浅谈Node 异步IO和事件循环
前言
学习Node就绕不开异步IO, 异步IO又与事件循环息息相关, 而关于这一块一直没有仔细去了解整理过, 刚好最近在做项目的时候, 有了一些思考就记录了下来, 希望能尽量将这一块的知识整理清楚, 如有错误, 请指点轻喷~~
一些概念
同步异步 & 阻塞非阻塞
查阅资料的时候, 发现很多人都对 异步和非阻塞 的概念有点混淆, 其实两者是完全不同的, 同步异步指的是 行为即两者之间的关系 , 而阻塞非阻塞指的是 状态即某一方 。
以前端请求为一个例子,下面的代码很多人都应该写过
$.ajax(url).succedd(() => {
......
// to do something
})
同步异步
如果是同步的话, 那么应该是client发起请求后, 一直等到serve处理请求完成后才返回继续执行后续的逻辑, 这样 client和serve之间就保持了同步的状态 。
如果是异步的话, 那么应该是client发起请求后, 立即返回 , 而请求可能还没有到达server端或者请求正在处理, 当然在异步情况下, client端通常会注册事件来处理请求完成后的情况, 如上面的succeed函数。
阻塞非阻塞
首先需要明白一个概念, Js是单线程, 但是浏览器并不是, 事实上你的请求是浏览器的另一个线程在跑。
如果是阻塞的话, 那么 该线程就会一直等到这个请求完成之后才能被释放用于其他请求 。
如果是非阻塞的话, 那么 该线程就可以发起请求后而不用等请求完成继续做其他事情 。
总结
之所以经常会混乱是因为没有说清楚讨论的是哪一部分(下面会提到), 所以 同步异步讨论的对象是双方, 而阻塞非阻塞讨论的对象是自身 。
IO和CPU
Io和Cpu是可以同时进行工作的 。
IO:
I/O(英语:Input/Output),即输入/输出,通常指数据在内部存储器和外部存储器或其他周边设备之间的输入和输出。
cpu
解释计算机指令以及处理计算机软件中的数据。
Node中的异步IO模型
IO分为 磁盘IO和网络IO , 其具有两个步骤
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
Node中的磁盘Io
以下的讨论基于*nix系统。
理想的异步Io应该像上面讨论的一样, 如图:

而实际上, 我们的系统并不能完美的实现这样的一种调用方式, Node的异步IO, 如读取文件等采用的是线程池的方式来实现, 可以看到, Node通过另外一个线程来进行Io操作, 完成后再通知主线程:

而在window下, 则是利用 IOCP 接口来完成, IOCP从用户的角度来说确实是完美的异步调用方式, 而实际也是利用内核中的线程池, 其与nix系统的不同在于后者的线程池是用户层提供的线程池。
Node中的网络Io
在进入主题之前, 我们先了解下Linux的Io模式, 这里推荐大家看这篇文章, 大致总结如下:
阻塞 I/O(blocking IO)

所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
非阻塞 I/O(nonblocking IO)

当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
I/O 多路复用( IO multiplexing)
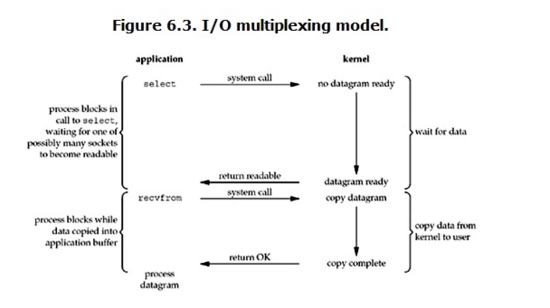
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
异步 I/O(asynchronous IO)

