详解如何利用Python进行客户分群分析
目录
- 导入数据和python库
- 分离新老客户
- 按客户ID排序,然后是日期
- 定义一些函数
- 创建群组
- 转换为群组百分比
- 可视化
每个电子商务数据分析师必须掌握的一项数据聚类技能
如果你是一名在电子商务公司工作的数据分析师,从客户数据中挖掘潜在价值,来提高客户留存率很可能就是你的工作任务之一。
然而,客户数据是巨大的,每个客户的行为都不一样。2020年3月收购的客户A与2020年5月收购的客户B表现出不同的行为。因此,有必要将客户分为不同的群组,然后调查每个群组在一段时间内的行为。这就是所谓的同期群分析。
同期群分析是了解一个特殊客户群体在一段时间内的行为的数据分析技术。
在这篇文章中,不会详细介绍同期群分析的理论。这篇文章更多的是告诉你如何将客户分成不同的群组,并在一段时间内观察每个群组的留存率。
导入数据和python库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('sales_2018-01-01_2019-12-31.csv')
df
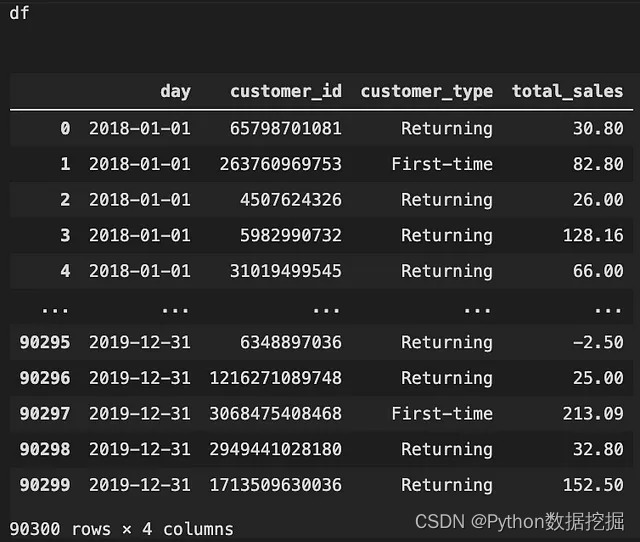
分离新老客户
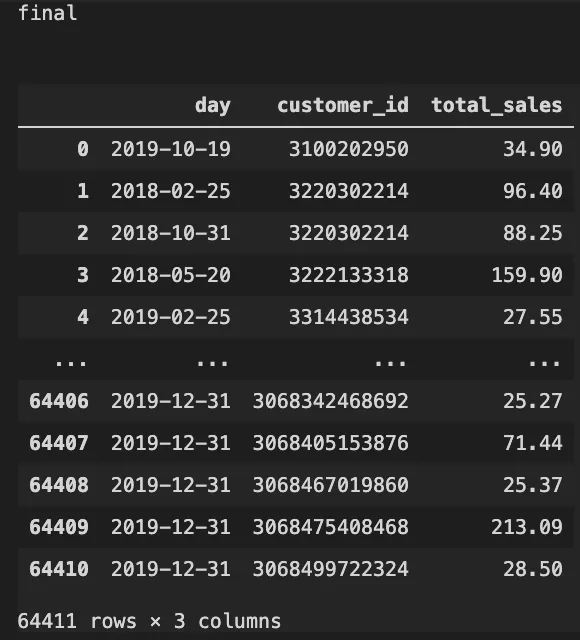
first_time = df.loc[df['customer_type'] == 'First-time',] final = df.loc[df['customer_id'].isin(first_time['customer_id'].values)]
在这里,不能简单地选择df.loc[df['customer_type']],因为在这个数据中,在customer_type列下,First_time指的是新客户,而Returning指的是老客户。因此,如果我在2019年12月31日第一次购买,数据会显示我在2019年12月31日是新客户,但在我第二次、第三次…时是返回客户。同期群分析着眼于新客户和他们的后续购买行为。因此,如果我们简单地使用df.loc[df['customer_type']=='First-time',],我们就会忽略新客户的后续购买,这不是分析同期群行为的正确方法。
