Java 使用maven实现Jsoup简单爬虫案例详解
一、Jsoup的简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据
二、我们可以利用Jsoup做什么
2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据,
2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本
2.3从而使我们输出我们想要的整洁文本
三、利用Jsoup爬取某东示例
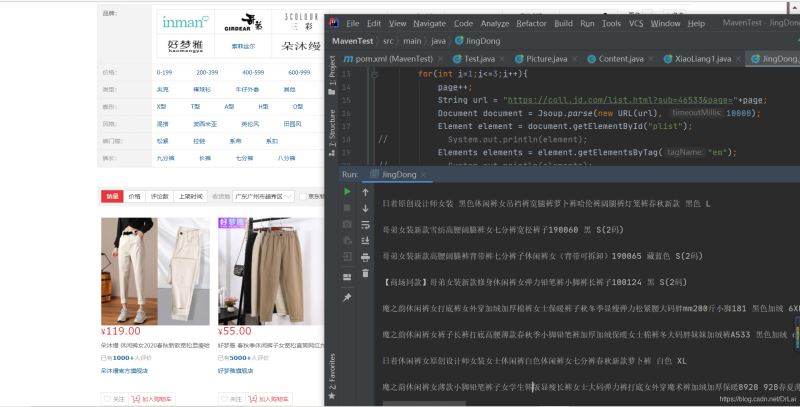
可以从图中看到,成功爬取某东的女装热门销量从高到低的标题,从而可以分析到销量高(或者是综合排序)在前列的标题名称。从而可以剖析出热门商品的命名规范。
四、Jsoup用法
4.1先创建maven工程,在maven工程上注入依赖
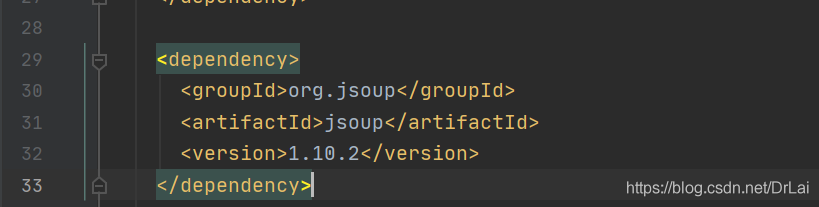
4.2 注入依赖后需要导入依赖,否则在程序中使用Jsoup会全部报错。
4.3利用JSP的知识找出目标元素
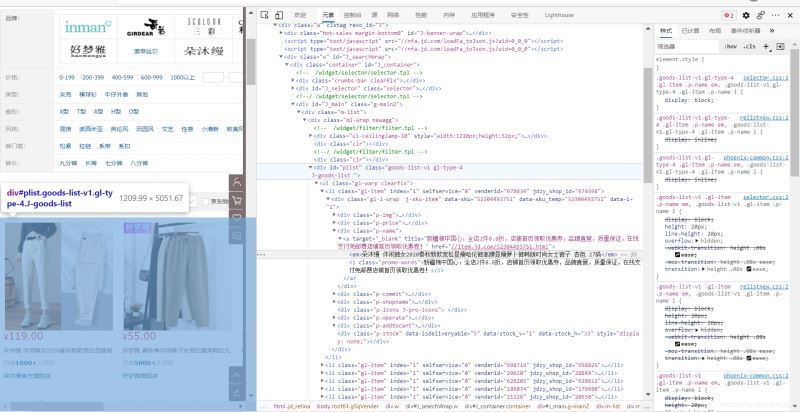
如在某东界面我们发现, 控制目标页面的ID为"plist",则我们使用
getElementById("plist");方法去获取到他的ID
接着获取目标标题,可以由上图分析得,标题是由<em>标签所控制,因此我们需要用到
getElementsByTag("em");去捕捉到em的部分
最后循环输出他的部分即可。

五、总结
Jsoup只能应用于简单的页面捕捉,在实际开发中许多网站采用Ajax技术等使得模块在动态变化抑或是有反爬虫技术,因此本技术有局限性。熟悉前端jsp技术的同学应该会游刃有余。
最后附上所有代码
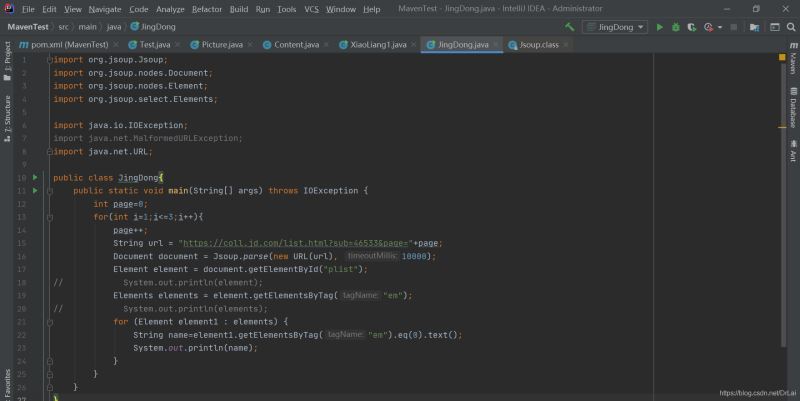
到此这篇关于Java 使用maven实现Jsoup简单爬虫案例详解的文章就介绍到这了,更多相关Java 使用maven实现Jsoup简单爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java中用爬虫进行解析的实例方法
我们都知道可以用爬虫来找寻一些想要的数据,除了可以使用python进行操作,我们最近学习的java同样也支持爬虫的运行,本篇小编就教大家用java爬虫来进行网页的解析,具体内容请往下看: 1.springboot项目,引入jsoup <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version&g
-
Java 实现网络爬虫框架详细代码
目录 Java 实现网络爬虫框架 一.每个类的功能介绍 二.每个类的源代码 Java 实现网络爬虫框架 最近在做一个搜索相关的项目,需要爬取网络上的一些链接存储到索引库中,虽然有很多开源的强大的爬虫框架,但本着学习的态度,自己写了一个简单的网络爬虫,以便了解其中的原理.今天,就为小伙伴们分享下这个简单的爬虫程序!! 一.每个类的功能介绍 DownloadPage.java的功能是下载此超链接的页面源代码. FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式
-
java能写爬虫程序吗
我们经常会使用网络爬虫去爬取需要的内容,提到爬虫,可能大家伙都会想到python,其实除了python,还有java.java的编程语言简单规范,是很好的爬虫工具.而且java爬虫的语言运行速度比python快,另外,java的多线程是可以利用多核的. 1.java为什么可以应用于网络爬虫? java语法比较规则,采用严格的面向对象编程方法: Java是Android开发的基石, 是Web开发的主流语言: 具有很好的扩展性可伸缩性,其是目前搜索引擎开发的重要组成部分: java爬虫的语言运行速度
-

java编程实现简单的网络爬虫示例过程
本项目中需要用到两个第三方jar包,分别为 jsoup 和 commons-io. jsoup的作用是为了解析网页, commons-io 是为了把数据保存到本地. 1.爬取贴吧 第一步,打开eclipse,新建一个java项目,名字就叫做 pachong: 然后,新建一个类,作为我们程序的入口. 这个作为入口类,里面就写一个main方法即可. public class StartUp { public static void main(String[] args) { } } 第二步,导入我们
