python自动分箱,计算woe,iv的实例代码
笔者之前用R开发评分卡时,需要进行分箱计算woe及iv值,采用的R包是smbinning,它可以自动进行分箱。近期换用python开发, 也想实现自动分箱功能,找到了一个woe包,地址https://pypi.org/project/woe/,可以直接 pip install woe安装。
由于此woe包官网介绍及给的例子不是很好理解,关于每个函数的使用也没有很详细的说明,经过一番仔细探究后以此文记录一下该woe包的使用及其计算原理。
例子
官方给的例子不是很好理解,以下是我写的一个使用示例。以此例来说明各主要函数的使用方法。计算woe的各相关函数主要在feature_process.py中定义。
import woe.feature_process as fp import woe.eval as eval #%% woe分箱, iv and transform data_woe = data #用于存储所有数据的woe值 civ_list = [] n_positive = sum(data['target']) n_negtive = len(data) - n_positive for column in list(data.columns[1:]): if data[column].dtypes == 'object': civ = fp.proc_woe_discrete(data, column, n_positive, n_negtive, 0.05*len(data), alpha=0.05) else: civ = fp.proc_woe_continuous(data, column, n_positive, n_negtive, 0.05*len(data), alpha=0.05) civ_list.append(civ) data_woe[column] = fp.woe_trans(data[column], civ) civ_df = eval.eval_feature_detail(civ_list,'output_feature_detail_0315.csv') #删除iv值过小的变量 iv_thre = 0.001 iv = civ_df[['var_name','iv']].drop_duplicates() x_columns = iv.var_name[iv.iv > iv_thre]
计算分箱,woe,iv
核心函数主要是freature_process.proc_woe_discrete()与freature_process.proc_woe_continuous(),分别用于计算连续变量与离散变量的woe。它们的输入形式相同:
proc_woe_discrete(df,var,global_bt,global_gt,min_sample,alpha=0.01) proc_woe_continuous(df,var,global_bt,global_gt,min_sample,alpha=0.01)
输入:
df: DataFrame,要计算woe的数据,必须包含'target'变量,且变量取值为{0,1}
var:要计算woe的变量名
global_bt:全局变量bad total。df的正样本数量
global_gt:全局变量good total。df的负样本数量
min_sample:指定每个bin中最小样本量,一般设为样本总量的5%。
alpha:用于自动计算分箱时的一个标准,默认0.01.如果iv_划分>iv_不划分*(1+alpha)则划分。
输出:一个自定义的InfoValue类的object,包含了分箱的一切结果信息。
该类定义见以下一段代码。
class InfoValue(object): ''' InfoValue Class ''' def __init__(self): self.var_name = [] self.split_list = [] self.iv = 0 self.woe_list = [] self.iv_list = [] self.is_discrete = 0 self.sub_total_sample_num = [] self.positive_sample_num = [] self.negative_sample_num = [] self.sub_total_num_percentage = [] self.positive_rate_in_sub_total = [] self.negative_rate_in_sub_total = [] def init(self,civ): self.var_name = civ.var_name self.split_list = civ.split_list self.iv = civ.iv self.woe_list = civ.woe_list self.iv_list = civ.iv_list self.is_discrete = civ.is_discrete self.sub_total_sample_num = civ.sub_total_sample_num self.positive_sample_num = civ.positive_sample_num self.negative_sample_num = civ.negative_sample_num self.sub_total_num_percentage = civ.sub_total_num_percentage self.positive_rate_in_sub_total = civ.positive_rate_in_sub_total self.negative_rate_in_sub_total = civ.negative_rate_in_sub_total
打印分箱结果
eval.eval_feature_detail(Info_Value_list,out_path=False)
输入:
Info_Value_list:存储各变量分箱结果(proc_woe_continuous/discrete的返回值)的List.