因此,这里所需要做的是,首先创建一个所有第一次的客户列表,并将其存储为first_time。然后从原始客户数据框df中只选择那些ID在first_time客户组内的客户。通过这样做,我们可以确保我们获得的数据只有第一次的客户和他们后来的购买行为。
现在,我们删除customer_type列,因为它已经没有必要了。同时,将日期列转换成正确的日期时间格式
final = final.drop(columns = ['customer_type']) final['day']= pd.to_datetime(final['day'], dayfirst=True)
按客户ID排序,然后是日期
final = final.drop(columns = ['customer_type']) final['day']= pd.to_datetime(final['day'], dayfirst=True)
定义一些函数
def purchase_rate(customer_id):
purchase_rate = [1]
counter = 1
for i in range(1,len(customer_id)):
if customer_id[i] != customer_id[i-1]:
purchase_rate.append(1)
counter = 1
else:
counter += 1
purchase_rate.append(counter)
return purchase_rate
def join_date(date, purchase_rate):
join_date = list(range(len(date)))
for i in range(len(purchase_rate)):
if purchase_rate[i] == 1:
join_date[i] = date[i]
else:
join_date[i] = join_date[i-1]
return join_date
def age_by_month(purchase_rate, month, year, join_month, join_year):
age_by_month = list(range(len(year)))
for i in range(len(purchase_rate)):
if purchase_rate[i] == 1:
age_by_month[i] = 0
else:
if year[i] == join_year[i]:
age_by_month[i] = month[i] - join_month[i]
else:
age_by_month[i] = month[i] - join_month[i] + 12*(year[i]-join_year[i])
return age_by_month
- purchase_rate函数将决定这是否是每个客户的第二次、第三次、第四次购买。
- join_date函数允许确定客户加入的日期。
- age_by_month函数提供了从客户当前购买到第一次购买的多少个月。
现在输入已经准备好了,接下来创建群组。
创建群组
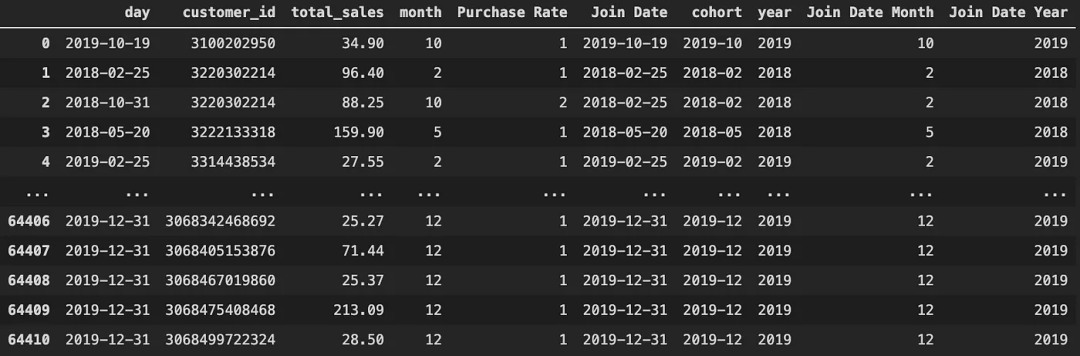
final['month'] =pd.to_datetime(final['day']).dt.month
final['Purchase Rate'] = purchase_rate(final['customer_id'])
final['Join Date'] = join_date(final['day'], final['Purchase Rate'])
final['Join Date'] = pd.to_datetime(final['Join Date'], dayfirst=True)
final['cohort'] = pd.to_datetime(final['Join Date']).dt.strftime('%Y-%m')
final['year'] = pd.to_datetime(final['day']).dt.year
final['Join Date Month'] = pd.to_datetime(final['Join Date']).dt.month
final['Join Date Year'] = pd.to_datetime(final['Join Date']).dt.year
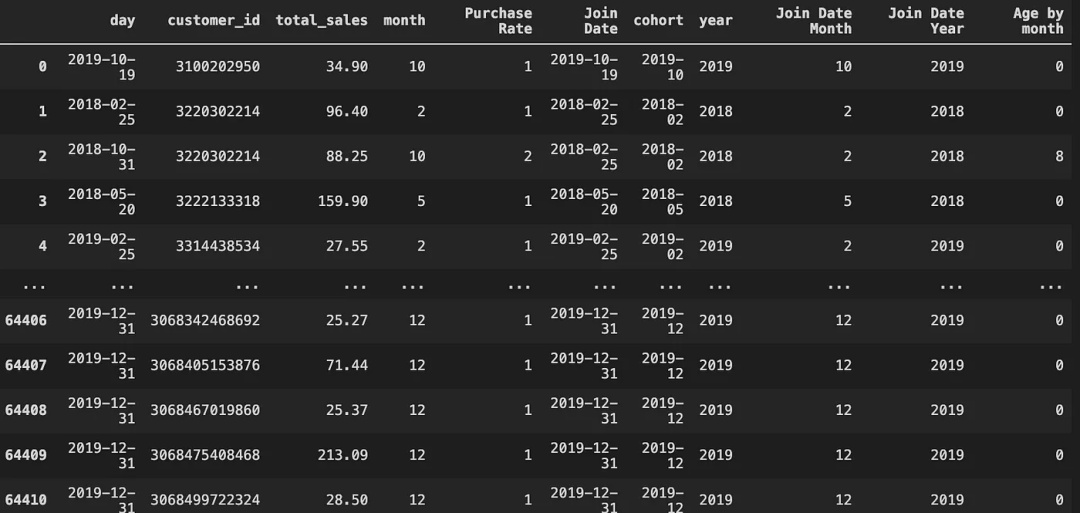
final['Age by month'] = age_by_month(final['Purchase Rate'],
final['month'],
final['year'],
final['Join Date Month'],
final['Join Date Year'])
cohorts = final.groupby(['cohort','Age by month']).nunique() cohorts = cohorts.customer_id.to_frame().reset_index() # convert series to frame cohorts = pd.pivot_table(cohorts, values = 'customer_id',index = 'cohort', columns= 'Age by month') cohorts.replace(np.nan, '',regex=True)
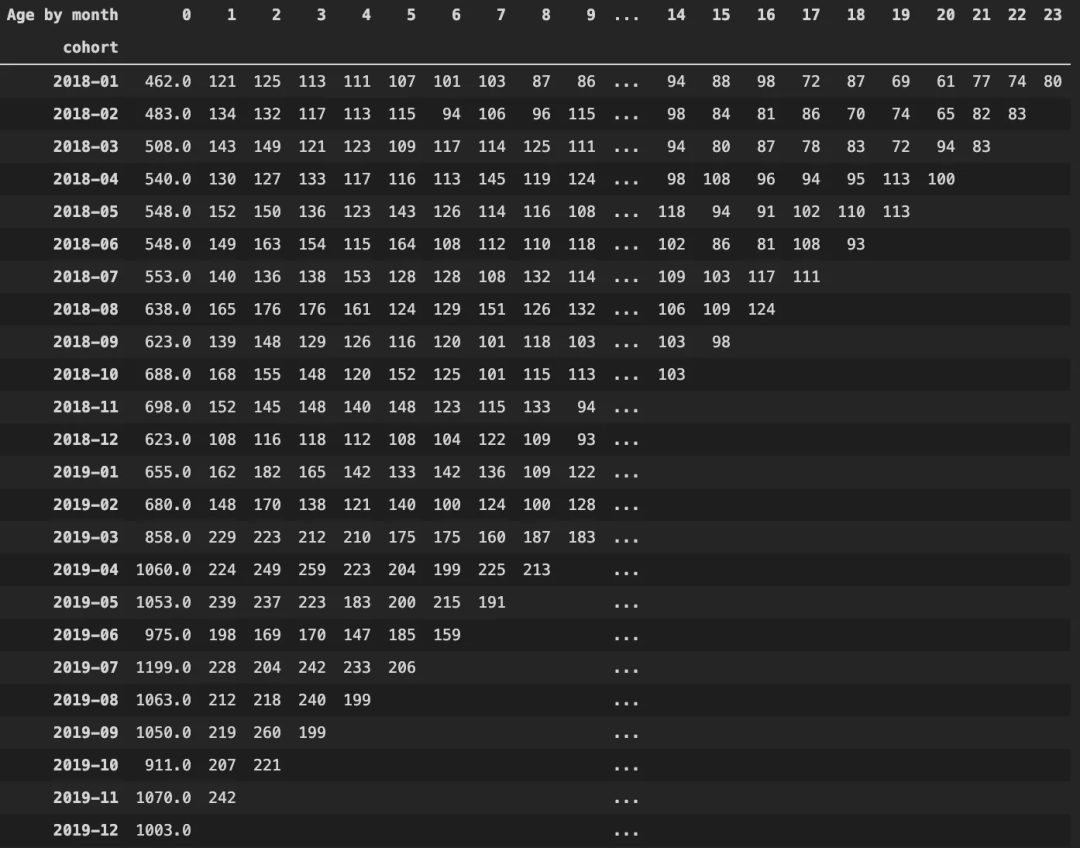
**如何解释这个表格:**以群组2018-01为例。在2018年1月,有462名新客户。在这462人中,121名客户在2018年2月回来购买,125名在2018年3月购买,以此类推。
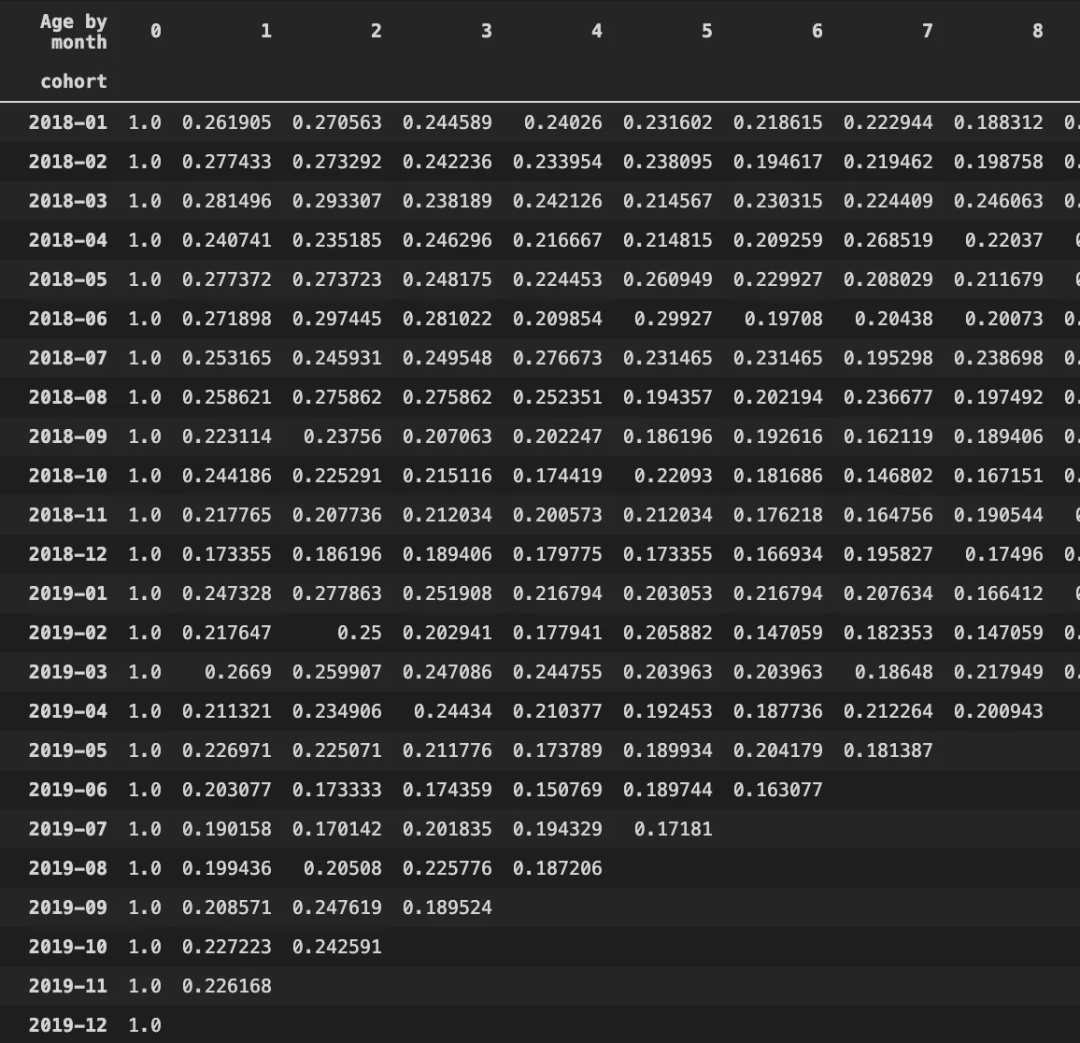
转换为群组百分比
for i in range(len(cohorts)-1):
cohorts[i+1] = cohorts[i+1]/cohorts[0]
cohorts[0] = cohorts[0]/cohorts[0]
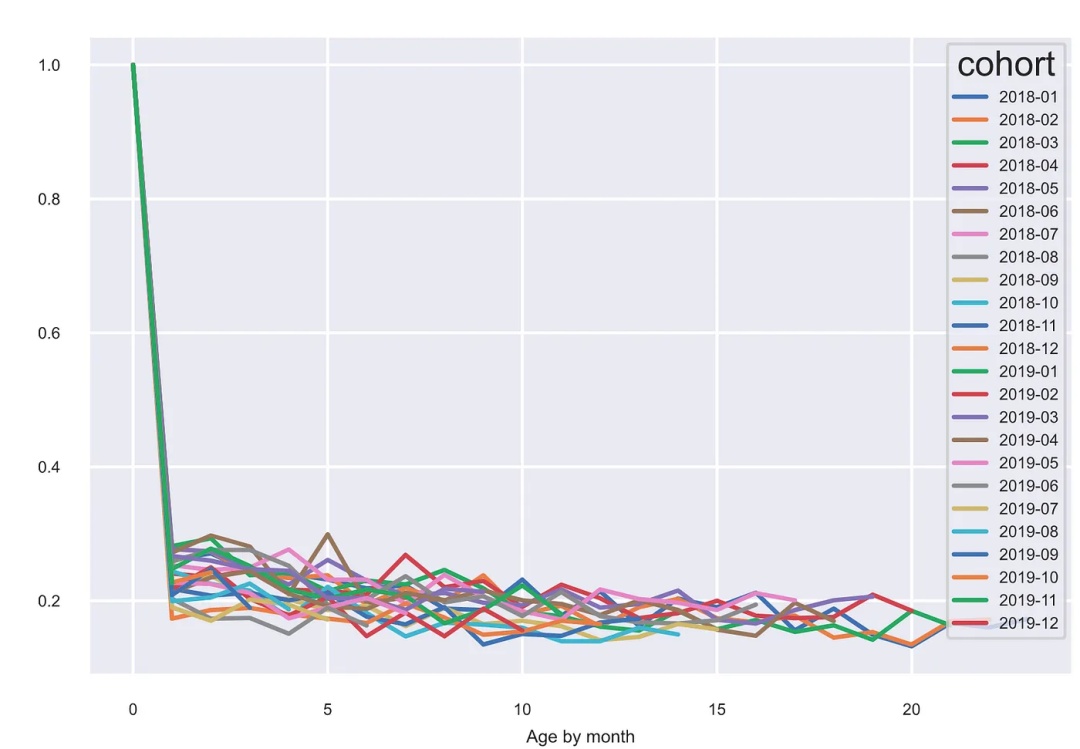
可视化
cohorts_t = cohorts.transpose()
cohorts_t[cohorts_t.columns].plot(figsize=(10,5))
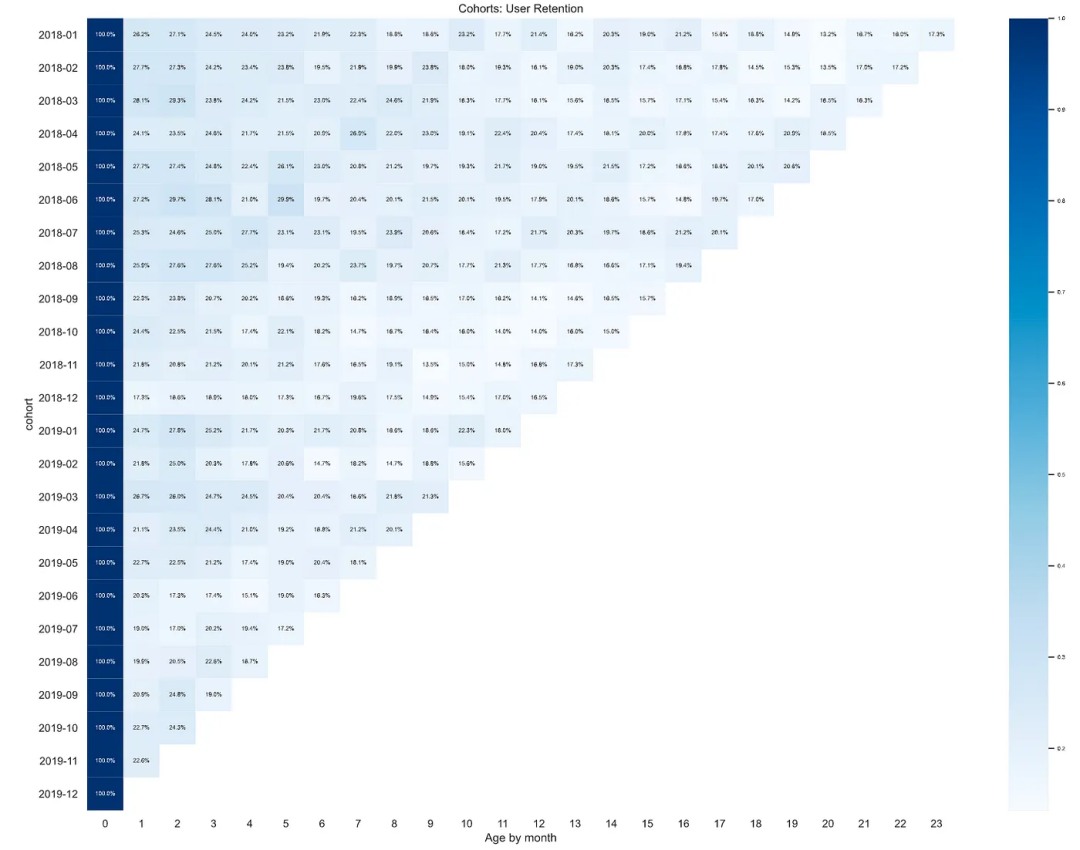
sns.set(style='whitegrid')
plt.figure(figsize=(20, 15))
plt.title('Cohorts: User Retention')
sns.set(font_scale = 0.5) # font size
sns.heatmap(cohorts, mask=cohorts.isnull(),
cmap="Blues",
annot=True, fmt='.01%')
plt.show()
到此这篇关于详解如何利用Python进行客户分群分析的文章就介绍到这了,更多相关Python客户分群分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实战实现爬取天气数据并完成可视化分析详解
1.实现需求: 从网上(随便一个网址,我爬的网址会在评论区告诉大家,dddd)获取某一年的历史天气信息,包括每天最高气温.最低气温.天气状况.风向等,完成以下功能: (1)将获取的数据信息存储到csv格式的文件中,文件命名为”城市名称.csv”,其中每行数据格式为“日期,最高温,最低温,天气,风向”: (2)在数据中增加“平均温度”一列,其中:平均温度=(最高温+最低温)/2,在同一张图中绘制两个城市一年平均气温走势折线图: (3)统计两个城市各类天气的天数,并绘制条形图进行对比,假设适合旅游的
-
使用Python对零售商品进行数据分析
目录 一.主要内容: 二.使用工具 三.数据来源 四.字段含义 五.数据清洗 1.查看总体数据特征 2.修改列名 3.检验缺失数据 4.查看并转换数据类型 5.查看异常值并删除 六.数据分析 1.总体销量数据 2.商品维度分析 3.店铺维度分析 4.销售情况分析 5.相关性分析 6.用户分析 一.主要内容: 1.清洗数据.将列名统一修改.处理缺失数据和异常数据.转换日期等数据类型 2.查看总体销售情况 3.商品维度进行分析.主要分析内容有:商品价格分析,商品销售量.销售额情况分析,商品关联分析
-
Python与AI分析时间序列数据
目录 简介 序列分析或时间序列分析的基本概念 安装实用软件包 Pandas hmmlearn PyStruct CVXOPT Pandas:处理,切片和从时间序列数据中提取统计数据 示例 处理时间序列数据 切片时间序列数据 提取来自时间序列数据的统计数据 平均值 最大值 最小值 一次性获取所有内容 重新采样 使用mean()重新采样 Re -sampling with median() 滚动平均值 通过隐马尔可夫分析顺序数据模型(HMM) 隐马尔可夫模型(HMM) 状态(S) 输出符号(O) 状
-
python中的脚本性能分析
目录 python脚本性能分析 python性能分析技巧 1.分析一行代码 2.分析多行代码 3.代码块中的每一行代码进行时间分析 python脚本性能分析 首先使用cd进入需要测试的脚本文件对应的目录,然后再使用如下代码完成对脚本的性能测试. # enter the directory of document cd (file directory) # use pdb library for debuging python -m cProfile test.py 我们可以看到我们获取到了每一步
-
Python+ChatGPT实战之进行游戏运营数据分析
目录 数据 目标 解决方案 1. DAU 2. 用户等级分布 3. 付费率 4. 收入情况 5. 付费用户的ARPU 总结 最近ChatGPT蛮火的,今天试着让ta写了一篇数据分析实战案例,大家来评价一下! 数据 您的团队已经为您提供了一些游戏数据,包括玩家的行为和收入情况.以下是数据的一些特征: user_id: 玩家ID date: 游戏日期 level: 玩家达到的游戏等级 revenue: 玩家在游戏中花费的总收入 spend: 玩家在游戏中的总支出 目标 您的目标是分析数据,以回答以下
-
详解如何利用Python绘制迷宫小游戏
目录 构思 绘制迷宫 走出迷宫 完整代码 更大的挑战 关于坐标系设置 周末在家,儿子闹着要玩游戏,让玩吧,不利于健康,不让玩吧,扛不住他折腾,于是想,不如一起搞个小游戏玩玩! 之前给他编过猜数字 和 掷骰子 游戏,现在已经没有吸引力了,就对他说:“我们来玩个迷宫游戏吧.” 果不其然,有了兴趣,于是和他一起设计实现起来,现在一起看看我们是怎么做的吧,说不定也能成为一个陪娃神器~ 先一睹为快: 构思 迷宫游戏,相对比较简单,设置好地图,然后用递归算法来寻找出口,并将过程显示出来,增强趣味性. 不如想
-
详解如何利用Python制作24点小游戏
目录 先睹为快 游戏规则(改编自维基百科) 逐步实现 Step1:制作24点生成器 Step2:定义游戏精灵类 Step3:实现游戏主循环 先睹为快 24点 游戏规则(改编自维基百科) 从1~10这十个数字中随机抽取4个数字(可重复),对这四个数运用加.减.乘.除和括号进行运算得出24.每个数字都必须使用一次,但不能重复使用. 逐步实现 Step1:制作24点生成器 既然是24点小游戏,当然要先定义一个24点游戏生成器啦.主要思路就是随机生成4个有解的数字,且范围在1~10之间,代码实现如下:
-
详解如何利用Python实现报表自动化
目录 Excel的基本组成 一份自动化报表的流程 报表自动化实战 当日各项指标的同环比情况 当日各省份创建订单量情况 最近一段时间创建订单量趋势 将不同的结果进行合并 本篇文章将带你了解报表自动化的流程,并教你用Python实现工作中的一个报表自动化实战,篇幅较长,建议先收藏,文章具体的目录为: 1.Excel的基本组成 2.一份报表自动化的流程 3.报表自动化实战 - 当日各项指标同环比情况 - 当日各省份创建订单量情况 - 最近一段时间创建订单量趋势 4.将不同的结果进行合并 - 将不同结果
-
详解如何利用Python拍摄延时摄影
目录 前言 准备 定时"拍摄" 拼接延时摄影视频 前言 这个时代,随着游戏引擎技术的快速发展,游戏画面越来越精美,许多人迷上了游戏内的角色.场景. 尤其是端游,显卡技术能够支撑精美的游戏画面,最有名的莫过于<地平线>系列游戏. 使用Python拍摄的<地平线4>延时摄影作品 很多玩家希望拍摄这些精美游戏中的画面,尤其是希望能拍摄到游戏内不同时刻的画面,为了满足这个需求,我们就需要用上延时摄影.游戏内的时间过得比现实世界更快,一个小时内可能你就能经历白天的夜晚的变
-
详解如何利用Python绘制科赫曲线
目录 1. 递归 1.1 定义 1.2 数学归纳法 2. 递归的使用方法 2.1 阶乘 2.2 字符串反转 3. 科赫曲线的绘制 3.1 概要 3.2 绘制科赫曲线 3.3 科赫曲线的雪花效果 3.4 分形几何 1. 递归 1.1 定义 函数作为一种代码封装, 可以被其他程序调用,当然,也可以被函数内部代码调用.这种函数定义中调用函数自身的方式称为递归.就像一个人站在装满镜子的房间中,看到的影像就是递归的结果.递归在数学和计算机应用上非常强大,能够非常简洁地解决重要问题. 数学上有个经典的递归例
-
Python用K-means聚类算法进行客户分群的实现
一.背景 1.项目描述 你拥有一个超市(Supermarket Mall).通过会员卡,你用有一些关于你的客户的基本数据,如客户ID,年龄,性别,年收入和消费分数. 消费分数是根据客户行为和购买数据等定义的参数分配给客户的. 问题陈述:你拥有这个商场.想要了解怎么样的顾客可以很容易地聚集在一起(目标顾客),以便可以给营销团队以灵感并相应地计划策略. 2.数据描述 字段名 描述 CustomerID 客户编号 Gender 性别 Age 年龄 Annual Income (k$) 年收入,单位为千
-
基数排序算法的原理与实现详解(Java/Go/Python/JS/C)