-
Java爬虫范例之使用Htmlunit爬取学校教务网课程表信息
使用WebClient和htmlunit实现简易爬虫 import com.gargoylesoftware.htmlunit.WebClient; 提供了public P getPage(final String url)方法获得HtmlPage. import com.gargoylesoftware.htmlunit.html.*; 包含了HtmlPage.HtmlForm.HtmlTextInput.HtmlPasswordInput.HtmlElement.DomElement等元素.
-
JAVA使用HtmlUnit爬虫工具模拟登陆CSDN案例
最近要弄一个爬虫程序,想着先来个简单的模拟登陆, 在权衡JxBrowser和HtmlUnit 两种技术, JxBowser有界面呈现效果,但是对于某些js跳转之后的效果获取比较繁琐. 随后考虑用HtmlUnit, 想着借用咱们CSND的登陆练练手.谁知道CSDN的登陆,js加载时间超长,不设置长一点的加载时间,按钮提交根本没效果,js没生效. 具体看代码注释吧. 奉劝做爬虫的同志们,千万别用CSDN登陆练手,坑死我了. maven配置如下: <dependencies> <!-- ht
-
半小时实现Java手撸网络爬虫框架(附完整源码)
最近在做一个搜索相关的项目,需要爬取网络上的一些链接存储到索引库中,虽然有很多开源的强大的爬虫框架,但本着学习的态度,自己写了一个简单的网络爬虫,以便了解其中的原理.今天,就为小伙伴们分享下这个简单的爬虫程序!! 首先介绍每个类的功能: DownloadPage.java的功能是下载此超链接的页面源代码. FunctionUtils.java 的功能是提供不同的静态方法,包括:页面链接正则表达式匹配,获取URL链接的元素,判断是否创建文件,获取页面的Url并将其转换为规范的Url,截取网页网页源
-
Java 使用maven实现Jsoup简单爬虫案例详解
一.Jsoup的简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 二.我们可以利用Jsoup做什么 2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据, 2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本 2.3从而使我们输出我们想要的整洁文本 三.利用Jsoup爬
-
Java SPI简单应用案例详解
开篇 本文主要谈一下 Java SPI(Service Provider Interface) ,因为最近在看 Dubbo 的相关内容,其中涉及到了 一个概念- Dubbo SPI, 最后又牵扯出来了 JAVA SPI, 所以先从 Java SPI 开整. 正文 平常学习一个知识点,我们的常规做法是: 是什么 有什么用 怎么用 这次我们倒着做,先不谈什么是 SPI 及其作用,来看下如何使用. 使用 1. 创建一个 maven 工程 2. 创建一个接口类以及实现类 // 接口 public int
-
Java Apollo环境搭建以及集成SpringBoot案例详解
环境搭建 下载Quick Start安装包 从Github下载:checkout或下载apollo-build-scripts项目 手动打包Quick Start安装包 修改apollo-configservice, apollo-adminservice和apollo-portal的pom.xml,注释掉spring-boot-maven-plugin和maven-assembly-plugin 在根目录下执行mvn clean package -pl apollo-assembly -am
-
Java之Error与Exception的区别案例详解
首先,Error类和Exception类都是继承Throwable类 Error(错误)是系统中的错误,程序员是不能改变的和处理的,是在程序编译时出现的错误,只能通过修改程序才能修正.一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等.对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止. Exception(异常)表示程序可以处理的异常,可以捕获且可能恢复.遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止
-
Java Spring @Lazy延迟注入源码案例详解
前言 有时候我们会在属性注入的时候添加@Lazy注解实现延迟注入,今天咱们通过阅读源码来分析下原因 一.一个简单的小例子 代码如下: @Service public class NormalService1 { @Autowired @Lazy private MyService myService; public void doSomething() { myService.getName(); } } 作用是为了进行延迟加载,在NormalService1进行属性注入的时候,如果MyServ
-
Java 处理超大数类型之BigInteger案例详解
一.BigInteger介绍 如果在操作的时候一个整型数据已经超过了整数的最大类型长度 long 的话,则此数据就无法装入,所以,此时要使用 BigInteger 类进行操作.这些大数都会以字符串的形式传入. BigInteger 相比 Integer 的确可以用 big 来形容.它是用于科学计算,Integer 只能容纳一个 int,所以,最大值也就是 2 的 31 次访减去 1,十进制为 2147483647.但是,如果需要计算更大的数,31 位显然是不够用的,那么,此时 BigIntege
-
Java CharacterEncodingFilter过滤器的理解和配置案例详解
在web项目中我们经常会遇到当前台JSP页面和JAVA代码中使用了不同的字符集进行编码的时候就会出现表单提交的数据或者上传/下载中文名称文件出现乱码的问题,这些问题的原因就是因为我们项目中使用的编码不一样.为了解决这个问题我们就可以使用CharacterEncodingFilter类,他是Spring框架对字符编码的处理,基于函数回调,对所有请求起作用,只在容器初始化时调用一次,依赖于servlet容器.具体配置如下: <filter> <filter-name>character
-
Java 高并发的三种实现案例详解
提到锁,大家肯定想到的是sychronized关键字.是用它可以解决一切并发问题,但是,对于系统吞吐量要求更高的话,我们这提供几个小技巧.帮助大家减小锁颗粒度,提高并发能力. 初级技巧-乐观锁 乐观锁使用的场景是,读不会冲突,写会冲突.同时读的频率远大于写. 悲观锁的实现: 悲观的认为所有代码执行都会有并发问题,所以将所有代码块都用sychronized锁住 乐观锁的实现: 乐观的认为在读的时候不会产生冲突为题,在写时添加锁.所以解决的应用场景是读远大于写时的场景. 中级技巧-String.i
-
Java Stopwatch类,性能与时间计时器案例详解
在研究性能的时候,完全可以使用Stopwatch计时器计算一项技术的效率.但是有时想知道某想技术的性能的时候,又常常想不起可以运用Stopwatch这个东西,太可悲了. 属性: Elapsed 获取当前实例测量得出的总运行时间. ElapsedMilliseconds 获取当前实例测量得出的总运行时间(以毫秒为单位). ElapsedTicks 获取当前实例测量得出的总运行时间(用计时器计时周期表示). IsRunning 获取一个指示 Stopwatch 计时器是否在运行的值. 方法
-
Java toString方法重写工具之ToStringBuilder案例详解
apache的commons-lang3的工具包里有一个ToStringBuilder类,这样在打日志的时候可以方便的打印出类实例中的各属性的值. 具体用法如下: import org.apache.commons.lang3.builder.ToStringBuilder; import org.apache.commons.lang3.builder.ToStringStyle; public class Message { private String from; private Stri