mysql实现合并结果集并去除重复值
目录
- mysql 合并结果集并去除重复值
- mysql 合并结果集(union,union all)
- union 与 union all 执行结果不同
- 对UNION,UNION ALL的结果继续处理,需要加括号
- mysql中,UNION,UNION ALL的性能/效率不同
- 总结
mysql 合并结果集并去除重复值
SELECT DISTINCT c.parent_id from ( SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id UNION ALL SELECT cat_id FROM tp_goods GROUP BY cat_id ) c;
先去除每个结果集中的重复值 以 group by 方式除去
SELECT parent_id FROM tp_goods_category a join tp_goods g on a.id = g.cat_id GROUP BY parent_id SELECT cat_id FROM tp_goods GROUP BY cat_id
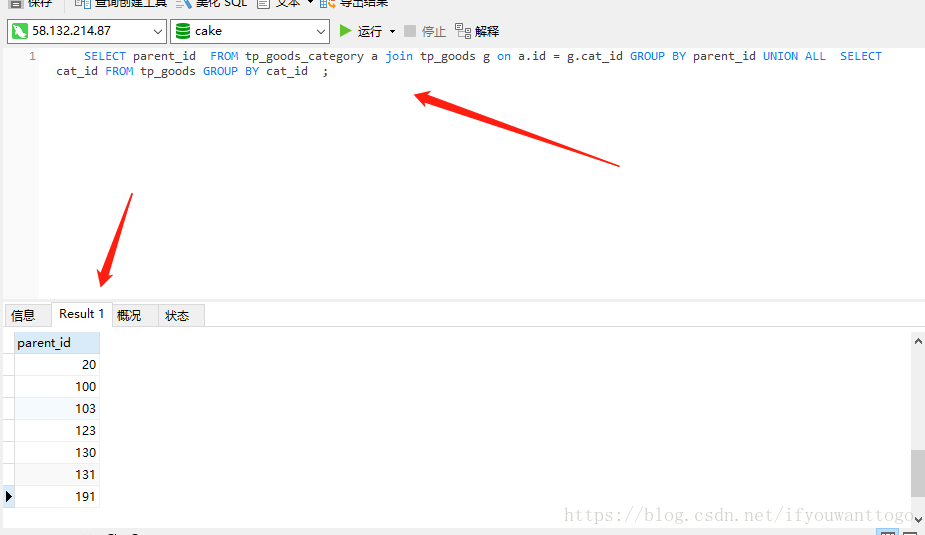
然后合并两个结果集 生成一个新的结果集 (或者可以成为新表) 在 使用DISTINCT 去除合并结果集中的重复值 注意 必须给 新结果集取一个别名 比如例子中的 c

新的查询结果

此语句为了删除分类表中 在goods表中不存在的 分类id 且 级别为第二级别

mysql 合并结果集(union,union all)
我需要在一个sql的执行结果中,显示两个或两个以上的where条件的结果(select 列的结构相同)。
考虑使用union,或union all 。
union 与 union all 执行结果不同
UNION 删除重复的记录再返回结果,即对整个结果集合使用了DISTINCT。结果中无重复数据。
UNION ALL 将各个结果合并后就返回,不删除重复记录。如果结果中有重复数据,则包含重复数据。
例如,
mysql> SELECT * FROM world.city where ID=2020 UNION SELECT * FROM world.city where ID=2020; +------+-------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+--------------+------------+ | 2020 | Tieli | CHN | Heilongjiang | 265683 | +------+-------+-------------+--------------+------------+ 1 row in set (0.00 sec) mysql> SELECT * FROM world.city where ID=2020 UNION ALL SELECT * FROM world.city where ID=2020; +------+-------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+--------------+------------+ | 2020 | Tieli | CHN | Heilongjiang | 265683 | | 2020 | Tieli | CHN | Heilongjiang | 265683 | +------+-------+-------------+--------------+------------+ 2 rows in set (0.00 sec)
对UNION,UNION ALL的结果继续处理,需要加括号
比如要对合并后的结果集进行ORDER BY,LIMIT等操作需要对合并对象单个的SELECT语句加上括号。
并且把整体结果的条件ORDER BY,LIMIT等放到最后一个SELECT的括号后面。
例如,
(SELECT * FROM world.city WHERE CountryCode = 'JPN' AND Name LIKE 'nishi%') UNION ALL (SELECT * FROM world.city WHERE CountryCode = 'CHN' AND Population >= 5000000) LIMIT 5;
mysql中,UNION,UNION ALL的性能/效率不同
从效率上说,UNION ALL 要比UNION快很多。
所以,如果可以确认合并的结果集中不包含重复的数据的话,或者需要的结果中即使包含重复也无所谓,那么就使用UNION ALL。
UNION
- UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算。
- UNION在运行时先取出各个表/各个select的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
UNION ALL
- UNION ALL只是简单的将结果合并后就返回。不涉及排序运算。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
MySQL中查询、删除重复记录的方法大全
前言 本文主要给大家介绍了关于MySQL中查询.删除重复记录的方法,分享出来供大家参考学习,下面来看看详细的介绍: 查找所有重复标题的记录: select title,count(*) as count from user_table group by title having count>1; SELECT * FROM t_info a WHERE ((SELECT COUNT(*) FROM t_info WHERE Title = a.Title) > 1) ORDER BY Titl
-