out_path:指定的分箱结果存储路径,输出为csv文件
输出:
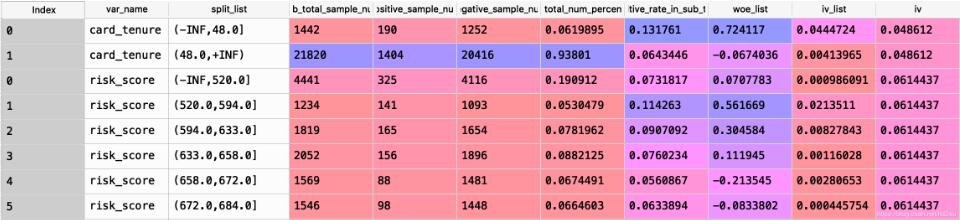
各变量分箱结果的DataFrame。各列分别包含如下信息:
| var_name | 变量名 |
| split_list | 划分区间 |
| sub_total_sample_num | 该区间总样本数 |
| positive_sample_num | 该区间正样本数 |
| negative_sample_num | 该区间负样本数 |
| sub_total_num_percentage | 该区间总占比 |
| positive_rate_in_sub_total | 该区间正样本占总正样本比例 |
| woe_list | woe |
| iv_list | 该区间iv |
| iv |
该变量iv(各区间iv之和) |
输出结果一个示例(截取部分):
woe转换
得到分箱及woe,iv结果后,对原数据进行woe转换,主要用以下函数
woe_trans(dvar,civ): replace the var value with the given woe value
输入:
dvar: 要转换的变量,Series
civ: proc_woe_discrete或proc_woe_discrete输出的分箱woe结果,自定义的InfoValue类
输出:
var: woe转换后的变量,Series
分箱原理
该包中对变量进行分箱的原理类似于二叉决策树,只是决定如何划分的目标函数是iv值。
1)连续变量分箱
首先简要描述分箱主要思想:
1.初始化数据集D =D0为全量数据。转步骤2
2.对于D,将数据按从小到大排序并按数量等分为10份,记录各划分点。计算不进行仍何划分时的iv0,转步骤3.
3.遍历各划分点,计算利用各点进行二分时的iv。
如果最大iv>iv0*(1+alpha)(用户给定,默认0.01): 则进行划分,且最大iv对应的即确定为此次划分点。它将D划分为左右两个结点,数据集分别为DL, DR.转步骤4.
否则:停止。
4.分别令D=DL,D=DR,重复步骤2.
为了便于理解,上面简化了一些条件。实际划分时还设计到一些限制条件,如不满足会进行区间合并。
主要限制条件有以下2个:
a.每个bin的数量占比>min_sample(用户给定)
b.每个bin的target取值个数>1,即每个bin必须同时包含正负样本。
2)连续变量分箱
对于离散变量分箱后续补充 to be continued...
以上这篇python自动分箱,计算woe,iv的实例代码就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用pandas实现连续数据的离散化处理方式(分箱操作)
Python实现连续数据的离散化处理主要基于两个函数,pandas.cut和pandas.qcut,前者根据指定分界点对连续数据进行分箱处理,后者则可以根据指定箱子的数量对连续数据进行等宽分箱处理,所谓等宽指的是每个箱子中的数据量是相同的. 下面简单介绍一下这两个函数的用法: # 导入pandas包 import pandas as pd ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] # 待分箱数据 bins = [18, 25,
-
python自动分箱,计算woe,iv的实例代码
笔者之前用R开发评分卡时,需要进行分箱计算woe及iv值,采用的R包是smbinning,它可以自动进行分箱.近期换用python开发, 也想实现自动分箱功能,找到了一个woe包,地址https://pypi.org/project/woe/,可以直接 pip install woe安装. 由于此woe包官网介绍及给的例子不是很好理解,关于每个函数的使用也没有很详细的说明,经过一番仔细探究后以此文记录一下该woe包的使用及其计算原理. 例子 官方给的例子不是很好理解,以下是我写的一个使用示例.以
-
python自动结束mysql慢查询会话的实例代码
生产环境的有些sql查询写得太复杂,或是表很大,对应索引未建立或建立不合理,或是查询未充分使用索引等,就有可能出现慢查询,一些慢查询需要修改程序,可能没那么快能解决,这时如果有个脚本能自动检测符合条件的慢查询会话并结束,那么是很方便的,当然运维人员也可顺便弄个检测慢查询并告警的脚本. 涉及知识点 mysql慢查询会话查询 schedule定时任务调度 pymysql执行sql 代码分解 mysql慢查询 #会话查询,只能查询所有会话,不能按条件过滤,不过比较好记 show PROCESSLIST
-

Python线程池thread pool创建使用及实例代码分享
