锁定用户名的文件,默认为空 3.用户输入用户名,程序首先查询锁定名单 LockList.txt,如果用户名在里面
-
python实现log日志的示例代码
源代码: # coding=utf-8 import logging import os import time LEVELS={'debug':logging.DEBUG,\ 'info':logging.INFO,\ 'warning':logging.WARNING,\ 'error':logging.ERROR,\ 'critical':logging.CRITICAL,} logger=logging.getLogger() level='default' def createFile
-
Python中字符串与编码示例代码
在最新的Python 3版本中,字符串是以Unicode编码的,即Python的字符串支持多语言 编码和解码 字符串在内存中以Unicode表示,在操作字符串时,经常需要str和bytes互相转换 如果在网络上传输或保存到磁盘上,则从内存读到的数据就是str,要把str变为以字节为单位的bytes,称为编码 如果从网络或磁盘上读取字节流,则从网络或磁盘上读到的数据就是bytes,要把bytes变为str,称为解码 为避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行