oracle 数据库数据迁移解决方案
去年年底做了不少系统的数据迁移,大部分系统由于平台和版本的原因,做的是逻辑迁移,少部分做的是物理迁移,有一些心得体会,与大家分享。
首先说说迁移流程,在迁移之前,写好方案,特别是实施的方案步骤一定要写清楚,然后进行完整的测试。我们在迁移时,有的系统测试了四五次,通过测试来完善方案和流程。
针对物理迁移,也即通过RMAN备份来进行还原并应用归档的方式(这里不讨论通过dd方式进行的冷迁移),虽然注意的是要将数据库设为force logging的方式,在用RMAN做全备之前,一定要执行:
否则可能会产生坏块。
对于逻辑迁移,在job_processes设置为>0的数值之前,注意job的下次执行时间和job所属用户。比如job的定义在之前已经导入,但是在迁移之时,job已经运行过,那么迁移完成之后,job的下次时间还是原来的时间,这样可能会重复运行。另外,job通过IMP导入后,job所属用户会变成导入用户的名称,显然job原来的用户就不能对JOB进行管理了,可以通过下面的sql进行修改:
在迁移之前,应该禁止对系统进行结构上的修改和发布,比如表结构,索引,存储过程包等。
如果是用exp/imp导入的对象,包括存储过程等,应该检查对象是否与原生产库一致,比如由于dblink的原因,imp之后,存储过程不能创建,导致有部分存储过程丢失,尽管这些存储过程可能没有被使用。
下面是一些加快迁移速度的技巧:
通过dblink,使用append insert的方式,同时利用并行,这种方式比exp/imp更快
对于有LONG类型的列,insert..select的方式显然是不行的,可以通过exp/imp的方式,但是这种方式速度非常慢,其原因在于imp时一行一行地插入表。有另外一种方式,即sqlplus的copy命令,下面是一个示例:
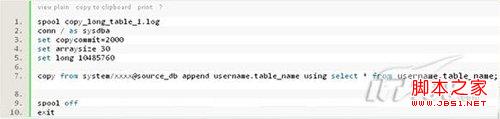
不过,sqlpus的copy命令不支持有timestamp和lob列类型的表。如果有timestamp类型的表,可以通过在exp时,加上rowid的条件,将一个表分成多个部分同时操作,对于有lob类型的表,也可以同样处理(因为insert …select方式下,有lob类型列时,也同样是一行一行地插入)。注意在这种方式下,就不能使用direct的方式exp/imp。下面是exp导出时parfile示例:
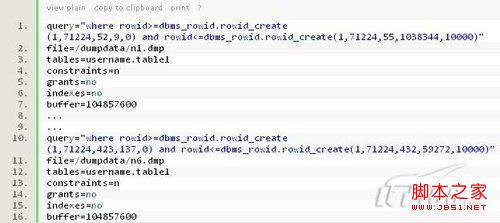
将表分成几部分同时操作,不仅仅可以利用rowid,也可以利用表上的列,比如说,表上有一个created_date的列,并且保证是递增插入数据,那么这种情况下,也可以使用这个字段将表分成不同的范围同时进行导出和导入。不过使用ROWID通常具有更高的效率。
当然对于有lob列的表,可以按上述方式,拆成多个insert方式同时插入,不需要exp/imp。
·对于特别大的分区表,虽然使用并行可以提高速度,但是受限于单个进程(不能跨DB LINK进行并行事务,只能并行查询,也即insert..select只能是SELECT部分才能进行并行)的处理能力,这种方式下速度仍然有限。可以并行将数据插入多个中间表,然后通过exchange partition without validation 的方式,交换分区,这种方式将会大大提高了速度。
·有朋友可能会问,为什么不并行直接插入分区表,当然如果是非direct path(append)方式,则是没问题的,但是这种方式插入的性能较低。而direct path的方式,会在表上持有mode=6(互斥)的TM锁,不能多个会话同时插入。(update: 在insert 时使用这样的语句:insert into tablename partition (partname) select * from tablename where ….,更简单更有效率。)
·迁移时,将数据分成两部分,一部分是历史表,第二部分是动态变化的表,在迁移之前,先导入历史表,并在历史表上建好索引,这无疑会大大减少迁移时业务系统中断时间。
·迁移之前,考虑清理掉垃圾数据。
·迁移时,应保证表上没有任何索引,约束(NOT NULL除外)和触发器,数据导入完成后,再建索引。建索引时同样,同时使用多个进程跑脚本。索引创建无成后,应去掉索引的PARALLEL属性
·在创建约束时,应按先创建CHECK约束,主键,唯一键,再创建外键约束的顺序。约束状态为 ENABLE NOVALIDATE,这将大大减少约束创建时间。而在迁移完成后,再考虑设回为ENABLE VALIDATE。
