python实现PyEMD经验模态分解残差量分析
目录
- 前言
- 两种实现形式
- 区别
前言
PyEMD是经验模态分解 (EMD)及其变体的Python实现,EMD最流行的扩展之一是集成经验模态分解 (EEMD),它利用了噪声辅助执行的集成。
顾名思义,这个包中的方法获取数据(信号)并将其分解为一组组件。所有这些方法理论上都应该将信号分解为同一组分量,但实际上有很多细微差别和不同的方法来处理噪声。无论采用何种方法,获得的分量通常称为本征模态函数(IMF),以强调它们包含固有(自身)属性,即特定振荡(模态)。(以上来自官方文档)
两种实现形式
最近尝试实现CEEMDAN,CEEMADN也是EMD的一种变体。按照官方API,有以下两种形式的写法:
大部分博客采用的是第一种写法:
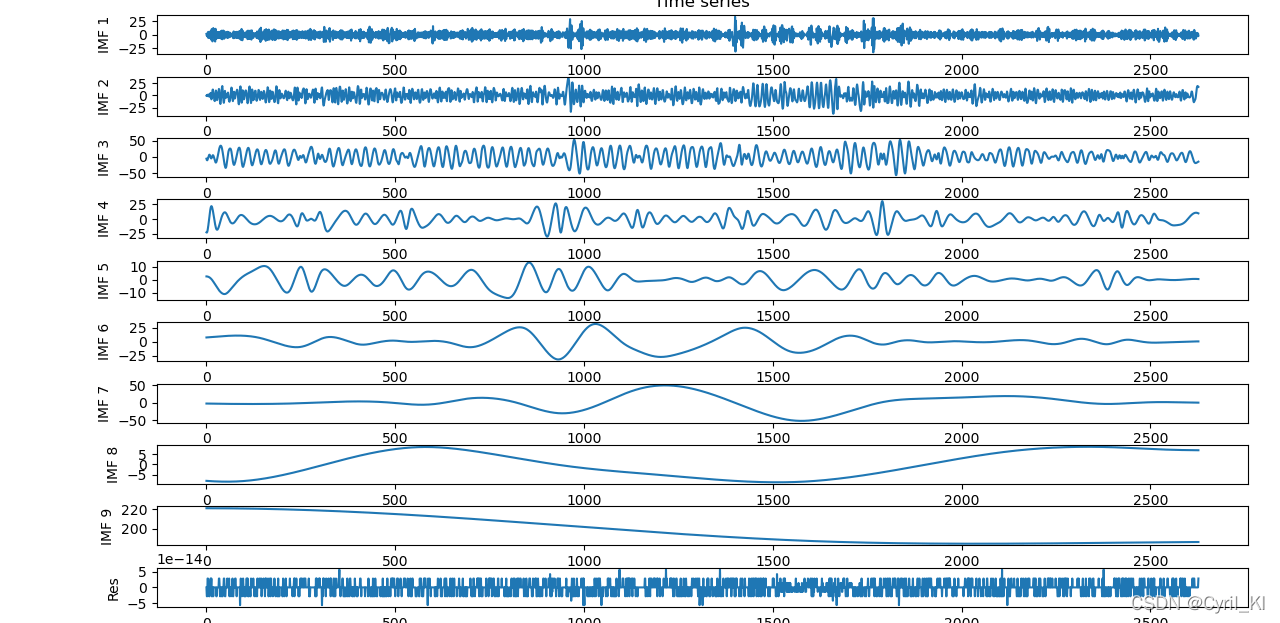
ceemdan = CEEMDAN() ceemdan.ceemdan(load) imfs, res = ceemdan.get_imfs_and_residue() vis = Visualisation() vis.plot_imfs(imfs, res)
这种写法得到的图为:
第二种写法,也是官方的写法:
ceemdan = CEEMDAN()(load) imfs, res = ceemdan[:-1], ceemdan[-1] vis = Visualisation() vis.plot_imfs(imfs, res)
得到的图示为:

可以发现,两张图最大的区别在于Res。一般论文中给出的图示是第二种。
我们尝试输出第一种方法中的Res:
[ 0.00000000e+00 -2.84217094e-14 0.00000000e+00 ... -2.84217094e-14
0.00000000e+00 0.00000000e+00]
可以发现其量级特别小,还原时我们可以不加上这一部分。而方法二中的Res显然量级是最大的,还原时必须加上。
因此,方法一中的Res是我们一般人所理解的残余量,在真正进行建模时可以不考虑。
方法一中画图时如果我们不包含残余量,即:
vis.plot_imfs(imfs=imfs, residue=res, include_residue=False)
我们将得到:

区别
在github上经过交流后,得到如下结论:
方法一中的Res是真正意义上的残余量,或许叫残差更合适一点,也就是分解之后不能再分解的部分。在PyEMD的源码中被定义为:
S * scale_s - np.sum(self.C_IMF, axis=0)
因此,ceemdan.get_imfs_and_residue()实际上得到的是最终的IMF和重建误差,而不是残差。
残差的正确获取方式是ceemdan[-1]。
以上就是python实现PyEMD经验模态分解残差量分析的详细内容,更多关于PyEMD经验模态分解残差量的资料请关注我们其它相关文章!
相关推荐
-

