python下载卫星云图合成gif的方法示例
Python下载中央气象台卫星云图后保存为gif并播放,大致步骤:
- 获取URL
- 下载图片
- 合成GIF
- 播放GIF
1.获取URL
1.1 先下载一份网页源码看看网页结构
保存为:response.txt
#http库
import requests
#准备http请求头
headers = {"user-agent": "firefox"}
#中央气象台卫星云图网页
url = 'http://www.nmc.cn/publish/satellite/fy2.htm'
#获取网页
r = requests.get(url, headers=headers)
#改编码方式支持中文
r.encoding='utf-8'
#保存为文本
with open('response.txt','w', encoding='utf-8') as f:
f.write(r.text)
1.2 到网页查看图片链接
右键图片---查看元素
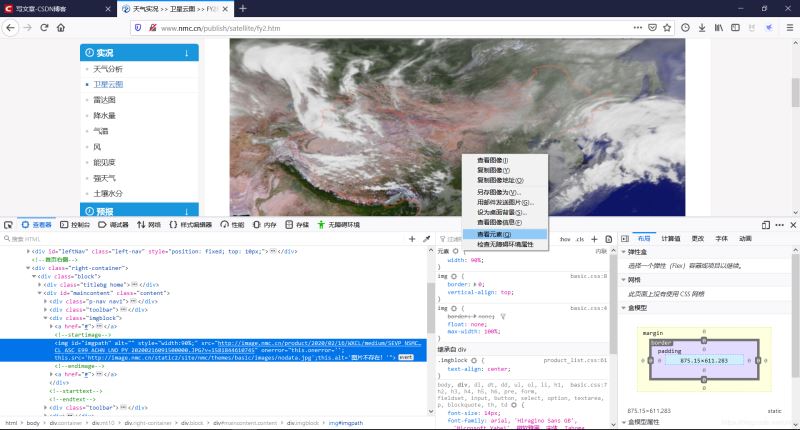
图片链接如下:可以看到图片链接的域名和网页域名不同。
src=http://image.nmc.cn/product/2020/02/16/WXCL/medium/SEVP_NSMC_WXCL_ASC_E99_ACHN_LNO_PY_20200216091500000.JPG?v=1581844610745
{kind=link}
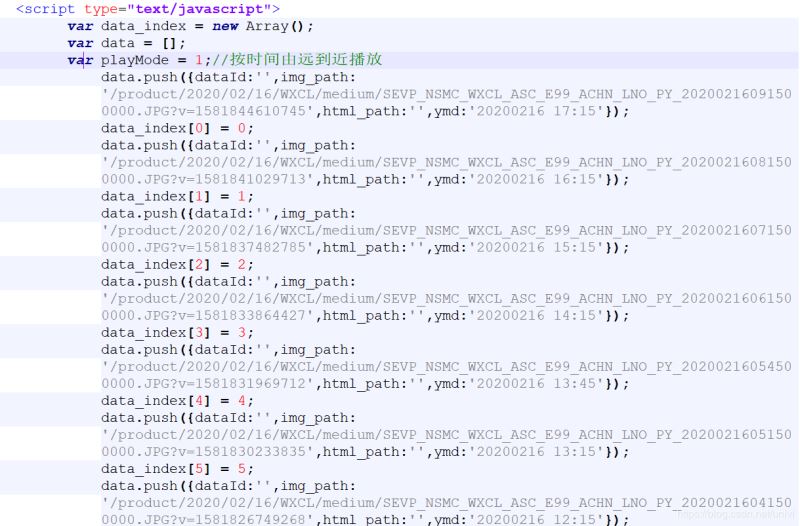
1.3 在网页码源response.txt中搜索图片名称
发现有一处列出了动画的12张图片:可以看到12张图片的链接都在script字段中。
1.4 过滤出script,找到所有url
使用html解析库解析出script,script的开头type="text/javascript"作为过滤条件,结果打印看看:
#html/xml解析库
from lxml import etree
#解析response
html = etree.HTML(r.text)
result = html.xpath('//script[@type="text/javascript"]/text()')[2]
print(result)
打印结果如下,可以看到是多行字符串。
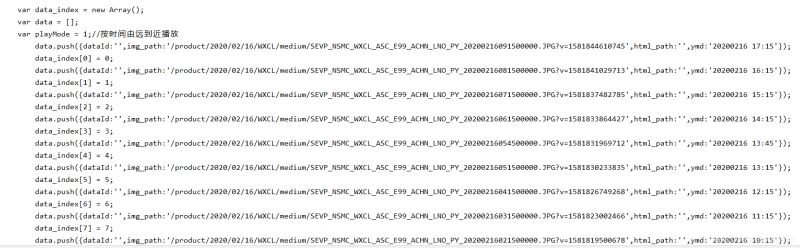
根据图片的链接规律,可以用正则匹配出来:
#正则库
import re
urls = re.findall('/product.*.JPG', result)
print(urls)
成功匹配出图片url。注意这里的url只有后半部分,根据之前的图片链接可知,实际图片url还需加上:http://image.mnc.cn。

1.5 因此写获取图片URL函数
def getpage(page):
try:
r = requests.get(page, headers=headers)
html = etree.HTML(r.text)
result = html.xpath('//script[@type="text/javascript"]/text()')[2]
urls = re.findall('/product.*.JPG', result)
return urls
except Exception as e:
print(e)
2.下载图片
拿到图片url的列表后,就是下载图片:
#url前缀
base_url = 'http://image.nmc.cn'
def dlpic(urls):
# 定义一个文件名称收集列表
filenames = []
for item in urls:
r = requests.get(base_url + item, headers)
#文件名就是用斜杠把字符串分隔,取走后后一个字符串
filename = item.split('/')[-1]
filenames.append(filename)
#保存图片
with open('wxyt_pic\\' + filename, 'wb') as f:
f.write(r.content)
print('已下载:'+item)
#返回文件名称列表,用于合成gif
return filenames
3.合成图片
# 图片操作库
import imageio
def makegif(images):
# 创建空列表,把图片明反序
frames = []
images.reverse()
# 加载12张图片
for item in images:
frames.append(imageio.imread('wxyt_pic\\'+item))
# 合成1张gif
imageio.mimsave('hecheng.gif', frames, 'GIF', duration=1)
4.播放图片
def playgif(seq=0):
if set == 0:
#播放12张合成好的gif
animation = pyglet.resource.animation('hecheng.gif')
else:
pyglet.resource.path = ['wxyt_pic']
la = os.listdir('wxyt_pic')
images = []
for n in la:
images.append(pyglet.resource.image(n))
#播放库存中的所有照片
animation = pyglet.image.Animation.from_image_sequence(images, period=0.5, loop=True)
#显示动画