·通过使用dbms_stats.export_schame_stats和dbms_stats.import_schame_stats导入原库上的统计信息,而不用重新收集统计使用。
朋友们可以看到,以上均是针对9i的,实际上在10g甚至11g环境下,也仍然很多借鉴意义。当然这些技巧不仅仅用于完整的数据库迁移,也可以应用到将个别表复制到其他数据库上。
这里没有提到的是利用物化视图或高级复制、触发器之类的技术,因为这些技术,毕竟要修改生产库,对生产库的运行有比较大的影响,因此,只有在停机时间要求特别严格,而在这个时间内又不能完成迁移时才应该考虑。
从迁移的经验来说,只有完善的流程,完整的测试才可以保证成功。这里只是列举了一些小技巧,如果对整个迁移过程有兴趣,可以针对这个话题再进行讨论。
相关推荐
-
oracle数据迁移到db2数据库的实现方法(分享)
1.表结构迁移 在plsql中选择表----->dbmsMetadata----->ddl 注意:这时表的创建.约束等信息将会显示在窗口中.可以将创建表的语句直接拷贝值sqldbx(连接db2数据库的工具)中修改字段的类型,如varchar2转化为varchar,number转化为integer.还有primary key.unique的变化. 2.表数据迁移 在Plsql中选择表------>右键------>qurey data(显示出所有数据)---->选择需要迁移的数
-
DB2数据库切换为oracle数据库经验教训总结(必看篇)
由于DB2数据库使用的人太少,公司有没有专业的DBA,决定把数据库从DB2数据库切换为oracle数据库,本以为很简单,可当真的切换时,却发现,有很多东西出乎意料. 由于系统底层使用的是ORM映射工具,由于没有使用存储过程,自定义函数,触发器,因此我以为系统改动不大,但发现的问题却不少. 1.我们的主键基本上都采用共的是Sequence,没有采用自动增长作为主键. 但获取Sequence在两种数据库中是不相同的. DB2获取的方法 values next value for eas.seq_Se
-

mysql数据库迁移至Oracle数据库
本文实例为大家分享了java获取不同路径的方法,供大家参考,具体内容如下 1.使用工具: (1) Navicat Premium (2) PL/SQL Developer 11.0 (3) Oracle SQL Developer 4.0.0.12.84(点击可进入下载页面) 特别说明:最初我用的一直是高版本的SQL Developer,但在数据库移植到大概两分钟的时候,总是报错,而错误信息又不明确.最后换成 Oracle SQL Developer 4.0.0.12.84,才把问题解决掉!如果
-
Oracle数据库迁移方案
1 在数据迁移时,用户首先有权限修改数据库,并且进行表空间创建.删除等权利 例如: select * from dba_tab_privs where grantee='SCOT'; ---查看SCOTT权限(sys用户登录) 显示结果为: select * from dba_role_privs where grantee='SCOT'; --查看SCOTT角色 显示结果为: (1) 如果用户被锁定通过以下语句来解锁表 alter user scott account unlock; --解锁
-
oracle 数据库数据迁移解决方案
去年年底做了不少系统的数据迁移,大部分系统由于平台和版本的原因,做的是逻辑迁移,少部分做的是物理迁移,有一些心得体会,与大家分享. 首先说说迁移流程,在迁移之前,写好方案,特别是实施的方案步骤一定要写清楚,然后进行完整的测试.我们在迁移时,有的系统测试了四五次,通过测试来完善方案和流程. 针对物理迁移,也即通过RMAN备份来进行还原并应用归档的方式(这里不讨论通过dd方式进行的冷迁移),虽然注意的是要将数据库设为force logging的方式,在用RMAN做全备之前,一定要执行: 否则可能会产
-
解决mysql数据库数据迁移达梦数据乱码问题
受到领导的嘱托,接手了一个java项目,要进行重构,同时了项目的整体建设要满足信创的要求. 那么首先就要满足两点: 1,使用国产数据库达梦8替换mysql数据库 2,使用金蝶中间件替换tomcat进行容器部署 在不懈的努力下,我已在本地的搭建和安装完成达梦8(dm8)数据库,也完成了代码框架更改数据库源,替换达梦数据库的demo验证工作. driverClassName: dm.jdbc.driver.DmDriver url: jdbc:dm://10.0.3.132:5236/XC-SERV
