Redis Cluster集群收缩主从节点详细教程
目录
- 1.Cluster集群收缩概念
- 2.将6390主节点从集群中收缩
- 2.1.计算需要分给每一个节点的槽位数
- 2.2.分配1365个槽位给192.168.81.210的6380节点
- 2.3.分配1365个槽位给192.168.81.220的6380节点
- 2.4.分配1365个槽位给192.168.81.230的6380节点
- 2.5.查看当前集群槽位分配
- 3.验证数据迁移过程是否导致数据异常
- 4.将下线的主节点从集群中删除
- 4.1.删除节点
- 4.2.调整主从交叉复制
- 4.3.当节点存在数据无法删除
- 5.将下线主机清空集群信息
Redis Cluster集群收缩主从节点
1.Cluster集群收缩概念
当项目压力承载力过高时,需要增加节点来提高负载,当项目压力不是很大时,也希望能够将集群收缩下来,给其他项目使用,这就要用到集群收缩了
集群收缩操作和集群扩容是一样的,只需要把方向反过来即可。
扩容的时候执行一次命令就可以实现槽位迁移成功,而收缩的时候有几个主节点就需要执行多少次,比如除去要下线的节点,还有3个主节点,那么就需要执行三次,填写迁移出槽位的数量也需要除以3,每个节点也需要平均分配。
收缩的时候首先要填写分出多少个槽位,然后填写要分给谁,最后填写从哪分出槽位,一般分多少个槽位,就需要看要下线的主机上有多少个槽位,然后除以集群主节点数,使每一个主机点分到的槽位都是相同的,填写要分配给谁的时候,第一次填写第一个主节点的ID,第二次填写第二个主节点的ID,最后填写提供槽位的节点ID,就是下线节点的ID号。
集群收缩扩容槽位的时候不会影响数据的使用。
集群收缩的源端就是要下线的主节点,目标端就是在线的主节点(分配给谁的节点)。
咱们要清楚一点,只有主节点是有槽位的,因此呢需要将主节点的槽位分配给其他主节点,当槽位清空后,这个主机节点就可以下线了。

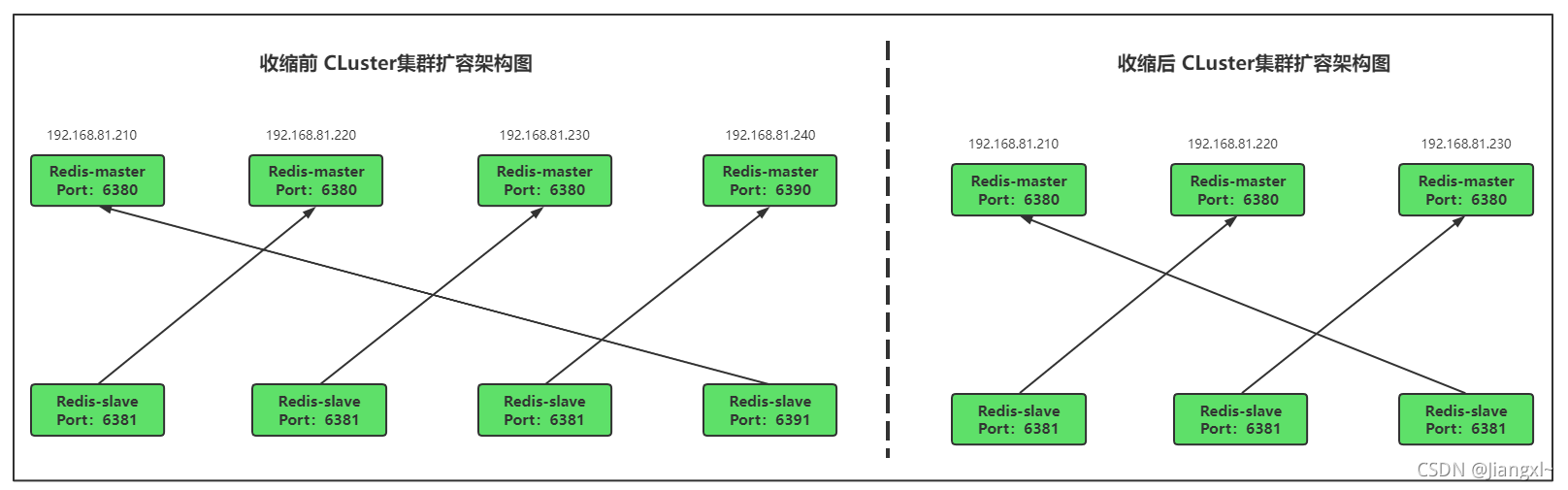
收缩集群前后对比图
集群收缩操作步骤:
1.执行reshard命令将需要下线的主节点进行槽位分散。
2.有几个主节点就需要执行几次reshard命令,首先填写要分出的槽位数,然后填写分给谁,最后填写从哪里分。
3.当槽位分散完成后,要下线的主节点没有任何数据时,将节点从集群中删除。
集群信息
目前集群时四主四从共8个节点,我们需要将集群改为三主三从,收缩出两个节点给其他程序使用。