Python深度学习神经网络残差块
目录 ResNet模型 训练模型 ResNet沿用VGG完整的KaTeX parse error: Undefined control sequence: \time at position 2: 3\̲t̲i̲m̲e̲3卷积层设计.残差块里首先有2个相同输出通道数的KaTeX parse error: Undefined control sequence: \time at position 2: 3\̲t̲i̲m̲e̲3卷积层.每个卷积层后接一个批量归一化层和ReLU激活函数.然后我们通过跨
-
python实现PyEMD经验模态分解残差量分析
目录 前言 两种实现形式 区别 前言 PyEMD是经验模态分解 (EMD)及其变体的Python实现,EMD最流行的扩展之一是集成经验模态分解 (EEMD),它利用了噪声辅助执行的集成. 顾名思义,这个包中的方法获取数据(信号)并将其分解为一组组件.所有这些方法理论上都应该将信号分解为同一组分量,但实际上有很多细微差别和不同的方法来处理噪声.无论采用何种方法,获得的分量通常称为本征模态函数(IMF),以强调它们包含固有(自身)属性,即特定振荡(模态).(以上来自官方文档) 两种实现形式 最近尝试
-
python pickle存储、读取大数据量列表、字典数据的方法
先给大家介绍下python pickle存储.读取大数据量列表.字典的数据 针对于数据量比较大的列表.字典,可以采用将其加工为数据包来调用,减小文件大小 #列表 #存储 list1 = [123,'xiaopingguo',54,[90,78]] list_file = open('list1.pickle','wb') pickle.dump(list1,list_file) list_file.close() #读取 list_file = open('list1.pickle','rb')
-
用Python将GIF动图分解成多张静态图片
需求 有时候你看到一张动态图片,其中的一个画面你觉得很不错,想从中提取出来.例如以下这张由多个漂亮小姐姐组成的 GIF 动态图: 实现 GIF 动态图片是由多张静态图片组合而成,按照一定的顺序和时间进行播放.基于此,能不能将 GIF 图片反向分解成一张张静态图呢?即 GIF 图片有多少帧,就有多少张静态图片.答案是肯定的! 都有现成的工具,有免费的,有付费的,有在线版的:还有些专门处理 GIF 动态图片的强大工具. 不过,作为 IT 人,不试试自己实现吗?初学编程,可以练练手:高手可 DIY 可
-
python神经网络Keras实现LSTM及其参数量详解
目录 什么是LSTM 1.LSTM的结构 2.LSTM独特的门结构 3.LSTM参数量计算 在Keras中实现LSTM 实现代码 什么是LSTM 1.LSTM的结构 我们可以看出,在n时刻,LSTM的输入有三个: 当前时刻网络的输入值Xt: 上一时刻LSTM的输出值ht-1: 上一时刻的单元状态Ct-1. LSTM的输出有两个: 当前时刻LSTM输出值ht: 当前时刻的单元状态Ct. 2.LSTM独特的门结构 LSTM用两个门来控制单元状态cn的内容: 遗忘门(forget gate),它决定了
-
Python用函数思想完成哥德巴赫猜想代码分析
哥德巴赫猜想:大于8的偶数之和都可以被两个素数相加 范围 8 - 10000 思路: 首先不要去管需要什么什么东西实现,所以我们如果知道如何去完成: 大于8的偶数之和都可以被两个素数相加: # 可以假设 这个猜想是正确的. # 设一个变量是true flag = True # 确定范围 8 - 10000 for fanwei in range(8,10000,2): # 如果猜想错误如何? if not caixiang(fanwei): flag = False # 正确又如何错误又如何?
-
Python爬取用户观影数据并分析用户与电影之间的隐藏信息!
一.前言 二.爬取观影数据 https://movie.douban.com/ 在『豆瓣』平台爬取用户观影数据. 爬取用户列表 网页分析 为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(后面爬取用户观影记录只需要『用户名称』). https://movie.douban.com/subject/24733428/reviews?start=0 url中start参数是页数(page*20,每一页20条数据),因此start=0.20.40...,也就是20的倍数
-
Python爬虫之对CSDN榜单进行分析
前言 本篇文章的主要内容是利用Python对CSDN热榜变冷榜的指标数据进行分析的爬虫 分析一下各指标 开始爬取热榜,请稍候...耗时:2.199401808s [Top100指标统计] 浏览为0的: 3评论为0的: 76收藏为0的: 51浏览评论0的: 3三指标都0的: 2 浏览个位数的: 25评论个位数的: 98收藏个位数的: 86无封面题图的: 74 浏览>=100的: 18评论>=10的: 1收藏
-
Python中eval带来的潜在风险代码分析
0x00 前言 eval是Python用于执行python表达式的一个内置函数,使用eval,可以很方便的将字符串动态执行.比如下列代码: >>> eval("1+2") >>> eval("[x for x in range(10)]") [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 当内存中的内置模块含有os的话,eval同样可以做到命令执行: >>> import os >>&g
-
Python面向对象class类属性及子类用法分析
本文实例讲述了Python面向对象class类属性及子类用法.分享给大家供大家参考,具体如下: class类属性 class Foo(object): x=1.5 foo=Foo() print foo.x#通过实例访问类属性 >>>1.5 print Foo.x #通过类访问类属性 >>>1.5 foo.x=1.7 #只改新实例属性,不会改变类属性 print foo.x >>>1.7 print Foo.x >>>1.5 foo.
-
使用Python打造一款间谍程序的流程分析
知识点 这次我们使用python来打造一款间谍程序 程序中会用到许多知识点,大致分为四块 win32API 此处可以在MSDN上查看 Python基础重点在cpytes库的使用,使用方法请点击此处 C语言基础 Hook 程序的基本原理在于通过注册Hook,记录系统事件 那么什么是Hook呢 Hook 技术又叫做钩子函数,系统在调用函数之前,钩子程序就先捕获该消息,钩子函数先得到控制权,这时钩子函数既可以加工处理(改变)该函数的执行行为,还可以强制结束消息的传递 注册Hook时我们需要先导入DLL