sprite = pyglet.sprite.Sprite(animation)
windows = pyglet.window.Window(width=sprite.width, height=sprite.height)
@windows.event
def on_draw():
windows.clear()
sprite.draw()
pyglet.app.run()
5.整体代码
import requests
from lxml import etree
import imageio
import re
import pyglet
import os
# 在脚本同目录下,新建一个文件夹,存储当天12张图
def ckdir():
if os.path.exists('wxyt_pic') == False:
os.mkdir('wxyt_pic')
# 获取图片url列表
def getpage(page):
try:
r = requests.get(page, headers=headers)
html = etree.HTML(r.text)
result = html.xpath('//script[@type="text/javascript"]/text()')[2]
urls = re.findall('/product.*.JPG', result)
return urls
except Exception as e:
print(e)
# 下载图片
def dlpic(urls):
filenames = []
for item in urls:
r = requests.get(base_url + item, headers)
filename = item.split('/')[-1]
filenames.append(filename)
with open('wxyt_pic\\' + filename, 'wb') as f:
f.write(r.content)
print('已下载:'+item)
return filenames
# 制作gif
def makegif(images):
frames = []
images.reverse()
for item in images:
frames.append(imageio.imread('wxyt_pic\\'+item))
imageio.mimsave('hecheng.gif', frames, 'GIF', duration=1)
# 播放gif
def playgif(seq=0):
if set == 0:
#播放12张合成好的gif
animation = pyglet.resource.animation('hecheng.gif')
else:
pyglet.resource.path = ['wxyt_pic']
la = os.listdir('wxyt_pic')
images = []
for n in la:
images.append(pyglet.resource.image(n))
#播放库存中的所有照片
animation = pyglet.image.Animation.from_image_sequence(images, period=0.5, loop=True)
#显示动画
sprite = pyglet.sprite.Sprite(animation)
windows = pyglet.window.Window(width=sprite.width, height=sprite.height)
@windows.event
def on_draw():
windows.clear()
sprite.draw()
pyglet.app.run()
# init
if __name__ == '__main__':
base_url = 'http://image.nmc.cn'
page = 'http://www.nmc.cn/publish/satellite/fy2.htm'
headers = {"user-agent": "firefox"}
ckdir()
urls = getpage(page)
images = dlpic(urls)
makegif(images)
# 0只播放今天12张,1播放库存里所有照片
playgif(1)
6.最终效果

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python图像处理之gif动态图的解析与合成操作详解
本文实例讲述了Python图像处理之gif动态图的解析与合成操作.分享给大家供大家参考,具体如下: gif动态图是在现在已经司空见惯,朋友圈里也经常是一言不合就斗图.这里,就介绍下如何使用python来解析和生成gif图像. 一.gif动态图的合成 如下图,是一个gif动态图. gif动态图的解析可以使用PIL图像模块即可,具体代码如下: #-*- coding: UTF-8 -*- import os from PIL import Image def analyseImage(path):
-
python下载卫星云图合成gif的方法示例
Python下载中央气象台卫星云图后保存为gif并播放,大致步骤: 获取URL 下载图片 合成GIF 播放GIF 1.获取URL 1.1 先下载一份网页源码看看网页结构 保存为:response.txt #http库 import requests #准备http请求头 headers = {"user-agent": "firefox"} #中央气象台卫星云图网页 url = 'http://www.nmc.cn/publish/satellite/fy2.htm