2.将6390主节点从集群中收缩
2.1.计算需要分给每一个节点的槽位数
可以看到6390节点上有4096个槽位,删除要下线的6390节点后,我们还有3个主节点,4096除3得到1365,分配槽位的时候给每个节点分配1365个槽位即可均匀。

2.2.分配1365个槽位给192.168.81.210的6380节点
我们需要将192.168.81.240的6390节点分出1365个槽位给192.168.81.210的6380节点。
只需要把What is the receiving node ID填写成192.168.81.210的6380节点ID即可,指的是分配出来的槽位要给谁。
然后source node填写192.168.81.240的6390节点的ID,这里指的是从哪个节点上分出1365个槽位,填写ID后,回车后会提示还要从哪个节点上分配槽位,因为只有6390需要分出槽位,所以在这里填写done,表示只有这个一个节点分出1365个槽位给其他节点。
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380 How many slots do you want to move (from 1 to 16384)? 1365 #分配出多少个槽位 What is the receiving node ID? 80e256579658eb256c5b710a3f82c439665794ba #将槽位分给那个节点 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 #从哪个节点分出槽位 Source node #2:done Do you want to proceed with the proposed reshard plan (yes/no)? yes #输入yes继续
下面是收缩节点的过程截图。

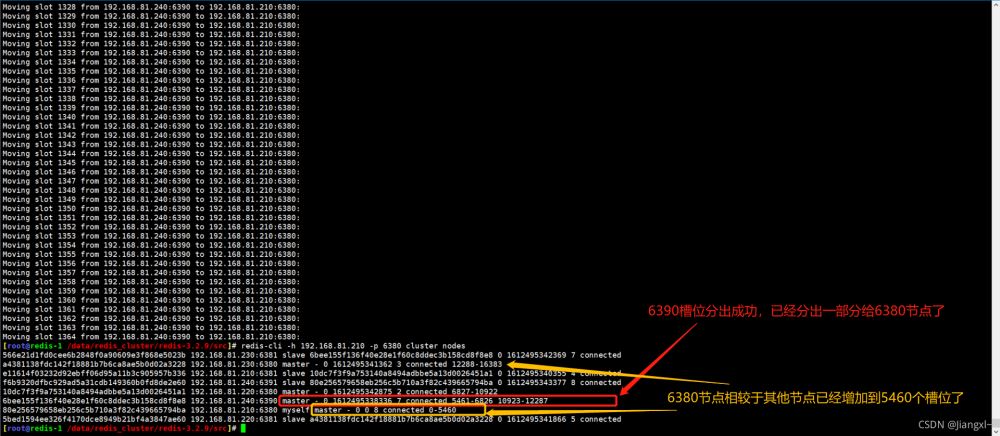
数据迁移过程。

槽位分出迁移成功。
2.3.分配1365个槽位给192.168.81.220的6380节点
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380 How many slots do you want to move (from 1 to 16384)? 1365 #分配出多少个槽位 What is the receiving node ID? 10dc7f3f9a753140a8494adbbe5a13d0026451a1 #将槽位分给那个节点 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 #从哪个节点分出槽位 Source node #2:done Do you want to proceed with the proposed reshard plan (yes/no)? yes #输入yes继续
收缩过程截图展示。