用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
而在Node中, 采用的是I/O 多路复用的模式, 而在I/O多路复用的模式中, 又具有read, select, poll, epoll等几个子模式, Node采用的是最优的epoll模式, 这里简单说下其中的区别, 并且解释下为什么epoll是最优的。
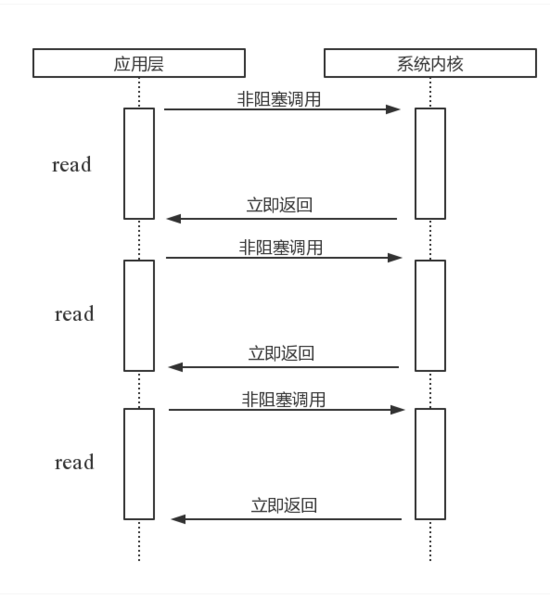
read
read。它是一种最原始、性能最低的一种,它会重复检查I/O的状态来完成数据的完整读取。在得到最终数据前,CPU一直耗用在I/O状态的重复检查上。图1是通过read进行轮询的示意图。
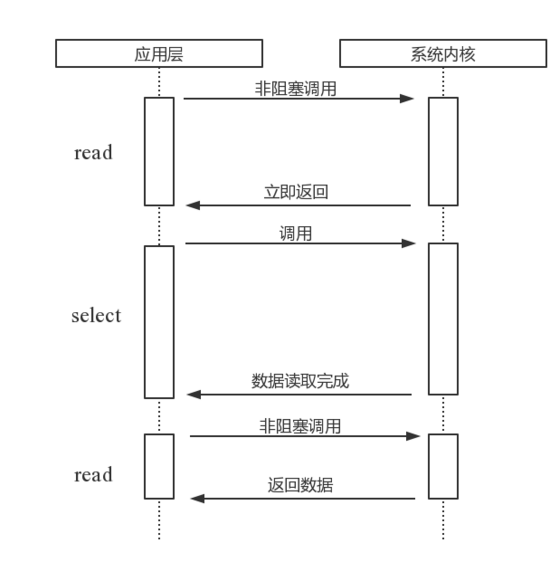
select
select。它是在read的基础上改进的一种方案,通过对文件描述符上的事件状态进行判断。图2是通过select进行轮询的示意图。select轮询具有一个较弱的限制,那就是由于它采用一个1024长度的数组来存储状态,也就是说它最多可以同时检查1024个文件描述符。
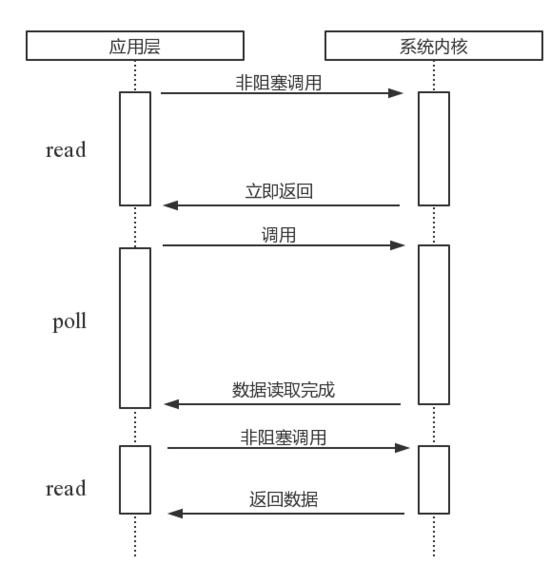
poll
poll。poll比select有所改进,采用链表的方式避免数组长度的限制,其次它可以避免不必要的检查。但是文件描述符较多的时候,它的性能是十分低下的。
epoll
该方案是Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知,执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。

除此之外, 另外的poll和select还具有以下的缺点(引用自 文章 ):
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- select支持的文件描述符数量太小了,默认是1024
epoll对于上述的改进
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,一般来说这个数目和系统内存关系很大。
Node中的异步网络Io就是利用了epoll来实现, 简单来说, 就是利用一个线程来管理众多的IO请求, 通过事件机制实现消息通讯。
事件循环
理解了Node中磁盘IO和网络IO的底层实现后, 基于上面的代码, 可以看出Node是基于事件注册的方式在完成Io后进行一系列的处理, 其内部是利用了事件循环的机制。
关于事件循环, 是指JS在每次执行完同步任务后会检查执行栈是否为空, 是的话就会去执行注册的事件列表, 不断的循环该过程。Node中的事件循环有六个阶段:

其中的每个阶段都会处理相关的事件:
- timers: 执行setTimeout和setInterval中到期的callback。
- pending callback: 执行延迟到下一个循环迭代的 I/O 回调。
- idle, prepare:仅系统内部使用。
- poll:检索新的 I/O 事件;执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,它们由计时器和 setImmediate() 排定的之外),其余情况 node 将在此处阻塞。(即本文的内容相关))
- check: setImmediate() 回调函数在这里执行。
- close callbacks: 执行close事件的callback,例如socket.on('close'[,fn])或者http.server.on('close, fn)。
ok, 这样就解释了Node是如何执行我们注册的事件, 那么还缺少一个环节, Node又是怎么把事件和IO请求对应起来呢? 这里涉及到了另外一种中间产物请求对象。
以打开一个文件为例子:
fs.open = function(path, flags, mode, callback){
//...
binding.open(pathModule._makeLong(path), stringToFlags(flags), mode, callback);
}
fs.open()的作用是根据指定路径和参数去打开一个文件,从而得到一个文件描述符,这是后续所有I/O操作的初始操作。从前面的代码中可以看到,JavaScript层面的代码通过调用C++核心模块进行下层的操作。

从JavaScript调用Node的核心模块,核心模块调用C++内建模块,内建模块通过libuv进行系统调用,这是Node里经典的调用方式。这里libuv作为封装层,有两个平台的实现,实质上是调用了uv_fs_open()方法。在uv_fs_open()的调用过程中,我们创建了一个FSReqWrap请求对象。从JavaScript层传入的参数和当前方法都被封装在这个请求对象中,其中我们最为关注的回调函数则被设置在这个对象的oncomplete_sym属性上:
req_wrap->object_->Set(oncomplete_sym, callback);
QueueUserWorkItem()方法接受3个参数:第一个参数是将要执行的方法的引用,这里引用的uv_fs_thread_proc;第二个参数是uv_fs_thread_proc方法运行时所需要的参数;第三个参数是执行的标志。当线程池中有可用线程时,我们会调用uv_fs_thread_proc()方法。uv_fs_thread_proc()方法会根据传入参数的类型调用相应的底层函数。以uv_fs_open()为例,实际上调用fs_open()方法。
至此,JavaScript调用立即返回,由JavaScript层面发起的异步调用的第一阶段就此结束。JavaScript线程可以继续执行当前任务的后续操作。当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响到JavaScript线程的后续执行,如此就达到了异步的目的。
请求对象是异步I/O过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及I/O操作完毕后的回调处理。
关于这一块其实个人认为不用过于细究, 大致上知道有这么一个请求对象即可, 最后总结一下整个异步IO的流程:
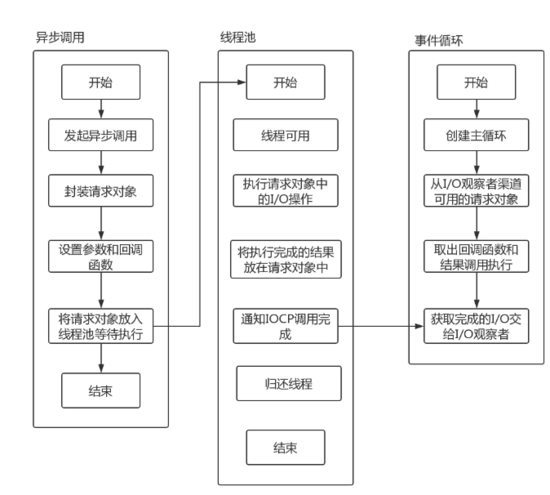
图引用自深入浅出NodeJs
至此, Node的整个异步Io流程都已经清晰了, 它是依赖于IO线程池epoll、事件循环、请求对象共同构成的一个管理机制。
Node为什么更适合IO密集
Node为人津津乐道的就是它更适合 IO密集型 的系统, 并且具有 更好的性能 , 关于这一点其实与它的异步IO息息相关。
对于一个request而言, 如果我们依赖io的结果, 异步io和同步阻塞io(每线程/每请求)都是要等到io完成才能继续执行. 而同步阻塞io, 一旦阻塞就不会在获得cpu时间片, 那么为什么异步的性能更好呢?
其根本原因在于同步阻塞Io需要为 每一个请求创建一个线程 , 在Io的时候, 线程被block, 虽然不消耗cpu, 但是其本身具有内存开销, 当大并发的请求到来时, 内存很快被用光, 导致服务器缓慢 , 在加上, 切换上下文代价也会消耗cpu资源 。而Node的异步Io是通过事件机制来处理的, 它不需要为每一个请求创建一个线程, 这就是为什么Node的性能更高。
特别是在Web这种IO密集型的情形下更具优势, 除开Node之外, 其实还有另外一种事件机制的服务器Ngnix, 如果明白了Node的机制对于Ngnix应该会很容易理解, 有兴趣的话推荐看这篇文章。
总结
在真正的学习Node异步IO之前, 经常看到一些关于Node适不适合作为服务器端的开发语言的争论, 当然也有很多片面的说法。
其实, 关于这个问题还是取决于你的业务场景。
假设你的业务是cpu密集型的, 那你采用Node来开发, 肯定是不适合的。 为什么不适合? 因为Node是单线程, 你被阻塞在计算的时候, 其他的事件就做不了, 处理不了请求, 也处理不了回调。
那么在IO密集型中, Node就比Java好吗? 其实也不一定, 还是要取决于你的业务。 如果你的业务是非常大的并发, 但是你的服务器资源又有限, 就好比现在有个入口, Node可以一次进10个人, 而Java依次排队进一个人, 如果是10个人同时进, 当然是Node更具有优势, 但是假设有100个人(如1w个异步请求之类)的话, 那么Node就会因为它的异步机制导致应用被挂起,内存狂飙,IO堵塞,而且不可恢复,这个时候你只能重启了。而Java却可以有序的处理, 虽然会慢一点。 而一台服务器挂了造成的线上事故的损失更是不可衡量的。(当然, 如果服务器资源足够的话, Node也能处理)。
最后, 事实上Java也是具有异步IO的库, 只是相对来说, Node的语法更自然更贴近, 也就更适合。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

深入浅析Node.js 事件循环
Node.js 是单进程单线程应用程序,但是通过事件和回调支持并发,所以性能非常高. (来源于Javascript是单线程又是异步的,但是这种语言有个共同的特点:它们是 event-driven 的.驱动它们的 event 来自一个异构的平台.) Node.js 的每一个 API 都是异步的,并作为一个独立线程运行,使用异步函数调用,并处理并发. Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现. Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件
-
小结Node.js中非阻塞IO和事件循环
学习和使用Node.js已经有两个月,使用express结合mongoose写了一个web应用和一套RESTful web api,回过头来看Node.js官网首页对Node.js的介绍:Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient.那么其中的non-blocking I/O model 意味着什么呢? 非阻塞的IO模型 首先,IO操作无疑是耗时的,当服务器
-
实例分析JS与Node.js中的事件循环
这两天跟同事同事讨论遇到的一个问题,js中的event loop,引出了chrome与node中运行具有setTimeout和Promise的程序时候执行结果不一样的问题,从而引出了Nodejs的event loop机制,记录一下,感觉还是蛮有收获的 console.log(1) setTimeout(function() { new Promise(function(resolve, reject) { console.log(2) resolve() }) .then(() => { con
-
Node.js 的异步 IO 性能探讨
Python 和 Ruby 也有这样的框架,但因为在实际使用中会不可避免地用到含有同步代码的库,因此没能成长起来,而在 Node.js 之前,JavaScript 的服务器端编程几乎是空白,所以 Node.js 才得以建立起了一个所有 IO 均为异步的代码库. 大部分 Web 应用的瓶颈都在 IO, 即读写磁盘,读写网络,读写数据库.使用怎样的策略等待这段时间,就成了改善性能的关键点. PHP 的策略:多进程运行,直接原地等待 IO 完成.缺点:多个进程会消耗多份内存,进程间难以共享数据. C/
-
详解nodejs异步I/O和事件循环
事件驱动模型 现在我们来看看nodejs中的事件驱动和异步I/O是如何实现的. nodejs是单线程(single thread)运行的,通过一个事件循环(event-loop)来循环取出消息队列(event-queue)中的消息进行处理,处理过程基本上就是去调用该消息对应的回调函数.消息队列就是当一个事件状态发生变化时,就将一个消息压入队列中. nodejs的时间驱动模型一般要注意下面几个点: 因为是单线程的,所以当顺序执行js文件中的代码的时候,事件循环是被暂停的. 当js文件执行完以后,事
-
Node.js 事件循环详解及实例
Node.js 事件循环详解及实例 Node.js 是单进程单线程应用程序,但是通过事件和回调支持并发,所以性能非常高. Node.js 的每一个 API 都是异步的,并作为一个独立线程运行,使用异步函数调用,并处理并发. Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现. Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件观察者退出,每个异步事件都生成一个事件观察者,如果有事件发生就调用该回调函数. Node.js 有多个内置的事件,我们可以
-
浅谈Node 异步IO和事件循环
前言 学习Node就绕不开异步IO, 异步IO又与事件循环息息相关, 而关于这一块一直没有仔细去了解整理过, 刚好最近在做项目的时候, 有了一些思考就记录了下来, 希望能尽量将这一块的知识整理清楚, 如有错误, 请指点轻喷~~ 一些概念 同步异步 & 阻塞非阻塞 查阅资料的时候, 发现很多人都对 异步和非阻塞 的概念有点混淆, 其实两者是完全不同的, 同步异步指的是 行为即两者之间的关系 , 而阻塞非阻塞指的是 状态即某一方 . 以前端请求为一个例子,下面的代码很多人都应该写过 $.ajax(
-
浅谈Node异步编程的机制
本文介绍了Node异步编程,分享给大家,具体如下: 目前的异步编程主要解决方案有: 事件发布/订阅模式 Promise/Deferred模式 流程控制库 事件发布/订阅模式 Node自身提供了events模块,可以轻松实现事件的发布/订阅 //订阅 emmiter.on("event1",function(message){ console.log(message); }) //发布 emmiter.emit("event1","I am mesaage!