目录 说明 实现过程 示意图 性能分析 代码 Java Python Go JS TS C C++ 链接 说明 基数排序(RadixSort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较.由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数.基数排序的发明可以追溯到1887年赫尔曼·何乐礼在列表机(Tabulation Machine)上的 基数排序的方式可以采用LSD(Least significant di
-
详解Swift 利用Opration和OprationQueue来下载网络图片
详解Swift 利用Opration和OprationQueue来下载网络图片 1. 基于Opration封装的获取网络数据组件 import Foundation import UIKit public typealias OpreationClosure = ((_ data:Data? , _ error: Error?) -> Void) class LJOpreationManager: Operation { /** * 下载用的url */ public var imageUrl
-
详解IOS 利用storyboard修改UITextField的placeholder文字颜色
详解IOS 利用storyboard修改UITextField的placeholder文字颜色 最近有个需求需要修改UITextField的placeholder文字颜色,在网上找发现有用代码修改的,但是考虑到更加优雅的实现,所以尝试着在storyboard中直接实现,结果竟然真的成功了, 实现的位置如下: 具体步骤: 1.在User Defined Runtime Attributes中添加一个Key. 2.输入Key Path(这里我们输入_placeholderLabel.textColo
-
详解Golang 与python中的字符串反转
详解Golang 与python中的字符串反转 在go中,需要用rune来处理,因为涉及到中文或者一些字符ASCII编码大于255的. func main() { fmt.Println(reverse("Golang python")) } func reverse(src string) string { dst := []rune(src) len := len(dst) var result []rune result = make([]rune, 0) for i := le