sklearn中make_blobs的用法详情
目录
- 1.调用make_blobs
- 2.make_blobs的用法
sklearn中的make_blobs函数主要是为了生成数据集的,具体如下:
1.调用make_blobs
from sklearn.datasets import make_blobs
2.make_blobs的用法
data, label = make_blobs(n_features=2, n_samples=100, centers=3, random_state=3, cluster_std=[0.8, 2, 5])
n_features表示每一个样本有多少特征值n_samples表示样本的个数centers是聚类中心点的个数,可以理解为label的种类数random_state是随机种子,可以固定生成的数据cluster_std设置每个类别的方差
下面举例说明:
'''创建训练的数据集''' from sklearn.datasets import make_blobs data, label = make_blobs(n_features=2, n_samples=100, centers=2, random_state=2019, cluster_std=[0.6,0.7] )
看看生成的数据集:
data有2个特征(n_features=2),样本个数是100(n_samples=100)
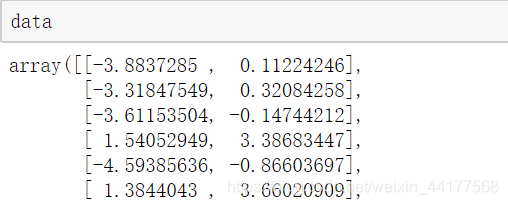
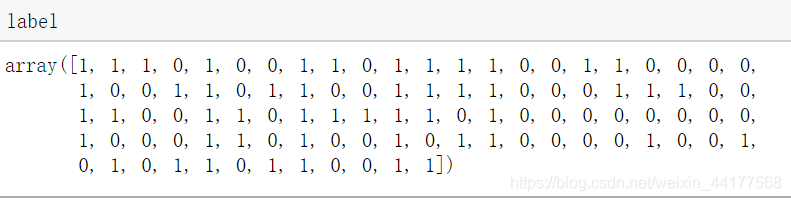
再看看生成的label:
label只有0或者1(centers=2),维度是100
random_state给定数值后,每次生成的数据集就是固定的,方便后期复现,默认的是每次随机生成,要注意一下!!
好了,这样我们就拥有了一个自己想要的数据集,然后就可以开始后续的一些工作了!!!!
到此这篇关于sklearn中make_blobs的用法详情的文章就介绍到这了,更多相关sklearn中make_blobs的用法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python库sklearn常用操作
目录 前言 一.MinMaxScaler 前言 sklearn是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类.回归.降维以及聚类:还包含了监督学习.非监督学习.数据变换三大模块.sklearn拥有完善的文档,使得它具有了上手容易的优势:并它内置了大量的数据集,节省了获取和整理数据集的时间.因而,使其成为了广泛应用的重要的机器学习库. sklearn是一个无论对于机器学习还是深度学习都必不可少的重要的库,里面包含了关于机器学习的几乎所有需要的功能,因为sklearn库的内容
-

Python 机器学习工具包SKlearn的安装与使用
1.SKlearn 是什么 Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包. Sklearn 主要用Python编写,建立在 Numpy.Scipy.Pandas 和 Matplotlib 的基础上,也用 Cython编写了一些核心算法来提高性能. Sklearn 包括六大功能模块: 分类(Classification):识别样本属于哪个类别,常用算法有 SVM(支持向量机).nearest neighbors(最近邻).random forest(
-
python机器学习Sklearn实战adaboost算法示例详解
目录 pandas批量处理体测成绩 adaboost adaboost原理案例举例 弱分类器合并成强分类器 pandas批量处理体测成绩 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls") cond =
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
sklearn中make_blobs的用法详情
目录 1.调用make_blobs 2.make_blobs的用法 sklearn中的make_blobs函数主要是为了生成数据集的,具体如下: 1.调用make_blobs from sklearn.datasets import make_blobs 2.make_blobs的用法 data, label = make_blobs(n_features=2, n_samples=100, centers=3, random_state=3, cluster_std=[0.8, 2, 5])
-
Python sklearn中的.fit与.predict的用法说明
我就废话不多说了,大家还是直接看代码吧~ clf=KMeans(n_clusters=5) #创建分类器对象 fit_clf=clf.fit(X) #用训练器数据拟合分类器模型 clf.predict(X) #也可以给新数据数据对其预测 print(clf.cluster_centers_) #输出5个类的聚类中心 y_pred = clf.fit_predict(X) #用训练器数据X拟合分类器模型并对训练器数据X进行预测 print(y_pred) #输出预测结果 补充知识:sklearn中