-
浅谈Node的内存泄露
目录 1.node内存相关知识 2.哪些情况会造成内存泄露 第一.全局变量 第二.函数闭包 第三.事件监听 3.内存泄露的监测 4.Chrome DevTools进行分析和对比 5.内存分析的意义 1.node内存相关知识 无论是运行在浏览器端的js,还是运行在node中的js,关于内存管理的方案,都是通过垃圾回收机制来实现内存的分配和释放.当我们的代码编写有缺陷时,可能就无法通过gc来释放内存,这个时候,我们就造成了内存泄露. Node.js进程的内存管理,都是由 V8 引擎自动处理的,包括内
-
浅谈jQuery hover(over, out)事件函数
hover(over, out)事件函数 当鼠标移动一个匹配的元素上面,会触发指定的第一个函数 当鼠标移出这个元素时,会触发指定的第二个函数 over(function):鼠标移到元素上触发的函数 out(function):鼠标移出元素触发的函数 <nav class="main-nav"> <a href="/"><span>首页</span></a> <a href="/about&q
-
浅谈angularjs中响应回车事件
下面这个示例在输入框键入回车键或者点击按钮时,将输入框的值置为"Hello World!":(黄色背景内容为响应回车事件涉及到的代码) <html ng-app="myApp"> <head> <meta charset="utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=utf-8&quo
-
浅谈Node.js ORM框架Sequlize之表间关系
Sequelize模型之间存在关联关系,这些关系代表了数据库中对应表之间的主/外键关系.基于模型关系可以实现关联表之间的连接查询.更新.删除等操作.本文将通过一个示例,介绍模型的定义,创建模型关联关系,模型与关联关系同步数据库,及关系模型的增.删.改.查操作. 数据库中的表之间存在一定的关联关系,表之间的关系基于主/外键进行关联.创建约束等.关系表中的数据分为1对1(1:1).1对多(1:M).多对多(N:M)三种关联关系. 在Sequelize中建立关联关系,通过调用模型(源模型)的belon
-
浅谈jquery之on()绑定事件和off()解除绑定事件
off()函数用于移除元素上绑定的一个或多个事件的事件处理函数. off()函数主要用于解除由on()函数绑定的事件处理函数. 该函数属于jQuery对象(实例). 语法 jQuery 1.7 新增该函数.其主要有以下两种形式的用法: 用法一: jQueryObject.off( [ events [, selector ] [, handler ] ] ) 用法二: jQueryObject.off( eventsMap [, selector ] ) 参数 参数 描述 events 可选/S
-
浅谈shell数组的定义及循环
shell中数组的定义及遍历,先直接看示例: #!/bin/sh #定义方法一 数组定义为空格分割 arrayWen=(a b c d e f) #定义方法二 arrayXue[0]="m" arrayXue[1]="n" arrayXue[2]="o" arrayXue[3]="p" arrayXue[4]="q" arrayXue[5]="r" #打印数组长度 echo ${#arr
-
浅谈vue异步数据影响页面渲染
今天遇到一个问题,要保证页面渲染前请求的数据已经得到了 由于user是在异步请求之后保存在session中,而在页面渲染时session中还没有user,页面直接报错. 因此我希望能在所有请求都得到后再去做页面的渲染. 1.先把id为app的div用v-if="appShow",定义appShow为false进行隐藏,避免渲染 2.写计数器,每1ms进行一次查询,如果session中已经有user,删除过滤器,移除滤布,appShow为true,开始渲染页面,这样可以保证页面的正常渲染
-
浅谈angular2子组件的事件传递(任意组件事件传递)
angular2子组件的事件传递 angular2有很多组件组成,画面由很多路由,导致事件的传递很"笨拙",本组的技术负责人发现了任意组件传递事件的这个方法,教会了我,我做个笔记. 项目情况: 画面结构复杂,路由数目偏多,组件数目多,嵌套复杂.业务要求:任何出现人名的地方,点击人名,直接打开和这个人的聊天画面 以前用angular2官网给的烹饪技巧基本解决90%的需求,当然这个如果是用Input,Output也可以,但是那样的话,结构将是混沌状态. 附:angluar2的组件通讯的传送