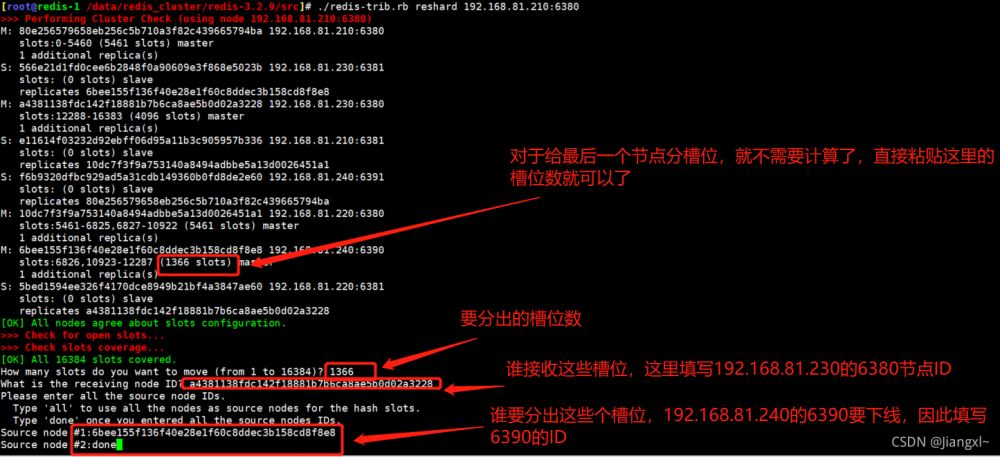
2.4.分配1365个槽位给192.168.81.230的6380节点
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb reshard 192.168.81.210:6380 How many slots do you want to move (from 1 to 16384)? 1366 #分配出多少个槽位 What is the receiving node ID? a4381138fdc142f18881b7b6ca8ae5b0d02a3228 #将槽位分给那个节点 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 #从哪个节点分出槽位 Source node #2:done Do you want to proceed with the proposed reshard plan (yes/no)? yes #输入yes继续
收缩过程截图展示。
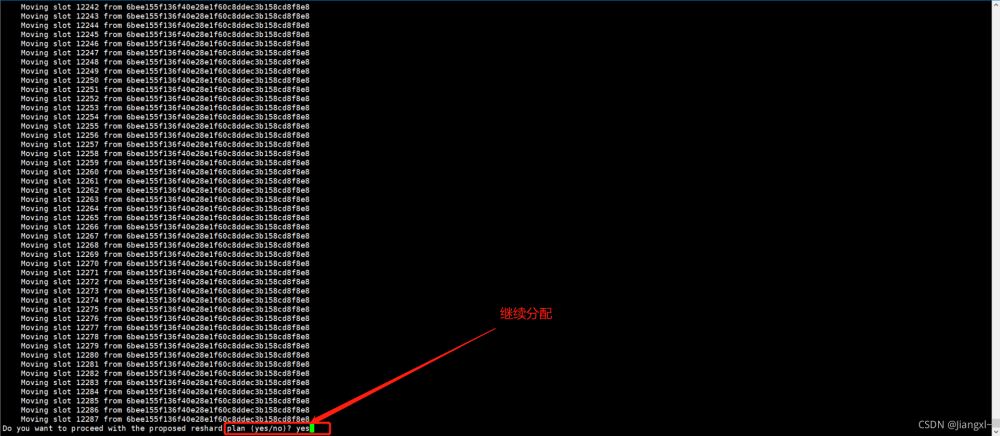
当最后一个节点迁移完数据后,6390主节点槽位数变为0。
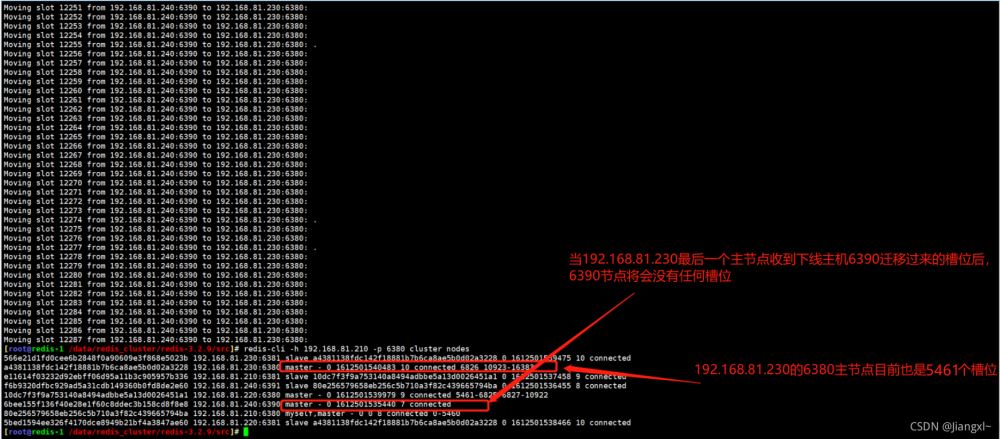
2.5.查看当前集群槽位分配
槽位及数据已经从6390即将下线的主机迁移完毕,可以看下当前集群三个主节点的槽位数。
可以非常清楚的看到,现在每个主节点的槽位数为5461。