-
Python更改pip镜像源的方法示例
问:为何要更改pip镜像源? 答:因为默认使用的镜像源是https://pypi.org/,国内访问的时候是其慢无比,特别是有时紧急安装库的时候:这时候我们就可以换成国内的镜像源网站,来提升下载的速度,以获得更好的编写代码体验 具体操作流程: 1.使用Win键(也就是键盘上那个Windows图标键)+ R键打开运行窗口 2.输入英文下的点(.)或者使用命令:%USERPROFILE% 3.入到用户家目录后,点击鼠标右键新建一个名为pip的文件 4.进入这个新建的pip文件:然后创建一个名为pip
-
python 下载文件的几种方法汇总
前言 使用脚本进行下载的需求很常见,可以是常规文件.web页面.Amazon S3和其他资源.Python 提供了很多模块从 web 下载文件.下面介绍 一.使用 requests requests 模块是模仿网页请求的形式从一个URL下载文件 示例代码: import requests url = 'xxxxxxxx' # 目标下载链接 r = requests.get(url) # 发送请求 # 保存 with open ('r.txt', 'rb') as f: f.write(r.con
-
python同时替换多个字符串方法示例
本文介绍了python同时替换多个字符串方法示例,分享给大家,具体如下: import re words = ''' 钟声响起归家的讯号 在他生命里 仿佛带点唏嘘 黑色肌肤给他的意义 是一生奉献 肤色斗争中 年月把拥有变做失去 疲倦的双眼带着期望 今天只有残留的躯壳 迎接光辉岁月 风雨中抱紧自由 一生经过彷徨的挣扎 自信可改变未来 问谁又能做到 可否不分肤色的界限 愿这土地里 不分你我高低 缤纷色彩闪出的美丽 是因它没有 分开每种色彩 年月把拥有变做失去 疲倦的双眼带着期望 今天只有残留的躯壳
-
Python OpenCV读取显示视频的方法示例
目标 学习读取视频,显示视频和保存视频. 学习从相机捕捉并显示它. 你将学习以下功能:cv.VideoCapture(),cv.VideoWriter() 从相机中读取视频 通常情况下,我们必须用摄像机捕捉实时画面.提供了一个非常简单的界面.让我们从摄像头捕捉一段视频(我使用的是我笔记本电脑内置的网络摄像头) ,将其转换成灰度视频并显示出来.只是一个简单的任务开始. 要捕获视频,你需要创建一个 VideoCapture 对象.它的参数可以是设备索引或视频文件的名称.设备索引就是指定哪个摄像头的数
-
使用python脚本自动生成K8S-YAML的方法示例
1.生成 servie.yaml 1.1.yaml转json service模板yaml apiVersion: v1 kind: Service metadata: name: ${jarName} labels: name: ${jarName} version: v1 spec: ports: - port: ${port} targetPort: ${port} selector: name: ${jarName} 转成json的结构 { "apiVersion": "
-
python自动生成证件号的方法示例
前言 在跟进需求的时候,往往涉及到测试,特别是需要用到身份信息的时候,总绕不开身份证号码这个话题.之前在跟一个互联网产品的时候,需要很多身份证做测试,又不想装太多软件自动生成(有需要的小伙伴可自行搜索身份证号码自动生成软件),按照身份证规则现编也比较浪费时间,在处理身份数据时,Python就非常有用了. 方法示例如下 # Author:BeeLe # -*-coding:utf-8-*- # 生成身份证号码主程序 import urllib.request import requests fro
-
20行代码教你用python给证件照换底色的方法示例
1.图片来源 该图片来源于百度图片,如果侵权,请联系我删除!图片仅用于知识交流. 2.读取图片并显示 imread():读取图片: imshow():展示图片: waitkey():设置窗口等待,如果不设置,窗口会一闪而过: import cv2 import numpy as np # 读取照片 img=cv2.imread('girl.jpg') # 显示图像 cv2.imshow('img',img) # 窗口等待的命令,0表示无限等待 cv2.waitKey(0) 效果如下: 3.图片缩
-
三行代码使用Python将视频转Gif的方法示例
目录 一.前言 二.教程 1. 安装必备库moviepy 2. 写入代码 3. 转换效果 4. GIF很大的解决方案 5. 截取视频长度转换 5. 指定转换后的图片大小(分辨率) 一.前言 很多网站提供视频转GIF的功能,但要么收费要么有广告 实际上我们通过python,几行代码就能够实现视频转gif 二.教程 1. 安装必备库moviepy pip install moviepy -i https://pypi.tuna.tsinghua.edu.cn/simple 2. 写入代码 from
-
Python如何获取实时股票信息的方法示例
如何获取实时股票信息 股票信息的接口有很多,之前大家常用的是新浪的,但在年初的时候,新浪的接口突然不能使用,给大家造成了很大的困扰,为此网上也有很多教程教大家如何从新浪获取数据,跟着教程弄了半天也不行,索性换到126(也就是网易了),感觉速度都还不错. 首先我们看下接口地址:http://api.money.126.net/data/feed/1000001,money.api 其中的1000001就是股票代码了,跟新浪的不同,他的第一位代表交易所,后面6位是股票代码 0:上交所 1:深交所 2