-
Python中print()函数的用法详情
Python中print()函数的方法是打印指定的内容.在交互环境中输入“help(print)”指令,可以显示print()函数的使用方法, 如图1所示: 图1 print()函数的使用方法 1 常用方法 1.1 打印单个内容 从图1中可以看出,print()函数的第一个参数是value,即要打印的内容.通过print()打印单个内容的方法 如图2所示: 图2 打印单个内容 1.2 打印多个内容 从图1中可以看出,print()函数的第二个参数是...,表示print()函数要打印的多个参数,
-
Python中if __name__==‘__main__‘用法详情
前言: 我们先定义一个test01.py的文件. test01.py中代码如下所示: def step(): print(__name__) print('step1 买菜' 'step2 洗菜' 'step3 切菜' 'step4 炒菜') if __name__=='__main__': print('准备制作菜品') step() print('制作完成') 输出结果: 注意:这段代码中输出的第一句. print(__name__) if __name__=='__main__'是一个判断
-
Java中TypeReference用法详情说明
在使用fastJson时,对于泛型的反序列化很多场景下都会使用到TypeReference,例如: void testTypeReference() { List<Integer> list = new ArrayList<>(); list.add(1); list.add(9); list.add(4); list.add(8); JSONObject jsonObj = new JSONObject(); jsonObj.put("a", list); S
-
vue中keep-alive的用法及问题描述
1.keep-alive的作用以及好处 在做电商有关的项目中,当我们第一次进入列表页需要请求一下数据,当我从列表页进入详情页,详情页不缓存也需要请求下数据,然后返回列表页,这时候我们使用keep-alive来缓存组件,防止二次渲染,这样会大大的节省性能. 2.keep-alive的基本用法 在app.vue中 <!-- 缓存所有的页面 --> <keep-alive> <router-view v-if="$route.meta.keep_alive"&g
-
sklearn中的交叉验证的实现(Cross-Validation)
sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好.今天主要记录一下sklearn中关于交叉验证的各种用法,主要是对sklearn官方文档 Cross-validation: evaluating estimator performance进行讲解,英文水平好的建议读官方文档,里面的知识点很详细. 先导入需要的库及数据集 In [1]: import numpy as np In [2]: from sklearn.model_selection impor
-
C# .NET 中的缓存实现详情
目录 一.缓存的基本概念 二.缓存 三.进程内缓存早期做法 四.更好的解决方案 1. Microsoft.Extensions.Caching.Memory 2.具有驱逐策略的 IMemoryCache 3.问题和缺失的功能 4.代码说明 五.何时使用 WaitToFinishMemoryCache 一.缓存的基本概念 缓存 .这是一个简单但非常有效的概念,这个想法的核心是记录过程数据,重用操作结果.当执行繁重的操作时,我们会将结果保存在我们的 缓存容器中 .下次我们需要该结果时,我们将从缓存容
-
Python 中 logging 模块使用详情
目录 1.为什么要用logging模块 2.logging模块介绍 3.基础设置 1.为什么要用logging模块 在实际应用中,日志文件十分重要,通过日志文件,我们知道程序运行的细节:同时,当程序出问题时,我们也可以通过日志快速定位问题所在.在我们写程序时,也可以借助 logging 模块的输出信息来调试代码. 但是很多人还是在程序中使用print()函数来输出一些信息,比如: print 'Start reading database' records = model.read_recrod
-
SpringBoot中使用Thymeleaf模板详情
目录 一.什么是Thymeleaf 二.SpringBoot中使用Thymeleaf模板 1.pom.xml中添加thymeleaf依赖 2.关闭thymeleaf缓存 3.创建thymeleaf模板页面 4.创建一个类(用于与上述html页面交互) 5.访问服务路径 一.什么是Thymeleaf 官网原话:Thymeleaf是适用于Web和独立环境的现代服务器端Java模板引擎,能够处理HTML,XML,JavaScript,CSS甚至纯文本. Thymeleaf的主要目标是提供一种优雅且高度