如果觉得槽位重新分配后顺序不太满意,那么在执行一下reshard,把其它节点的槽位都分给192.168.81.210的6380上,这样一来,210的6380拥有的槽位就是0-16383,然后在将210的槽位一个节点分给5461个,分完之后,各节点的顺序就一致了。

3.验证数据迁移过程是否导致数据异常
多开几个窗口,一个执行数据槽位迁移,一个不断创建key,一个查看key的创建进度,一个查看key的数据。
持续测试,发现没有任何数据异常,全部显示ok。

4.将下线的主节点从集群中删除
4.1.删除节点
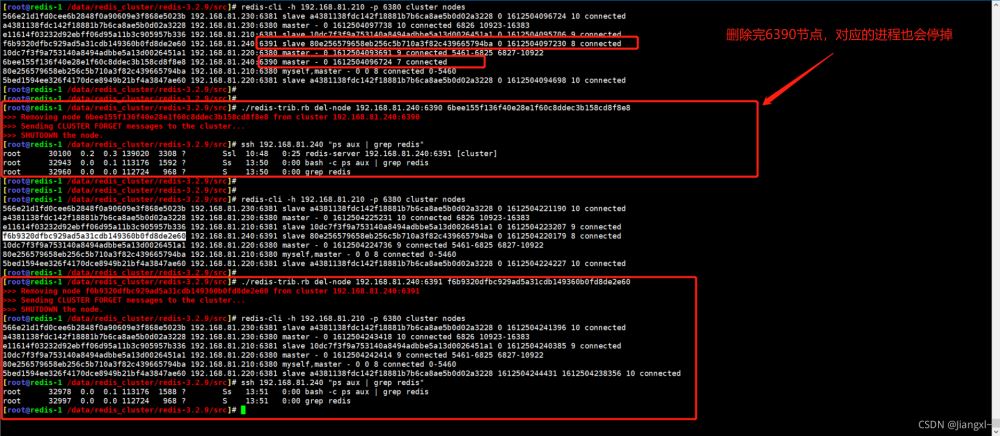
使用redis-trib删除一个节点,如果这个节点存在复制关系,有节点在复制当前节点或者当前节点复制别的节点的数据,redis-trib会自动处理复制关系,然后将节点删除,节点删除后会把对应的进程也停止运行。
删除节点之前必须确保该节点没有任何槽位和数据,否则会删除失败。
命令:./redis-trib.rb del-node 节点IP:端口 ID
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb del-node 192.168.81.240:6390 6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 >>> Removing node 6bee155f136f40e28e1f60c8ddec3b158cd8f8e8 from cluster 192.168.81.240:6390 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node. [root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb del-node 192.168.81.240:6391 f6b9320dfbc929ad5a31cdb149360b0fd8de2e60 >>> Removing node f6b9320dfbc929ad5a31cdb149360b0fd8de2e60 from cluster 192.168.81.240:6391 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node.
4.2.调整主从交叉复制
删掉192.168.81.240服务器上的两个redis节点后,192.168.81.210服务器上的6380就没有了复制关系,我们需要把192.168.81.230的6381节点复制192.168.81.210的6380节点。
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6381 192.168.81.230:6381> CLUSTER REPLICATE 80e256579658eb256c5b710a3f82c439665794ba OK