-
浅谈入门级oracle数据库数据导入导出步骤
oracle数据库数据导入导出步骤(入门) 说明: 1.数据库数据导入导出方法有多种,可以通过exp/imp命令导入导出,也可以用第三方工具导出,如:PLSQL 2.如果熟悉命令,建议用exp/imp命令导入导出,避免第三方工具版本差异引起的问题,同时效率更高,但特别注意:采用命令时要注意所使用的用户及其权限等细节. 3.在目标数据库导入时需要创建与导出时相同的用户名(尽量一致),并赋予不低于导出时用户的权限:同时还需创建与原数据库相同的表空间名,若本地数据库已存在相同的表空间,则只能进行表空间
-
SpringBoot Mybatis批量插入Oracle数据库数据
目录 前端数据 数据表结构 后端Controller: mapper xml 前端数据 有如下需求,前端提交一个对象cabinData,保存到数据表中,对象结构如下: { "shipId":"424", "shipName":"大唐2号", "ballastCabinData":["艏尖舱","双层底1左","双层底1右&qu
-
通过LogMiner实现Oracle数据库同步迁移
目录 通过LogMiner实现Oracle数据同步迁移 一.实现过程 1.创建目录 2.配置LogMiner 3.开启日志追加模式 4.重启数据库 5.创建数据同步用户 6.创建数据字典 7.加入需要分析的日志文件 8.查看正在使用的日志文件 9.使用Lominer分析日志 10.查看分析结果 11.常见问题 通过LogMiner实现Oracle数据同步迁移 为了实现Oracle数据库之间的数据同步,网上的资料比较少的时候.最好用的Oracle数据库同步工具是:GoldenGate ,而Gold
-
浅谈Ruby on Rails下的rake与数据库数据迁移操作
不知道你有没有把数据迁移写入Migration文件的经历,相信无论是老鸟还是新手都这样干过吧.事实上,这样做并不是行不通,只不过这样的实践慢慢会给你引入一些不必要的麻烦. 一般认为db/migrate文件夹里的内容是关于你数据库Schema的演变过程,每个新的开发或线上环境都要通过这些Migration来构建可用的数据库.但如果这里装入了,负责细节的业务代码,比如一些历史遗留数据的迁移代码之类的,当一段时间后,数据库的结构变化了,但Migration没有跟着变化,渐渐的曾经的辅助代码,就成了垃圾
-
简析Oracle数据库常见问题及解决方案
Oracle数据库在使用的过程中常常会遇到这样或那样的问题,而这些问题常常又使我们感到很困惑,本文我们总结了Oracle数据库在使用过程中的一些问题,并给出了解决方法,下面我们就开始分析一下这些问题. 一.oracle监听启动后,立即停止. TNS-12545: 因目标主机或对象不存在,连接失败. TNS-12560: TNS: 协议适配器错误. TNS-00515: 因目标主机或对象不存在,连接失败. 32-bit Windows Error: 1004: Unknown error. 不再监
-
MySQL数据迁移相关总结
前言: 在平时工作中,经常会遇到数据迁移的需求,比如要迁移某个表.某个库或某个实例.根据不同的需求可能要采取不同的迁移方案,数据迁移过程中也可能会遇到各种大小问题.本篇文章,我们一起来看下 MySQL 数据迁移那些事儿,希望能帮助到各位. 1.关于数据迁移 首先引用下维基百科中对数据迁移的解释: 数据迁移(data migration)是指选择.准备.提取和转换数据,并将数据从一个计算机存储系统永久地传输到另一个计算机存储系统的过程.此外,验证迁移数据的完整性和退役原来旧的数据存储,也被认为是整
-
Oracle数据库升级或数据迁移方法研究
一.数据库升级的必要性 数据库升级是数据库管理员经常要面对的问题,如果你的应用要使用新版本数据库的新特性:如果数据库运行负载过重,而通过软硬件调整又不能有根本性的改善:如果要更换操作系统平台:如果要增强数据库的安全性:还有一个原因是随着新版本数据库的出现与成熟,oracle停止了对旧版本数据库的技术支持,升级到高版本,可以继续获得oracle的支持,还可以利用新版本数据库的新特新,可以改善系统的性能,健壮性,可扩张性和可用性,等等,面对这些问题,需要通过数据库升级才得以解决.不过,如果你的系统运