目录 前言 一.线程 1.线程介绍 2.线程特性 轻型实体 独立调度和分派的基本单位 可并发执行 4)共享进程资源 二.线程池 三.线程池的设计思路 四.Python线程池构建 1.构建思路 2.实现库功能函数 ThreadPoolExecutor() submit() result() cancel() cancelled() running() as_completed() map() 前言 首先线程和线程池不管在哪个语言里面,理论都是通用的.对于开发来说,解决高并发问题离不开对多个线程处理
-
python编程使用selenium模拟登陆淘宝实例代码
selenium简介 selenium 是一个web的自动化测试工具,不少学习功能自动化的同学开始首选selenium ,相因为它相比QTP有诸多有点: * 免费,也不用再为破解QTP而大伤脑筋 * 小巧,对于不同的语言它只是一个包而已,而QTP需要下载安装1个多G 的程序. * 这也是最重要的一点,不管你以前更熟悉C. java.ruby.python.或都是C# ,你都可以通过selenium完成自动化测试,而QTP只支持VBS * 支持多平台:windows.linux.MAC ,支持多浏
-
Python实现微信消息防撤回功能的实例代码
微信(WeChat)是腾讯公司于2011年1月21日推出的一款社交软件,8年时间微信做到日活10亿,日消息量450亿.在此期间微信也推出了不少的功能如:"摇一摇"."漂流瓶"."朋友圈"."附近的人"."公众平台"."小程序"等等,涵盖了我们生活的方方面面,微信正在慢慢践行着他们的口号:微信,是一个生活方式 一.背景介绍 产品的更新迭代必然会伴随着功能的推出和下线,今天我们要讲的便是微信
-
python+opencv+caffe+摄像头做目标检测的实例代码
首先之前已经成功的使用Python做图像的目标检测,这回因为项目最终是需要用摄像头的, 所以实现摄像头获取图像,并且用Python调用CAFFE接口来实现目标识别 首先是摄像头请选择支持Linux万能驱动兼容V4L2的摄像头, 因为之前用学ARM的时候使用的Smart210,我已经确认我的摄像头是支持的, 我把摄像头插上之後自然就在 /dev 目录下看到多了一个video0的文件, 这个就是摄像头的设备文件了,所以我就没有额外处理驱动的部分 一.检测环境 再来在开始前因为之前按着国嵌的指导手册安
-
Python 序列化和反序列化库 MarshMallow 的用法实例代码
序列化(Serialization)与反序列化(Deserialization)是RESTful API 开发中绕不开的一环,开发时,序列化与反序列化的功能实现中通常也会包含数据校验(Validation)相关的业务逻辑. Marshmallow 是一个强大的轮子,很好的实现了 object -> dict , objects -> list, string -> dict和 string -> list. Marshmallow is an ORM/ODM/framework-a
-
基于python tkinter的点名小程序功能的实例代码
代码如下所示: import datetime import json import os import random import tkinter as tk import openpyxl # 花名册文件名 excel_file_path = "花名册.xlsx"#需在当前目录创建对应花名册.xlsx # 工作表名 excel_sheet = "Sheet1" # 记录存储文件名 file_path = "name_record.json"
-
python爬虫判断招聘信息是否存在的实例代码
在找工作的时候,我们会选择上网查询招聘的信息,或者是通过一些招聘会进行现场面试.但由于信息更新不及时,有一些岗位会出现下架的情况,如果我们不注意的话,可能就扑了空.在时间上耽误了不说,面试的信息也会受到一点点打击.今天小编就教大家python爬虫来判断招聘信息是否存在. 首先这里需要一个判断某条招聘是否还挂在网站上的方法,这个暂时想到了还没弄,然后对于发布时间在两个月之前的数据,就不进行统计计算. 以下是完成代码: { "_id" : ObjectId("5a30ad2068
-
Session过期后自动跳转到登录页面的实例代码
最近做了一个项目其中有需求,要实现自动登录功能,通过查阅相关资料,打算用session监听来做,下面给大家列出了配置监听器的方法: 1.在项目的web.xml文件中添加如下代码: <!--添加Session监听器--> <listener> <listener-class> 监听器路径 </listener-class> </listener> 2.编写java类. public class SessionListener implements