4.3.当节点存在数据无法删除
[root@redis-1 /data/redis_cluster/redis-3.2.9/src]# ./redis-trib.rb del-node 192.168.81.220:6380 10dc7f3f9a753140a8494adbbe5a13d0026451a1 >>> Removing node 10dc7f3f9a753140a8494adbbe5a13d0026451a1 from cluster 192.168.81.220:6380 [ERR] Node 192.168.81.220:6380 is not empty! Reshard data away and try again.

5.将下线主机清空集群信息
redis-trib虽然能够将节点在集群中删除,但是无法将其的集群信息清空,如果集群信息还有保留,那么该接地那就无法加入其它集群。

在下线的redis节点上使用cluster reset删除集群信息即可。
192.168.81.240:6390> CLUSTER reset
OK

到此这篇关于Redis Cluster集群收缩主从节点详细教程的文章就介绍到这了,更多相关Redis Cluster集群收缩内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Redis Cluster集群动态扩容的实现
目录 一.引言 二.Cluster集群增加操作 1.动态增加Master主服务器节点 2.动态增加Slave从服务器节点 三.Cluster集群删除操作 1.动态删除Slave从服务器节点 2.动态删除Master主服务器节点 四.总结 一.引言 上一篇文章我们一步一步的教大家搭建了Redis的Cluster集群环境,形成了3个主节点和3个从节点的Cluster的环境.当然,大家可以使用 Cluster info 命令查看Cluster集群的状态,也可以使用Cluster Nodes 命令来详细
-
在redisCluster中模糊获取key方式
在一个集群中,显然不能通过keys方法通过pattern直接获取key的集合: 鉴于这种问题,产生了两种思路,如下: 方案1: 已知相同的tag的KV会在一个节点上,所以只要key带有相同的hashtag,则会在一个节点上,所以只要扫描该节点即可,这样就将集群转化为了单点. @RequestMapping(value = "/ceshi", method = RequestMethod.GET) @ResponseBody public void Rediskeys() { /** *
-
Redis Cluster集群数据分片机制原理
Redis Cluster数据分片机制 Redis 集群简介 Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求. Redis Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点.三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点. 如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S
-
redis cluster支持pipeline的实现思路
什么是pipeLine 为什么使用pipeLine ? 上篇文章给大家介绍过redis为什么要提供pipeline功能 今天给大家普及redis cluster如何支持pipeline? 管道(pipeline)将客户端 client 与服务器端的交互明确划分为单向的发送请求(Send Request)和接收响应(Receive Response):用户可以将多个操作连续发给服务器,但在此期间服务器端并不对每个操作命令发送响应数据:全部请求发送完毕后用户关闭请求,开始接收响应获取每个操作命令的响
-
k8s部署redis cluster集群的实现
Redis 介绍 Redis代表REmote DIctionary Server是一种开源的内存中数据存储,通常用作数据库,缓存或消息代理.它可以存储和操作高级数据类型,例如列表,地图,集合和排序集合. 由于Redis接受多种格式的密钥,因此可以在服务器上执行操作,从而减少了客户端的工作量. 它仅将磁盘用于持久性,而将数据完全保存在内存中. Redis是一种流行的数据存储解决方案,并被GitHub,Pinterest,Snapchat,Twitter,StackOverflow,Flickr等技
-
Redis Cluster集群收缩主从节点详细教程
目录 1.Cluster集群收缩概念 2.将6390主节点从集群中收缩 2.1.计算需要分给每一个节点的槽位数 2.2.分配1365个槽位给192.168.81.210的6380节点 2.3.分配1365个槽位给192.168.81.220的6380节点 2.4.分配1365个槽位给192.168.81.230的6380节点 2.5.查看当前集群槽位分配 3.验证数据迁移过程是否导致数据异常 4.将下线的主节点从集群中删除 4.1.删除节点 4.2.调整主从交叉复制 4.3.当节点存在数据无法删
-
分布式Redis Cluster集群搭建与Redis基本用法
目录 Redis集群搭建 Redis是啥 集群(Cluster) RedisCluster说明 RedisCluster节点 RedisCluster集群模式 不能保证一致性 创建和使用Redis集群 部署三个主节点 非docker docker安装 创建集群 Redis入门 Redis中的数据类型 字符串(string) 哈希(Hash) 列表(Lists) 集合(Set) 有序集合(sortedset) Redis 集群搭建 Redis 是啥 Redis(全称 REmote DIctiona
-
基于Redis6.2.6版本部署Redis Cluster集群的问题
目录 1.Redis6.2.6简介以及环境规划 2.二进制安装Redis程序 2.1.二进制安装redis6.2.6 2.2.创建Reids Cluster集群目录 3.配置Redis Cluster三主三从交叉复制集群 3.1.准备六个节点的redis配置文件 3.2.将六个节点全部启动 3.3.配置集群节点之间相互发现 3.4.为集群中的充当Master的节点分配槽位 3.5.配置三主三从交叉复制模式 4.快速搭建Redis Cluster集群 1.Redis6.2.6简介以及环境规划 在R
-
Redis Cluster 集群搭建你会吗
三台机器 201.202.203,每台机器装两个 redis 实例,构建 redis cluster 集群. 1. 安装 添加 redis-cluster 目录,将 redis 压缩包拷贝到该目录下,解压压缩包. 解压完后,将文件夹 redis-5.0.3 重命名为 redis1. [root@test201 redis-cluster]# mv redis-5.0.3 redis1 需要在 redis1 目录下使用 make 命令进行编译. [root@test201 redis-cluste
-
php成功操作redis cluster集群的实例教程
前言 java操作redis cluster集群可使用jredis php要操作redis cluster集群有两种方式: 1.使用phpredis扩展,这是个c扩展,性能更高,但是phpredis2.x扩展不行,需升级phpredis到3.0,但这个方案参考资料很少 2.使用predis,纯php开发,使用了命名空间,需要php5.3+,灵活性高 我用的是predis,下载地址:点击这里 步骤如下: 下载好后重命名为predis, server1:192.168.1.198 server2:1
-
Redis Cluster集群主从切换的踩坑与填坑
因为项目的原因采用了Redis Cluster,3主3从,每台主机1主1从,集群信息如下: 10.135.255.72:20011> cluster nodes 7b662b36489a6240aa21d1cf7b04b84019254b63 10.135.255.74:20012 slave 85c78164a448fb9965e22447429a56cab226c68f 0 1537239581900 43 connected 61c3e1a640e71f4801d850c901dd33f0
-
Redis cluster集群的介绍
1.前言 Redis集群模式主要有2种: 主从集群.分布式集群. 前者主要是为了高可用或是读写分离,后者为了更好的存储数据,负载均衡. redis集群提供了以下两个好处 1.将数据自动切分(split)到多个节点 2.当集群中的某一个节点故障时,redis还可以继续处理客户端的请求. 一个 redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个.集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽.集群中