mysql优化小技巧之去除重复项实现方法分析【百万级数据】
本文实例讲述了mysql优化小技巧之去除重复项实现方法.分享给大家供大家参考,具体如下: 说到这个去重,脑仁不禁得一疼,尤其是出具量比较大的时候.毕竟咱不是专业的DB,所以嘞,只能自己弄一下适合自己去重方法了. 首先按照常规首段,使用having函数检查重复项,完事一个一个的删除.不要问我having检测重复项的sql咋写,你懂得哈...这个在只有几条重复的时候还可以.要是几千上万条不同数据重复,那咋办... 完事呢,咱就考虑了,用having函数查询的时候,原始sql如下: select `n
-
MySQL 去除重复数据实例详解
MySQL 去除重复数据实例详解 有两个意义上的重复记录,一是完全重复的记录,也即所有字段均都重复,二是部分字段重复的记录.对于第一种重复,比较容易解决,只需在查询语句中使用distinct关键字去重,几乎所有数据库系统都支持distinct操作.发生这种重复的原因主要是表设计不周,通过给表增加主键或唯一索引列即可避免. select distinct * from t; 对于第二类重复问题,通常要求查询出重复记录中的任一条记录.假设表t有id,name,address三个字段,id是主键,有重
-
mysql实现合并结果集并去除重复值
目录 mysql 合并结果集并去除重复值 mysql 合并结果集(union,union all) union 与 union all 执行结果不同 对UNION,UNION ALL的结果继续处理,需要加括号 mysql中,UNION,UNION ALL的性能/效率不同 总结 mysql 合并结果集并去除重复值 SELECT DISTINCT c.parent_id from ( SELECT parent_id FROM tp_goods_category a join tp_goo
-
pandas去除重复值的实战
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
字符串聚合函数(去除重复值)
--功能:提供字符串的替代聚合函数 --说明:例如,将下列数据 --test_id test_value -------------------- 'a' '01,03,04' 'a' '02,04' 'b' '03,04,08' 'b' '06,08,09' 'c' '09' 'c' '10' --转换成test_vlaue列聚合后的函数,且聚合后的字符串中的值不重复 --test_id test_value -------------------- 'a' '01,03,04,02' 'b'
-
hashset去除重复值原理实例解析
Java中的set是一个不包含重复元素的集合,确切地说,是不包含e1.equals(e2)的元素对.Set中允许添加null.Set不能保证集合里元素的顺序. 在往set中添加元素时,如果指定元素不存在,则添加成功.也就是说,如果set中不存在(e==null?e1==null:e.queals(e1))的元素e1,则e1能添加到set中. 下面以set的一个实现类HashSet为例,简单介绍一下set不重复实现的原理: package com.darren.test.overide; publ
-
js数组中去除重复值的几种方法
在日常开发中,我们可能会遇到将一个数组中里面的重复值去除,那么,我就将我自己所学习到的几种方法分享出来 去除数组重复值方法: 1,利用indexOf()方法去除 思路:创建一个新数组,然后循环要去重的数组,然后用新数组去找要去重数组的值,如果找不到则使用.push添加到新数组,最后把新数组返回回去就行了 看不懂没关系,上代码就比较容易懂了 function fun(arr){ let newsArr = []; for (let i = 0; i < arr.length; i++) { if(
-
awk实现Left、join查询、去除重复值以及局部变量讲解例子
最近看到论坛里面有几个不错的小例子,对于学习awk还是有帮助,在这儿详细的说一下 一.类似数据库中的left join查询 复制代码 代码如下: [root@krlcgcms01 mytest]# cat a.txt //a.txt 111 aaa 222 bbb 333 cccc 444 ddd [root@krlcgcms01 mytest]# cat b.txt //b.txt 111 123 456 2 abc cbd 444 rts 786
-
详解JavaScript数组和字符串中去除重复值的方法
原理在代码中表现得非常清晰,我们直接来看代码例子: var ages = array.map(function(obj) { return obj.age; }); ages = ages.filter(function(v,i) { return ages.indexOf(v) == i; }); console.log(ages); //=> [17, 35] function isBigEnough(element) { return element >= 10; } var filte
-
MySQL中distinct语句去查询重复记录及相关的性能讨论
在 MySQL 查询中,可能会包含重复值.这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值. 关键词 DISTINCT 用于返回唯一不同的值,就是去重啦.用法也很简单: SELECT DISTINCT * FROM tableName DISTINCT 这个关键字来过滤掉多余的重复记录只保留一条. 另外,如果要对某个字段去重,可以试下: SELECT *, COUNT(DISTINCT nowamagic) FROM table GROUP BY nowamagic 这个用
-
Python教程pandas数据分析去重复值
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs